This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Schon damals in Ansätzen, aber spätestens heute gilt es zu recht als Best Practise, die Datenanbindung an ein DataWarehouse zu machen und in diesem die Daten für die Reports aufzubereiten. Ein DataWarehouse ist eine oder eine Menge von Datenbanken. Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
Datawarehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. datawarehouse. It is often used as a foundation for enterprise datalakes.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. Precise Software Solutions, Inc. The platform helped the agency digitize and process forms, pictures, and other documents.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use datawarehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Create VPC.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a datalake? This can be structured, semi-structured, and even unstructured data. Where does it go?
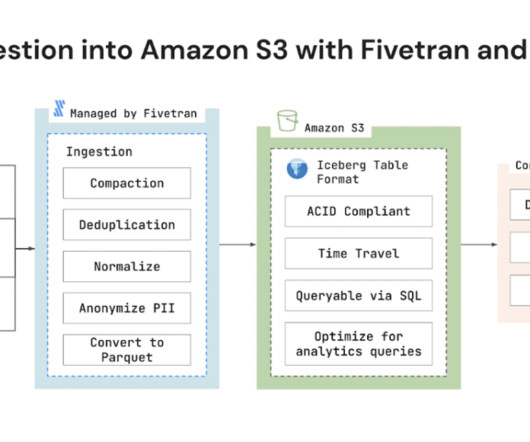
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. It provides a single web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
Most enterprises today store and process vast amounts of data from various sources within a centralized repository known as a datawarehouse or datalake, where they can analyze it with advanced analytics tools to generate critical business insights.
Alation recently attended AWS re:invent 2021 … in person! AWS Keynote: “Still Early Days” for Cloud. Adam Selipsky, CEO of AWS, brought this energy in his opening keynote, welcoming a packed room and looking back on the progress of AWS. Re:Invent 2021 Keynote by AWS CEO Adam Selipsky. AWS’ Top Cloud Challenges.
Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Here they are in my order of importance (based upon my opinion). Azure Synapse.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) datalake, invoking the processing using AWS Step Functions. The raw data is processed by an LLM using a preconfigured user prompt.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Data integration: Integrate data from various sources into a centralized cloud datawarehouse or datalake. Ensure that data is clean, consistent, and up-to-date.
The success of any data initiative hinges on the robustness and flexibility of its big data pipeline. What is a Data Pipeline? A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a datawarehouse or datalake.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Data lakehouse was created to solve these problems.
ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing datawarehouses. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch. Software Development Layers.
Most recently, JP Morgan built a ‘Mesh’ on AWS and locked its scalability fortune on a decentralized architecture. More case studies are added every day and give a clear hint – data analytics are all set to change, again! . Data Management before the ‘Mesh’. The cloud age did address that issue to a certain extent.
Overall, implementing a modern data architecture and generative AI techniques with AWS is a promising approach for gleaning and disseminating key insights from diverse, expansive data at an enterprise scale. AWS also offers foundation models through Amazon SageMaker JumpStart as Amazon SageMaker endpoints.
Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments. Natively connect to trusted, unified customer data.
Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments. Natively connect to trusted, unified customer data.
It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
Oracle – The Oracle connector, a database-type connector, enables real-time data transfer of large volumes of data from on-premises or cloud sources to the destination of choice, such as a cloud datalake or datawarehouse. File – Fivetran offers several options to sync files to your destination.
In this blog, we’ll delve into the intricacies of data ingestion, exploring its challenges, best practices, and the tools that can help you harness the full potential of your data. Batch Processing In this method, data is collected over a period and then processed in groups or batches. The post What is Data Ingestion?
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and datalakes.
These datasets are often a mix of numerical and text data, at times structured, unstructured, or semi-structured. needed to address some of these challenges in one of their many AI use cases built on AWS. The dataset Our structured dataset can reside in a SQL database, datalake, or datawarehouse as long as we have support for SQL.
Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 datalake, Snowflake cloud datawarehouse and Tableau (and how it can be fixed). And connectivity is the crux of a powerful data catalog.
Focus Area ETL helps to transform the raw data into a structured format that can be easily available for data scientists to create models and interpret for any data-driven decision. A data pipeline is created with the focus of transferring data from a variety of sources into a datawarehouse.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments. Salesforce Data Cloud for Tableau solves those challenges.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud datawarehouse or datalake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance.
Read More: How Airbnb Uses Big Data and Machine Learning to Offer World-Class Service Netflix’s Big Data Infrastructure Netflix’s data infrastructure is one of the most sophisticated globally, built primarily on cloud technology. petabytes of data. What Technologies Does Netflix Use for Its Big Data Infrastructure?
Consequently, here is an overview of the essential requirements that you need to have to get a job as an Azure Data Engineer. In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Data Warehousing concepts and knowledge should be strong.
Creating multimodal embeddings means training models on datasets with multiple data types to understand how these types of information are related. Multimodal embeddings help combine unstructured data from various sources in datawarehouses and ETL pipelines.
As it has previously been pointed out, ETL stands for extract, transform and load, and refers to the process that extracts data from a source point, transforms the data in some way and loads the output data to a target point. There are mainly 2 different types of ETL: batch and streaming.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content