This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Create VPC.
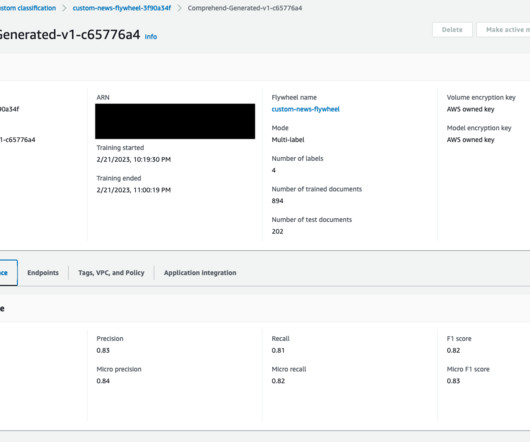
This feature also allows you to automate model retraining after new datasets are ingested and available in the flywheel´s datalake. First, let’s introduce some concepts: Flywheel – A flywheel is an AWS resource that orchestrates the ongoing training of a model for custom classification or custom entity recognition.
Flywheel creates a datalake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. The data can be accessed from AWS Open Data Registry.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. Our solution aims to address those challenges using Amazon Bedrock and AWS Analytics Services.
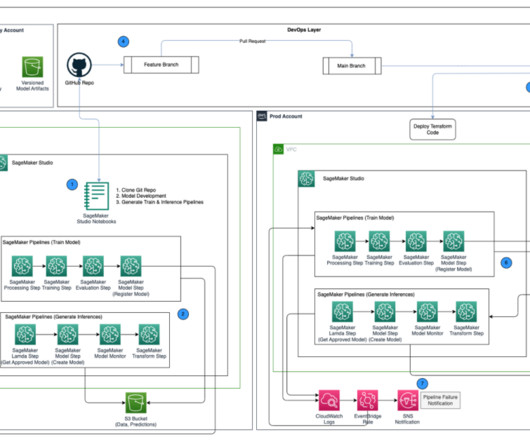
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. with administrative privileges installed on AWS Terraform version 1.5.5 After the key is provisioned, it should be visible on the AWS KMS console.
The following are just a few things to consider as you select a provider: Price – Some providers offer free weather data, some offer subscriptions, and some offer meter-based packages. AWS has many databases to help store your data, including cost-effective datalakes on Amazon Simple Storage Service (Amazon S3).
We demonstrate CDE using simple examples and provide a step-by-step guide for you to experience CDE in an Amazon Kendra index in your own AWS account. Marketing firms store vast amounts of digital data that needs to be centralized, easily searchable, and scalable enabled by data catalogs.
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. The endpoint will be exposed to Salesforce Data Cloud as an API through API Gateway.
External Tables Create a Shared View of the DataLake. We’ve seen external tables become popular with our customers, who use them to provide a normalized relational schema on top of their datalake. Essentially, external tables create a shared view of the datalake, a single pane of glass everyone can reference.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud data warehouse or datalake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance. Download Best Practice 1.
Data ingress and egress Snorkel enables multiple paths to bring data into and out of Snorkel Flow, including but not limited to: Upload from and download to your local computer Data connectors with common third-party datalakes such as Databricks, Snowflake, Google Big Query as well as S3, GCS, and Azure buckets.
Why External Tables are Important Data Ingestion: External tables allow you to easily load data into Snowflake from various external data sources without the need to first stage the data within Snowflake. Data Integration: Snowflake supports seamless integration with other data processing systems and datalakes.
It is suitable for a wide range of use cases, such as datalake storage, backup and recovery, and content delivery. S3 Compatibility : MinIO is compatible with S3 API, which is the standard interface for interacting with object storage in the AWS ecosystem. Save our trained model into local storage and load it back to BentoML.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Cloud ETL Pipeline: Cloud ETL pipeline for ML involves using cloud-based services to extract, transform, and load data into an ML system for training and deployment. Cloud providers such as AWS, Microsoft Azure, and GCP offer a range of tools and services that can be used to build these pipelines.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
Data Processing : You need to save the processed data through computations such as aggregation, filtering and sorting. Data Storage : To store this processed data to retrieve it over time – be it a data warehouse or a datalake.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
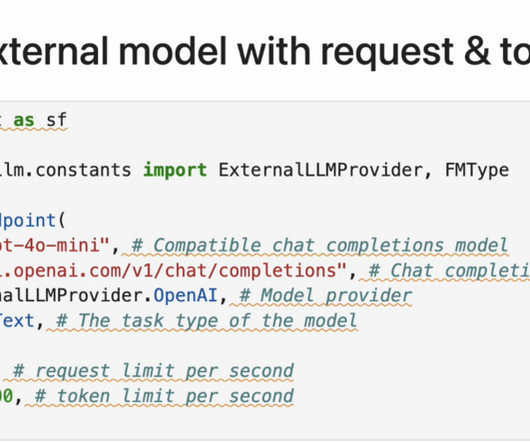
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure.
The use of separate data warehouses and lakes has created data silos, leading to problems such as lack of interoperability, duplicate governance efforts, complex architectures, and slower time to value. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and datalakes.
In the following sections, we demonstrate how to import and prepare the data, optionally export the data, create a model, and run inference, all in SageMaker Canvas. Download the dataset from Kaggle and upload it to an Amazon Simple Storage Service (Amazon S3) bucket. Solutions Architect at AWS.
Diverse data amplifies the need for customizable cleaning and transformation logic to handle the quirks of different sources. In this post, we will explore building a reusable RAG data pipeline on LangChain —an open source framework for building applications based on LLMs—and integrating it with AWS Glue and Amazon OpenSearch Serverless.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
This post builds on a previous post, Integrate QnABot on AWS with ServiceNow , and explores how to build an intelligent assistant using Amazon Lex , Amazon Bedrock Knowledge Bases , and a custom ServiceNow integration to create an automated incident management support experience. Data in Amazon S3 is encrypted by default.
With the Amazon Bedrock serverless experience, you can experiment with and evaluate top foundation models (FMs) for your use cases, privately customize them with your data using techniques such as fine-tuning and RAG, and build agents that run tasks using enterprise systems and data sources. On the Domains page, open your domain.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content