This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
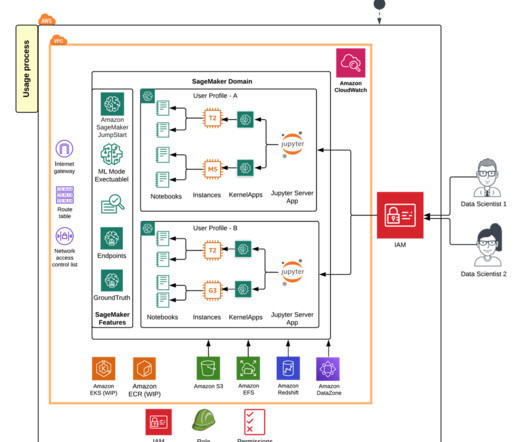
Solution overview The following diagram illustrates the ML platform reference architecture using various AWS services. The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , Amazon SageMaker , AWS DevOps services, and a data lake.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Hear also from Adidas, GlobalFoundries, and University of California, Irvine.
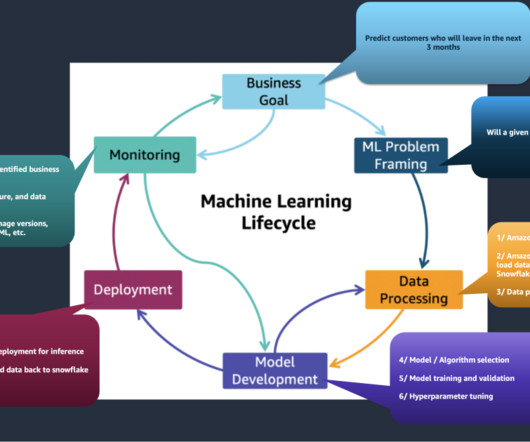
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
It allows datascientists to build models that can automate specific tasks. SageMaker boosts machine learning model development with the power of AWS, including scalable computing, storage, networking, and pricing. AWS SageMaker also has a CLI for model creation and management.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
This article was published as a part of the Data Science Blogathon. Introduction Are you a Data Science enthusiast or already a DataScientist who is trying to make his or her portfolio strong by adding a good amount of hands-on projects to your resume? But have no clue where to get the datasets from so […].
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can also find Tecton at AWS re:Invent. This process is shown in the following diagram.
For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. Streamlined Collaboration Among Teams Data Warehouse Systems in the cloud often involve cross-functional teams — dataengineers, datascientists, and system administrators.
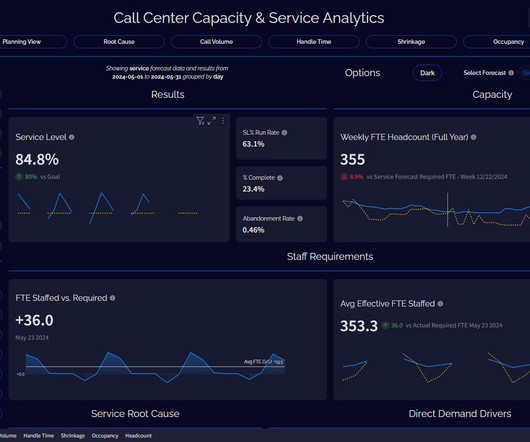
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. About the Author Xiong Zhou is a Senior Applied Scientist at AWS. See Amazon SageMaker geospatial capabilities to learn more.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. These include dbt pipelines, data gathering jobs, training, evaluation, and batch inference jobs for smaller models.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly.
SambaSafety’s team of datascientists has developed complex and propriety modeling solutions designed to accurately quantify this risk profile. SambaSafety worked with AWS Advanced Consulting Partner Firemind to deliver a solution that used AWS CodeStar , AWS Step Functions , and Amazon SageMaker for this workload.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Dataengineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. Choose Create VPC.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
To address this challenge, AWS introduced Amazon SageMaker Role Manager in December 2022. Today, we are launching the ability to define customized permissions in minutes with SageMaker Role Manager via the AWS Cloud Development Kit (AWS CDK). Set up your AWS CDK development environment.
Unfolding the difference between dataengineer, datascientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Big data platforms such as Apache Hadoop and Spark help handle massive datasets efficiently. Together, these tools enable DataScientists to tackle a broad spectrum of challenges. Typical Applications in Industries Data Science finds applications across industries. DataScientists require a robust technical foundation.
The recently published IDC MarketScape: Asia/Pacific (Excluding Japan) AI Life-Cycle Software Tools and Platforms 2022 Vendor Assessment positions AWS in the Leaders category. The tools are typically used by datascientists and ML developers from experimentation to production deployment of AI and ML solutions. AWS position.
Furthermore, the democratization of AI and ML through AWS and AWS Partner solutions is accelerating its adoption across all industries. For example, a health-tech company may be looking to improve patient care by predicting the probability that an elderly patient may become hospitalized by analyzing both clinical and non-clinical data.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Their task is to construct and oversee efficient data pipelines.
The role of a datascientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 datascientist job descriptions from that past year to find out what employers are looking for in 2023. Data Science Of course, a datascientist should know data science!
