This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction S3 is Amazon Web Services cloud-based object storage service (AWS). It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner. S3 […] The post Top 6 Amazon S3 Interview Questions appeared first on Analytics Vidhya.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). aligned identity provider (IdP).
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. About the Author Xiong Zhou is a Senior Applied Scientist at AWS.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose Create VPC.
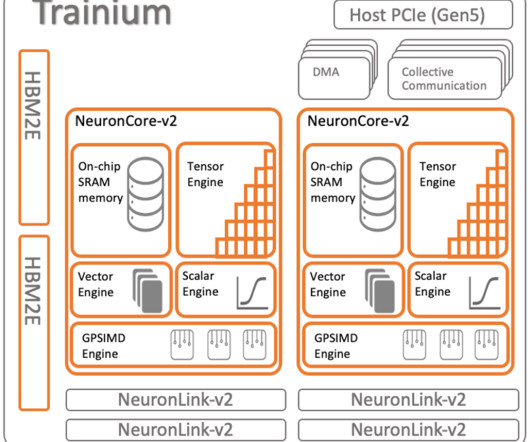
AWS Trainium and AWS Inferentia2 , which are purpose built for DL training and inference, extend their functionality and performance by supporting custom operators (or CustomOps, for short). AWS Neuron , the SDK that supports these accelerators, uses the standard PyTorch interface for CustomOps.
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To capture unanticipated, less obvious data patterns, you can enable anomaly detection.
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. When the preprocessing batch was complete, the training/test data needed for training was partitioned based on runtime and stored in Amazon S3.
You want to gather insights on this data and build an ML model to predict how new restaurants will be rated, but find it challenging to perform analytics on unstructured data. You encounter bottlenecks because you need to rely on dataengineering and data science teams to accomplish these goals.
MLOps focuses on the intersection of data science and dataengineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. MLOps requires the integration of software development, operations, dataengineering, and data science. Choose Create job.
The no-code environment of SageMaker Canvas allows us to quickly prepare the data, engineer features, train an ML model, and deploy the model in an end-to-end workflow, without the need for coding. In this walkthrough, we will cover importing your data directly from Snowflake. You can download the dataset loans-part-1.csv
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets.
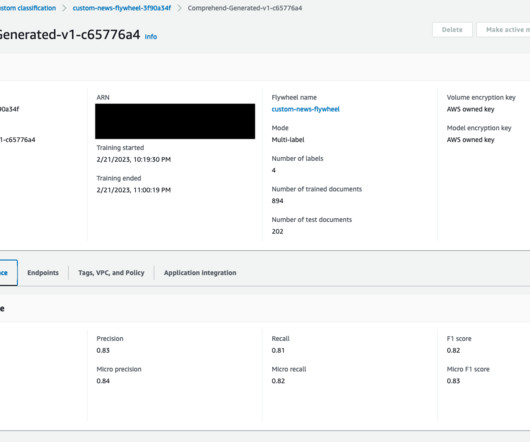
The integration eliminates the need for any coding or dataengineering to use the robust NLP models of Amazon Comprehend. You simply provide your text data and select from four commonly used capabilities: sentiment analysis, language detection, entities extraction, and personal information detection.
Each step of the workflow is developed in a different notebook, which are then converted into independent notebook jobs steps and connected as a pipeline: Preprocessing – Download the public SST2 dataset from Amazon Simple Storage Service (Amazon S3) and create a CSV file for the notebook in Step 2 to run. train sst2.train train sst2.train
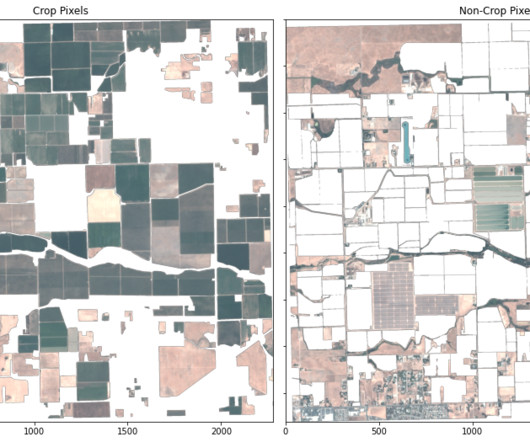
Amazon SageMaker geospatial capabilities combined with Planet ’s satellite data can be used for crop segmentation, and there are numerous applications and potential benefits of this analysis to the fields of agriculture and sustainability. This example uses the Python client to identify and download imagery needed for the analysis.
