This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Model versions should be managed centrally in a model registry.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
The solution framework is scalable as more equipment is installed and can be reused for a variety of downstream modeling tasks. In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. The effective precision of the trained model is 91.6%.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries. The architecture maps the different capabilities of the ML platform to AWS accounts.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. Airflow An open-source platform for building and scheduling data pipelines.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
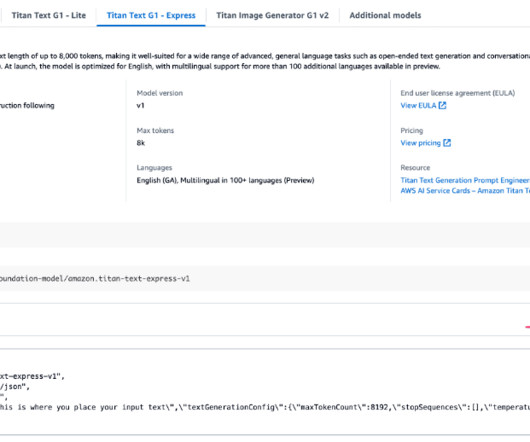
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. However, this is beyond the scope of this post.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses.
Built-in connectors bring in data from every single channel. That includes live data streams, streaming data from web and mobile, and APIs integrated with MuleSoft to bring in external data from legacy systems or proprietary datalakes. . Bring your own AI with AWS.
Built-in connectors bring in data from every single channel. That includes live data streams, streaming data from web and mobile, and APIs integrated with MuleSoft to bring in external data from legacy systems or proprietary datalakes. . Bring your own AI with AWS.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? These processes are essential in AI-based big data analytics and decision-making.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Understand the fundamentals of data engineering: To become an Azure Data Engineer, you must first understand the concepts and principles of data engineering. Knowledge of datamodeling, warehousing, integration, pipelines, and transformation is required. Data Warehousing concepts and knowledge should be strong.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Built-in connectors bring in data from every single channel. That includes live data streams, streaming data from web and mobile, and APIs integrated with MuleSoft to bring in external data from legacy systems or proprietary datalakes. Unify The power of the customer graph keeps going.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage.
3 Quickly build and deploy an end-to-end ML pipeline with Kubeflow Pipelines on AWS. They include: 1 Data (or input) pipeline. 2 Model (or training) pipeline. Model/training pipeline This pipeline trains one or more models on the training data with preset hyperparameters. What is a machine learning pipeline?
With the Amazon Bedrock serverless experience, you can experiment with and evaluate top foundation models (FMs) for your use cases, privately customize them with your data using techniques such as fine-tuning and RAG, and build agents that run tasks using enterprise systems and data sources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content