This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and datascience teams, and maintaining compliance with relevant financial regulations.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
Für DataScience ja sowieso. Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses. Ein Lakehouse inkludiert auch clevere Art und Weise auch einen DataLake. Die Inhalte des DataLakes sind bestenfalls etwas vorsortiert, aber eigentlich hofft man ja nicht, da wieder irgendwas drin wiederfinden zu müssen.
Welcome to the first beta edition of Cloud DataScience News. This will cover major announcements and news for doing datascience in the cloud. Azure Synapse Analytics This is the future of data warehousing. Azure Synapse Analytics This is the future of data warehousing. Microsoft Azure. Google Cloud.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. The solution integrates data in three tiers.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the cloud datascience world. Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Those are the big datascience announcements of the week.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Even though Amazon is taking a break from announcements (probably focusing on Christmas shoppers), there are still some updates in the cloud datascience world. Azure Tips and Tricks: Make your data Searchable A quick video to demonstrate Azure Search. Here they are. It now also supports PDF documents. Courses and Learning.
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
Here’s what we found for both skills and platforms that are in demand for data scientist jobs. DataScience Skills and Competencies Aside from knowing particular frameworks and languages, there are various topics and competencies that any data scientist should know. Joking aside, this does infer particular skills.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
Amazon Simple Storage Service (Amazon S3) stores the model artifacts and creates a datalake to host the inference output, document analysis output, and other datasets in CSV format. SageMaker JumpStart provided deployable models that could be trained for object detection use cases with minimal datascience knowledge and overhead.
In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. We first highlight how we use AWS Glue for highly parallel data processing. This dramatically reduces the size of data while capturing features that characterize the equipment’s behavior.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources , including Amazon Athena , which supports Apache Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. Airflow An open-source platform for building and scheduling data pipelines.
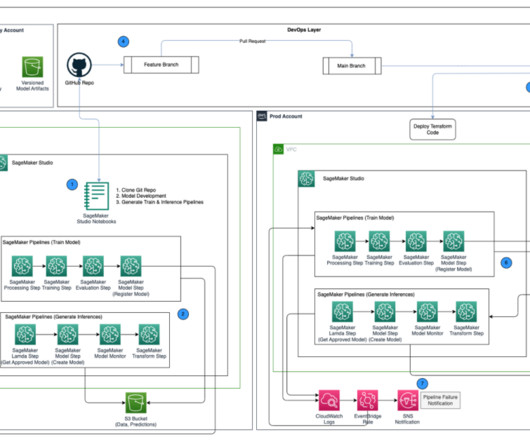
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Manager DataScience at Marubeni Power International. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data collection and ingestion The data collection and ingestion layer connects to all upstream data sources and loads the data into the datalake.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
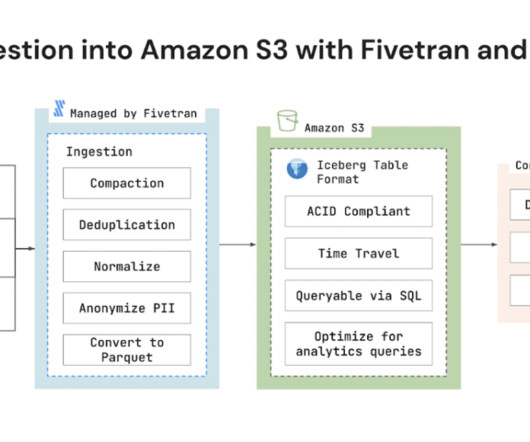
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
MLOps focuses on the intersection of datascience and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. MLOps requires the integration of software development, operations, data engineering, and datascience.
Be sure to check out her talk, “ Don’t Go Over the Deep End: Building an Effective OSS Management Layer for Your DataLake ,” there! Managing a datalake can often feel like being lost at sea — especially when dealing with both structured and unstructured data.
Therefore, it’s no surprise that determining the proficiency of goalkeepers in preventing the ball from entering the net is considered one of the most difficult tasks in football data analysis. Bundesliga and AWS have collaborated to perform an in-depth examination to study the quantification of achievements of Bundesliga’s keepers.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. Our solution aims to address those challenges using Amazon Bedrock and AWS Analytics Services.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Review the access policy to understand permissions granted.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
Building out a machine learning operations (MLOps) platform in the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML) for organizations is essential for seamlessly bridging the gap between datascience experimentation and deployment while meeting the requirements around model performance, security, and compliance.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. Solution overview Figure 1 – Solution Architecture Enable Amazon Security Lake with AWS Organizations for AWS accounts, AWS Regions, and external IT environments.
These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer. Identify your existing datascience strengths. Stay on top of data engineering trends. Get more training!
The IDP Well-Architected Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build secure, efficient, and reliable IDP solutions on AWS. AWS might periodically update the service limits based on various factors.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The solution: A datascience approach In datascience, it’s common to develop a model and fine tune it using experimentation.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Datascience teams often face challenges when transitioning models from the development environment to production. Usually, there is one lead data scientist for a datascience group in a business unit, such as marketing. ML Dev Account This is where data scientists perform their work.
Similarly, it would be pointless to pretend that a data-intensive application resembles a run-off-the-mill microservice which can be built with the usual software toolchain consisting of, say, GitHub, Docker, and Kubernetes. Adapted from the book Effective DataScience Infrastructure. DataScience Layers.
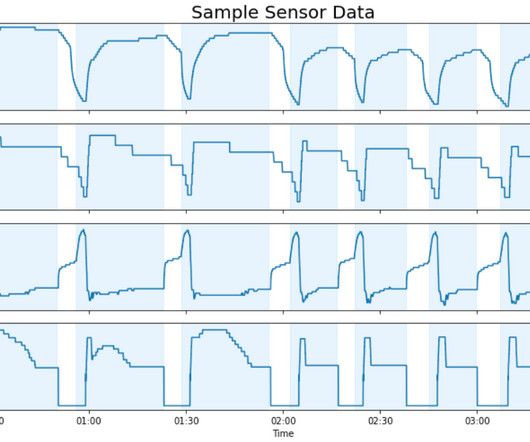
In this post, we describe how AWS Partner Airis Solutions used Amazon Lookout for Equipment , AWS Internet of Things (IoT) services, and CloudRail sensor technologies to provide a state-of-the-art solution to address these challenges. It’s an easy way to run analytics on IoT data to gain accurate insights.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Data integration: Integrate data from various sources into a centralized cloud data warehouse or datalake. Ensure that data is clean, consistent, and up-to-date.
AWS is like that overachieving student who excels at everything. Complex pricing structure (seriously, who can predict AWS bills?).Steeper Join thousands of data leaders on the AI newsletter. , and even facing performance bottlenecks, I finally cracked the code. Lets dive in!
It includes sensor devices to capture vibration and temperature data, a gateway device to securely transfer data to the AWS Cloud, the Amazon Monitron service that analyzes the data for anomalies with ML, and a companion mobile app to track potential failures in your machinery.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content