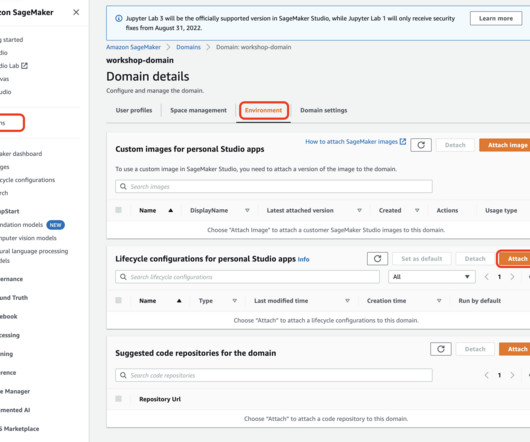
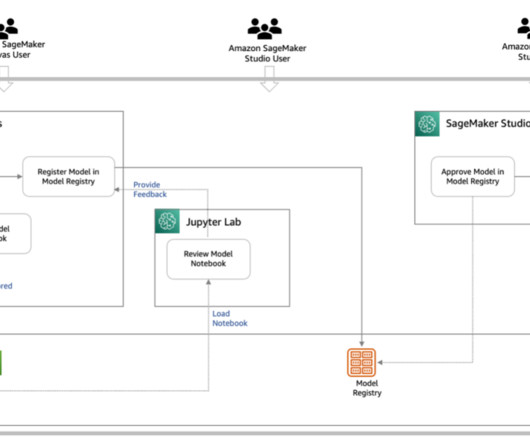
You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). The Studio Image Build CLI lets you build SageMaker-compatible Docker images directly from your Studio environments by using AWS CodeBuild. Environments without internet access.
Empowerment: Opening doors to new opportunities and advancing careers, especially for women in data. She highlighted various certification programs, including “Data Analyst,” “Data Scientist,” and “DataEngineer” under Career Certifications. She joined us to share her experience.
The DJL continues to grow in its ability to support different hardware, models, and engines. It also includes support for new hardware like ARM (both in servers like AWS Graviton and laptops with Apple M1 ) and AWS Inferentia. The architecture of DJL is engine agnostic. The engine then works to load the PyTorch Native.
Tweets inference data pipeline architecture Tweets Inference Data Pipeline Architecture (Screenshot by Author) The workflow performs the following tasks: Download Tweets Dataset: Download the tweets dataset from the S3 bucket. Prerequisites Create an AWS EC2 instance with ubuntu AMI, for example, ml.m5.xlarge
These teams are as follows: Advanced analytics team (data lake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
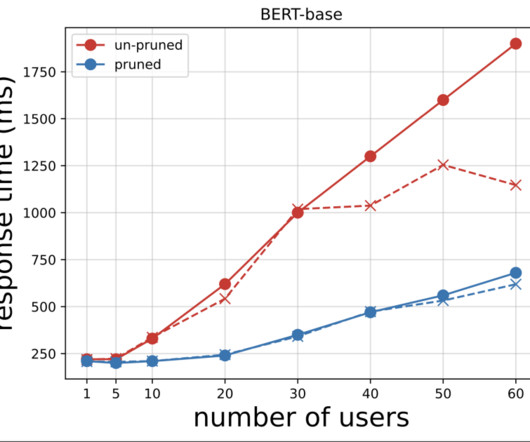
read()) except Exception as e: request_meta["exception"] = e request_meta["response_time"] = ( time.perf_counter() - start_perf_counter ) * 1000 events.request.fire(**request_meta) Next, we generate the response time plots from the CSV files downloaded after running the tests with Locust. Jacek Golebiowski is a Sr Applied Scientist at AWS.
Overview By harnessing the power of the Snowflake-Spark connector, you’ll learn how to transfer your data efficiently while ensuring compatibility and reliability. Whether you’re a dataengineer, analyst, or hobbyist, this blog will equip you with the knowledge and tools to confidently make this migration.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
In recent years, dataengineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
To provide an example, traditional structured data such as a user’s demographic information can be provided to an AI application to create a more personable experience. Our dataengineering blog in this series explores the concept of dataengineering and data stores for Gen AI applications in more detail.
