This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time. raw_customer".
Their information is split between two types of data: unstructured data (such as PDFs, HTML pages, and documents) and structured data (such as databases, datalakes, and real-time reports). Different types of data typically require different tools to access them.
For a multi-account environment, you can track costs at an AWS account level to associate expenses. A combination of an AWS account and tags provides the best results. Implement a tagging strategy A tag is a label you assign to an AWS resource. The AWS reserved prefix aws: tags provide additional metadata tracked by AWS.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
Although generative AI is fueling transformative innovations, enterprises may still experience sharply divided data silos when it comes to enterprise knowledge, in particular between unstructured content (such as PDFs, Word documents, and HTML pages), and structured data (real-time data and reports stored in databases or datalakes).
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. These services write the output to a datalake.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
Writing data to an AWSdatalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Create VPC.
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. LOBs have autonomy over their AI workflows, models, and data within their respective AWS accounts.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI). Solutions Architect at AWS. Varun Mehta is a Sr.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources , including Amazon Athena , which supports Apache Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. AWS Athena and S3.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access. As always, AWS welcomes feedback.
They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels. Solution requirements Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS.
Further to the acquisition, Broadcom decided to discontinue (link resides outside ibm.com) its AWS authorization to resell VMware Cloud on AWS as of 30 April 2024. As a result, AWS will no longer be able to offer new subscriptions or additional services.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. Today, generative AI can enable people without SQL knowledge.
This post explores key insights and lessons learned from AWS customers in Europe, Middle East, and Africa (EMEA) who have successfully navigated this transition, providing a roadmap for others looking to follow suit. Il Sole 24 Ore leveraged its vast internal knowledge with a Retrieval Augmented Generation (RAG) solution powered by AWS.
Be sure to check out her talk, “ Don’t Go Over the Deep End: Building an Effective OSS Management Layer for Your DataLake ,” there! Managing a datalake can often feel like being lost at sea — especially when dealing with both structured and unstructured data.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. This allows for data to be aggregated for further manufacturer-agnostic analysis.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) datalake, invoking the processing using AWS Step Functions. The raw data is processed by an LLM using a preconfigured user prompt.
To do this, the text input is transformed into a structured representation, and from this representation, a SQL query that can be used to access a database is created. The primary goal of Text2SQL is to make querying databases more accessible to non-technical users, who can provide their queries in natural language. gymnast_id = t2.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The problem Making data accessible to users through applications has always been a challenge.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake.
Overall, implementing a modern data architecture and generative AI techniques with AWS is a promising approach for gleaning and disseminating key insights from diverse, expansive data at an enterprise scale. AWS also offers foundation models through Amazon SageMaker JumpStart as Amazon SageMaker endpoints.
Many organizations store their data in structured formats within data warehouses and datalakes. Amazon Bedrock Knowledge Bases offers a feature that lets you connect your RAG workflow to structured data stores. The key is to choose a solution that can effectively host your database and compute infrastructure.
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. It offers an AWS CloudFormation template for straightforward deployment in an AWS account.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Setup the Database access and Network access.
Alation recently attended AWS re:invent 2021 … in person! AWS Keynote: “Still Early Days” for Cloud. Adam Selipsky, CEO of AWS, brought this energy in his opening keynote, welcoming a packed room and looking back on the progress of AWS. Re:Invent 2021 Keynote by AWS CEO Adam Selipsky. AWS’ Top Cloud Challenges.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















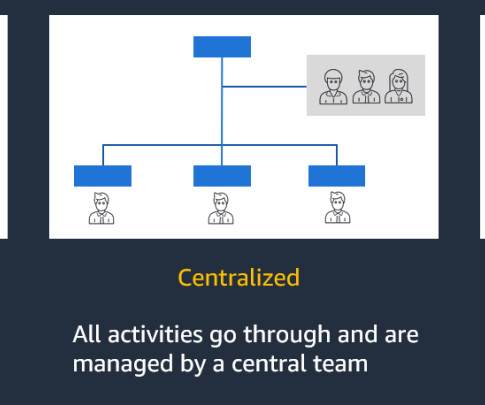









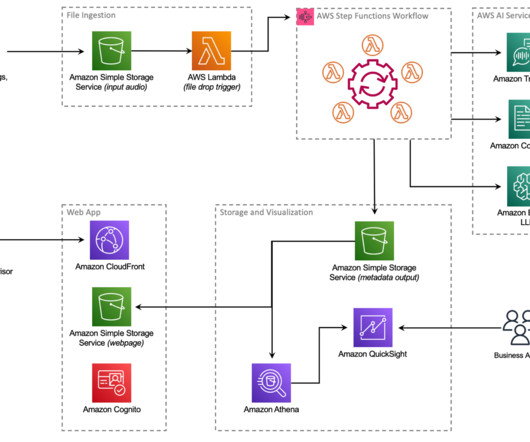














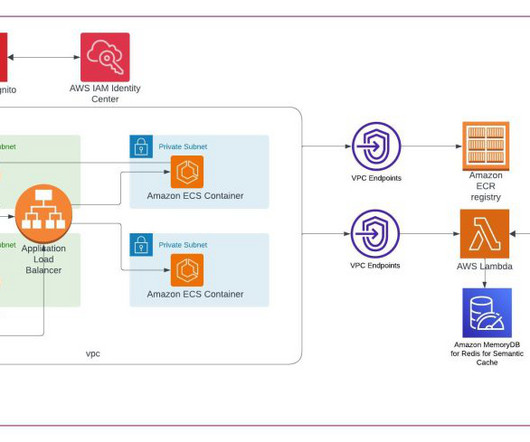









Let's personalize your content