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a datascientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a datascientist.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
In addition to dataengineers and datascientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Data science and dataengineering are incredibly resource intensive. By using cloud computing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
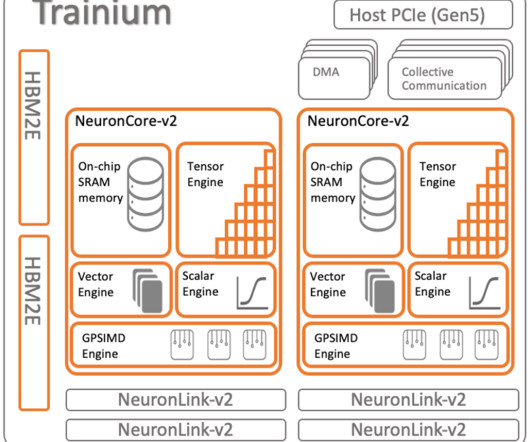
AWS Trainium and AWS Inferentia2 , which are purpose built for DL training and inference, extend their functionality and performance by supporting custom operators (or CustomOps, for short). AWS Neuron , the SDK that supports these accelerators, uses the standard PyTorch interface for CustomOps.
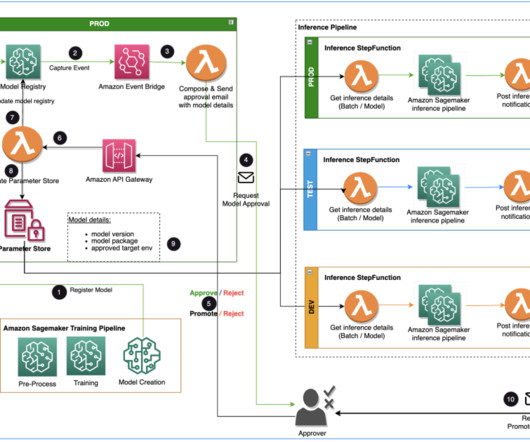
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. In this post, we discuss how the AWS AI/ML team collaborated with the Merck Human Health IT MLOps team to build a solution that uses an automated workflow for ML model approval and promotion with human intervention in the middle.
The first is by using low-code or no-code ML services such as Amazon SageMaker Canvas , Amazon SageMaker Data Wrangler , Amazon SageMaker Autopilot , and Amazon SageMaker JumpStart to help data analysts prepare data, build models, and generate predictions. We recognize that customers have different starting points.
Seamless integration with SageMaker – As a built-in feature of the SageMaker platform, the EMR Serverless integration provides a unified and intuitive experience for datascientists and engineers. This flexibility helps optimize performance and minimize the risk of bottlenecks or resource constraints.
However, working with data in the cloud can present challenges, such as the need to remove organizational data silos, maintain security and compliance, and reduce complexity by standardizing tooling. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. About the Authors.
Snowflake Summit 2024 launched numerous features and enhancements targeted at datascientists’ workflows and developer experience. By adopting more of Snowflake’s functionality for data science, organizations have an opportunity to greatly accelerate AI/ML application development. You might use one every single day.
Faced with manual dubbing challenges and prohibitive costs, MagellanTV sought out AWS Premier Tier Partner Mission Cloud for an innovative solution. In the backend, AWS Step Functions orchestrates the preceding steps as a pipeline. Each step is run on AWS Lambda or AWS Batch. She received her Ph.D. After earning his Ph.D.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
We explain how to build and deploy the image on AWS using continuous integration and delivery (CI/CD) tools and how to make the deployed image accessible in SageMaker Studio. CodeBuild supports a broad selection of git version control sources like AWS CodeCommit , GitHub, and GitLab.
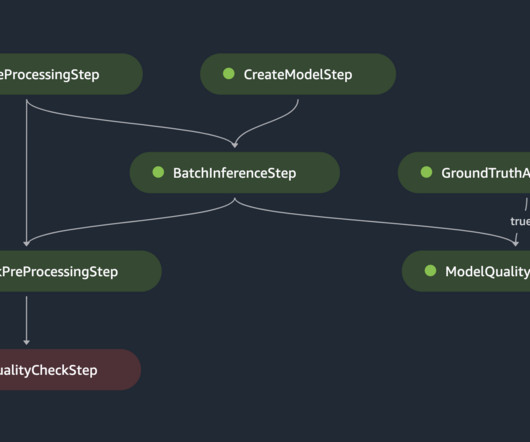
We finish with a case study highlighting the benefits realize by a large AWS and PwC customer who implemented this solution. Solution overview AWS offers a comprehensive portfolio of cloud-native services for developing and running MLOps pipelines in a scalable and sustainable manner. The following diagram illustrates the workflow.
How I cleared AWS Machine Learning Specialty with three weeks of preparation (I will burst some myths of the online exam) How I prepared for the test, my emotional journey during preparation, and my actual exam experience Certified AWS ML Specialty Badge source Introduction:- I recently gave and cleared AWS ML certification on 29th Dec 2022.
phData, an Advanced AWS Consulting Partner and Elite Snowflake Consulting Partner (plus 2x partner of the year!), provides expert end-to-end services for machine learning and data analytics. phData Senior ML Engineer Ryan Gooch recently evaluated options to accelerate ML model deployment with Snorkel Flow and AWS SageMaker.
phData, an Advanced AWS Consulting Partner and Elite Snowflake Consulting Partner (plus 2x partner of the year!), provides expert end-to-end services for machine learning and data analytics. phData Senior ML Engineer Ryan Gooch recently evaluated options to accelerate ML model deployment with Snorkel Flow and AWS SageMaker.
In this post, we describe how to create an MLOps workflow for batch inference that automates job scheduling, model monitoring, retraining, and registration, as well as error handling and notification by using Amazon SageMaker , Amazon EventBridge , AWS Lambda , Amazon Simple Notification Service (Amazon SNS), HashiCorp Terraform, and GitLab CI/CD.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content