This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. Precise Software Solutions, Inc. The platform helped the agency digitize and process forms, pictures, and other documents.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
Solution overview Amazon SageMaker is a fully managed service that helps developers and datascientists build, train, and deploy machine learning (ML) models. About the authors Scott Patterson is a Senior Solutions Architect at AWS. The sunburst graph below is a visualization of this classification.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels. Solution requirements Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. We first highlight how we use AWS Glue for highly parallel data processing. This dramatically reduces the size of data while capturing features that characterize the equipment’s behavior.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
Therefore, it’s no surprise that determining the proficiency of goalkeepers in preventing the ball from entering the net is considered one of the most difficult tasks in football data analysis. Bundesliga and AWS have collaborated to perform an in-depth examination to study the quantification of achievements of Bundesliga’s keepers.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Their task is to construct and oversee efficient data pipelines.
Versioning also ensures a safer experimentation environment, where datascientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch. Data Science Layers. Software Development Layers. Software Architecture.
Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. I have not gotten a chance to try it out yet, so I am not sure its usecase for data science yet.
The role of a datascientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 datascientist job descriptions from that past year to find out what employers are looking for in 2023. Data Science Of course, a datascientist should know data science!
In Part 3 , we demonstrate how business analysts and citizen datascientists can create machine learning (ML) models, without code, in Amazon SageMaker Canvas and deploy trained models for integration with Salesforce Einstein Studio to create powerful business applications. For this post, we use the Anthropic Claude 3 Sonnet model.
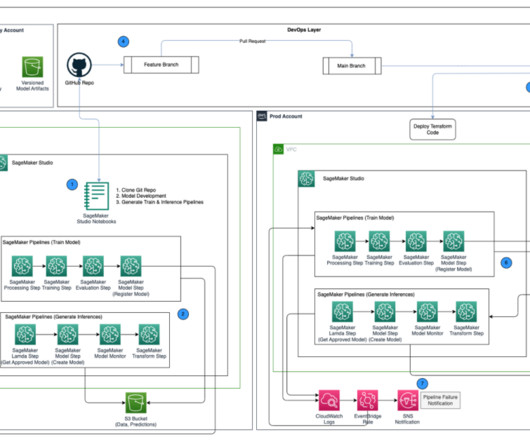
In this post, we assign the functions in terms of the ML lifecycle to each role as follows: Lead datascientist Provision accounts for ML development teams, govern access to the accounts and resources, and promote standardized model development and approval process to eliminate repeated engineering effort.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge. sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas. Note we have two folders.
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. with administrative privileges installed on AWS Terraform version 1.5.5 After the key is provisioned, it should be visible on the AWS KMS console.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Data integration: Integrate data from various sources into a centralized cloud data warehouse or datalake. Ensure that data is clean, consistent, and up-to-date.
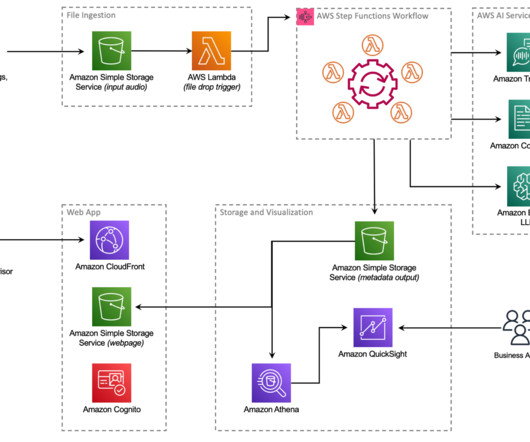
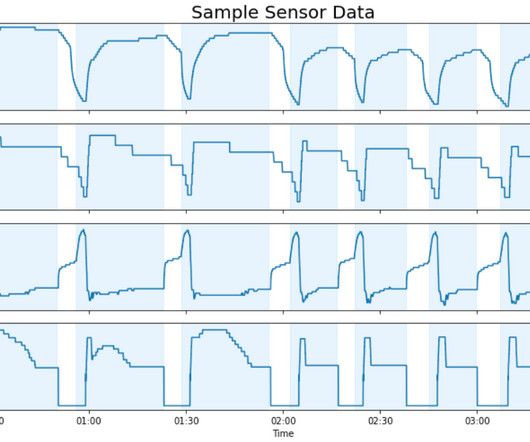
In this post, we describe how AWS Partner Airis Solutions used Amazon Lookout for Equipment , AWS Internet of Things (IoT) services, and CloudRail sensor technologies to provide a state-of-the-art solution to address these challenges. It’s an easy way to run analytics on IoT data to gain accurate insights.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. Eitan Sela is a Generative AI and Machine Learning Specialist Solutions Architect at AWS.
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. On an ongoing basis, we calculate mean absolute percentage error (MAPE) ratios with product-based data, and optimize model and feature ingestion processes.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
We demonstrate CDE using simple examples and provide a step-by-step guide for you to experience CDE in an Amazon Kendra index in your own AWS account. Marketing firms store vast amounts of digital data that needs to be centralized, easily searchable, and scalable enabled by data catalogs.
It includes sensor devices to capture vibration and temperature data, a gateway device to securely transfer data to the AWS Cloud, the Amazon Monitron service that analyzes the data for anomalies with ML, and a companion mobile app to track potential failures in your machinery.
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. When choosing a datalake, here’s something else to consider.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Since AI is a central pillar of their value offering, Sense has invested heavily in a robust engineering organization including a large number of data and AI professionals. This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. First, the datalake is fed from a number of data sources.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and datascientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors.
Since AI is a central pillar of their value offering, Sense has invested heavily in a robust engineering organization, including a large number of data and data science professionals. This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. Gennaro Frazzingaro, Head of AI/ML at Sense.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content