“At Kestra Financial, we need confidence that we’re delivering trustworthy, reliable data to everyone making data-driven decisions,” said Justin Mikhalevsky, Vice President of Data Governance & Analytics, Kestra Financial. “We Learn more about the Open Data Quality Initiative by exploring the resources below.
Cloud Storage Upload Snowflake can easily upload files from cloud storage (AWS S3, Azure Storage, GCP Cloud Storage). Multi-person collaboration is difficult because users have to download and then upload the file every time changes are made. Upload via the Snowflake UI Snowflake allows users to load data directly from the web UI.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. Before delving into the technical details, let’s review some fundamental concepts.
Move inside sfguide-data-engineering-with-snowpark-python ( cd sfguide-data-engineering-with-snowpark-python ). For packages that are not currently available in our Anaconda environment, it will download the code and include them in the project zip file. Clone your forked repository to the root directory. (
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. Given the range of tools and data types, a separate data versioning logic will be necessary.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
General Purpose Tools These tools help manage the unstructured data pipeline to varying degrees, with some encompassing data collection, storage, processing, analysis, and visualization. DagsHub's DataEngine DagsHub's DataEngine is a centralized platform for teams to manage and use their datasets effectively.
Just click this button and fill out the form to download it. However, Snowflake runs better on Azure than it does on AWS – so even though it’s not the ideal situation, Microsoft still sees Azure consumption when organizations host Snowflake on Azure. Want to Save This Guide for Later? No problem!
However, building data-driven applications can be challenging. It often requires multiple teams working together and integrating various data sources, tools, and services. For example, creating a targeted marketing app involves dataengineers, data scientists, and business analysts using different systems and tools.
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. In this blog, we will describe 10 such Python Scripts that can provide a blueprint for using the Python component efficiently in Matillion ETL for Snowflake AI Data Cloud.
The solution also uses Amazon Bedrock , a fully managed service that makes foundation models (FMs) from Amazon and third-party model providers accessible through the AWS Management Console and APIs. or higher installed on either Linux, Mac, or a Windows Subsystem for Linux and an AWS account.
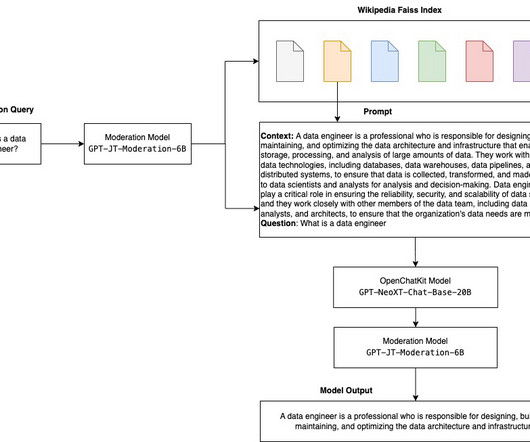
Solution overview The following steps are involved to build a chatbot using OpenChatKit models and deploy them on SageMaker: Download the chat base GPT-NeoXT-Chat-Base-20B model and package the model artifacts to be uploaded to Amazon Simple Storage Service (Amazon S3). Downloads are made concurrently to speed up the process.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
In this post, we present a solution for the following types of users: Non-ML experts such as business analysts, dataengineers, or developers, who are domain experts and are interested in low-code no-code (LCNC) tools to guide them in preparing data for ML and building ML models.
An AI technique called embedding language models converts this external data into numerical representations and stores it in a vector database. RAG introduces additional dataengineering requirements: Scalable retrieval indexes must ingest massive text corpora covering requisite knowledge domains.
Advanced Analytics: Snowflake’s platform is purposefully engineered to cater to the demands of machine learning and AI-driven data science applications in a cost-effective manner. Testing: Dataengineering should be treated as a form of software engineering.
Our relentless pursuit of valuable insights from data fuels our business decisions and works to achieve customer satisfaction. In this post, we discuss how GoDaddy’s Care & Services team, in close collaboration with the AWS GenAI Labs team, built Lighthouse—a generative AI solution powered by Amazon Bedrock.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content