This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only). Query the vector data store You can query the vector data store using the Vector Search aggregation pipeline. It uses the Vector Search index and performs a semantic search on the vector data store.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) datalake, invoking the processing using AWS Step Functions. The raw data is processed by an LLM using a preconfigured user prompt.
The IDP Well-Architected Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build secure, efficient, and reliable IDP solutions on AWS.
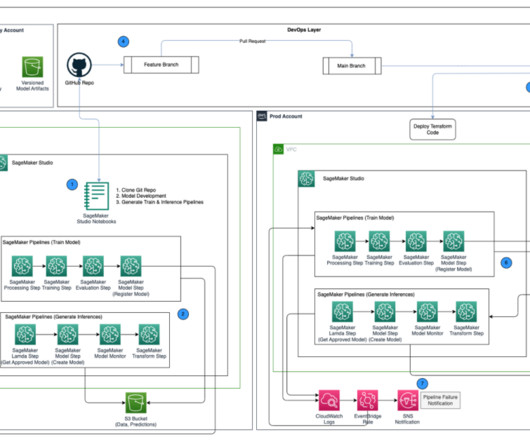
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. with administrative privileges installed on AWS Terraform version 1.5.5 After the key is provisioned, it should be visible on the AWS KMS console.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. Software Development Layers.
Overall, implementing a modern data architecture and generative AI techniques with AWS is a promising approach for gleaning and disseminating key insights from diverse, expansive data at an enterprise scale. AWS also offers foundation models through Amazon SageMaker JumpStart as Amazon SageMaker endpoints.
To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. Much of what we found was to be expected, though there were definitely a few surprises. You’ll see specific tools in the next section.
External Tables Create a Shared View of the DataLake. We’ve seen external tables become popular with our customers, who use them to provide a normalized relational schema on top of their datalake. Essentially, external tables create a shared view of the datalake, a single pane of glass everyone can reference.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Data fabric: A mostly new architecture.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
Having been in business for over 50 years, ARC had accumulated a massive amount of data that was stored in siloed, on-premises servers across its 7 business domains. Using Alation, ARC automated the data curation and cataloging process. “So
Before starting to collect data, it is important to conceptualize a business problem that can be solved with machine learning. Only once you form a clear definition and understanding of the business problem , goals, and the necessity of machine learning should you move forward to the next stage of data preparation.
We also discuss common security concerns that can undermine trust in AI, as identified by the Open Worldwide Application Security Project (OWASP) Top 10 for LLM Applications , and show ways you can use AWS to increase your security posture and confidence while innovating with generative AI.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Machine Learning Operations (MLOps): Overview, Definition, and Architecture (by Kreuzberger, et al., AIIA MLOps blueprints.
To fulfill these requirements, TR built the Enterprise AI platform around the following five pillars: a data service, experimentation workspace, central model registry, model deployment service, and model monitoring. Amazon Simple Storage Service (Amazon S3) object storage acts as a content datalake.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content