This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. The platform helped the agency digitize and process forms, pictures, and other documents. Precise Software Solutions, Inc.
Text, images, audio, and videos are common examples of unstructured data. Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This archive, along with 765,933 varied-quality inspection photographs, some over 15 years old, presented a significant data processing challenge. Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture. im', 0.08224299065420558), ('jun 23.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As always, AWS welcomes feedback. Before testing, choose the gear icon.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Amazon Comprehend is a managed AI service that uses natural language processing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
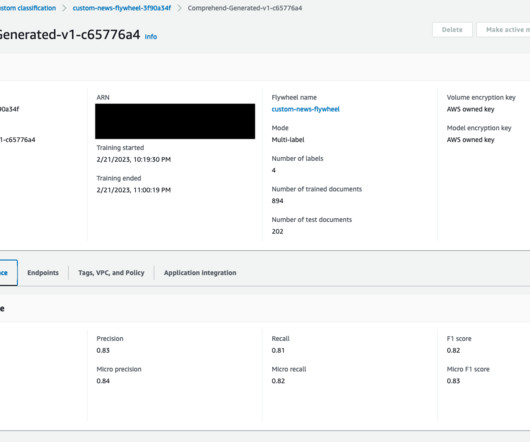
Solution overview Amazon Comprehend is a fully managed service that uses natural language processing (NLP) to extract insights about the content of documents. This feature also allows you to automate model retraining after new datasets are ingested and available in the flywheel´s datalake.
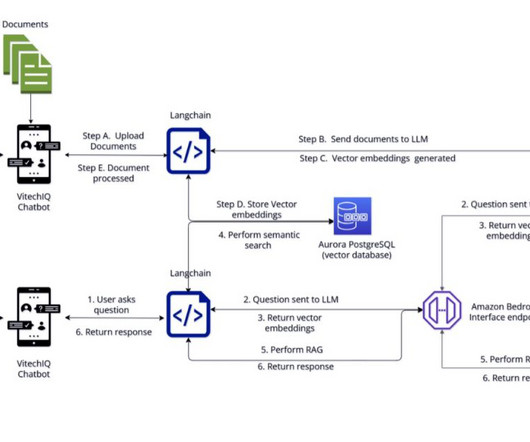
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders).
The IDP Well-Architected Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build secure, efficient, and reliable IDP solutions on AWS. This post focuses on the Operational Excellence pillar of the IDP solution.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, or “What is the reach characterization ratio and how do I calculate it?”
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. Each embedding aims to capture the semantic or contextual meaning of the data.
It now also supports PDF documents. Azure Data Factory Preserves Metadata during File Copy When performing a File copy between Amazon S3, Azure Blob, and Azure DataLake Gen 2, the metadata will be copied as well. Azure Tips and Tricks: Make your data Searchable A quick video to demonstrate Azure Search.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. Our solution aims to address those challenges using Amazon Bedrock and AWS Analytics Services.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation. The Step Functions workflow starts.
In Part 3 , we demonstrate how business analysts and citizen data scientists can create machine learning (ML) models, without code, in Amazon SageMaker Canvas and deploy trained models for integration with Salesforce Einstein Studio to create powerful business applications. For this post, we use the Anthropic Claude 3 Sonnet model.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Note we have two folders.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The question is sent through a retrieval-augmented generation (RAG) process, which finds similar documents.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. Images can often be searched using supplemented metadata such as keywords.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Data scientists Perform data analysis, model development, model evaluation, and registering the models in a model registry. Governance officer Review the models performance including documentation, accuracy, bias and access, and provide final approval for models to be deployed.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Informatica’s AI-powered automation helps streamline data pipelines and improve operational efficiency. Common use cases include integrating data across hybrid cloud environments, managing datalakes, and enabling real-time analytics for Business Intelligence platforms.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc.
This includes operations like data validation, data cleansing, data aggregation, and data normalization. The goal is to ensure that the data is consistent and ready for analysis. Loading : Storing the transformed data in a target system like a data warehouse, datalake, or even a database.
Oracle – The Oracle connector, a database-type connector, enables real-time data transfer of large volumes of data from on-premises or cloud sources to the destination of choice, such as a cloud datalake or data warehouse. File – Fivetran offers several options to sync files to your destination.
It is suitable for a wide range of use cases, such as datalake storage, backup and recovery, and content delivery. Object Storage: In MinIO, data is organized as objects, where each object typically represents a file or a piece of data. Objects can be of any type, such as images, videos, documents, etc.
Implementing proper version control in ML pipelines is essential for efficient management of code, data, and models by ensuring reproducibility and collaboration. Reproducibility ensures that experiments can be reliably reproduced by tracking changes in code, data, and model hyperparameters. Pachyderm : Data driven pipelines.
Airline Reporting Corporation (ARC) sells data products to travel agencies and airlines. Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 datalake, Snowflake cloud data warehouse and Tableau (and how it can be fixed).
Data Collector also offers replication and Change Data Capture (CDC) to be able to accurately and efficiently get your data into Snowflake. Data Collector can use Snowflake’s native Snowpipe in its pipelines. For those looking to migrate to Snowflake who prefer using AWS services, DMS is a great solution.
So, we must understand the different unstructured data types and effectively process them to uncover hidden patterns. Textual Data Textual data is one of the most common forms of unstructured data and can be in the format of documents, social media posts, emails, web pages, customer reviews, or conversation logs.
Why External Tables are Important Data Ingestion: External tables allow you to easily load data into Snowflake from various external data sources without the need to first stage the data within Snowflake. Data Integration: Snowflake supports seamless integration with other data processing systems and datalakes.
If your organization runs its workloads on AWS , it might be worth it to leverage AWS SageMaker. Solution Datalakes and warehouses are the two key components of any data pipeline. The datalake is a platform where any kind or amount of data can be stored, processed, and analyzed.
Only once you form a clear definition and understanding of the business problem , goals, and the necessity of machine learning should you move forward to the next stage of data preparation. In large ML organizations, there is typically a dedicated team for all the above aspects of data preparation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content