This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWSevents in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! And although generative AI has appeared in previous events, this year we’re taking it to the next level. And although generative AI has appeared in previous events, this year we’re taking it to the next level.
Recent events including Tropical Cyclone Gabrielle have highlighted the susceptibility of the grid to extreme weather and emphasized the need for climate adaptation with resilient infrastructure. About the authors Scott Patterson is a Senior Solutions Architect at AWS. The sunburst graph below is a visualization of this classification.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. earthquake, flood, or fire), where the data collected does not need to be as tightly controlled.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. Solution overview Figure 1 – Solution Architecture Enable Amazon Security Lake with AWS Organizations for AWS accounts, AWS Regions, and external IT environments.
The IDP Well-Architected Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build secure, efficient, and reliable IDP solutions on AWS. Set up regular game days to test workload and team responses to simulated events.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). This provides an audit trail required for governance and compliance.
Alation recently attended AWS re:invent 2021 … in person! AWS Keynote: “Still Early Days” for Cloud. Adam Selipsky, CEO of AWS, brought this energy in his opening keynote, welcoming a packed room and looking back on the progress of AWS. Re:Invent 2021 Keynote by AWS CEO Adam Selipsky. AWS’ Top Cloud Challenges.
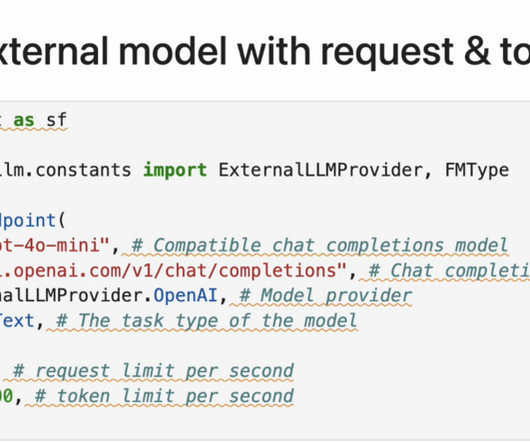
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure.
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. It offers an AWS CloudFormation template for straightforward deployment in an AWS account.
Diagnostic analytics: Diagnostic analytics goes a step further by analyzing historical data to determine why certain events occurred. By understanding the “why” behind past events, organizations can make informed decisions to prevent or replicate them. Ensure that data is clean, consistent, and up-to-date.
Traditional maintenance activities rely on a sizable workforce distributed across key locations along the BHS dispatched by operators in the event of an operational fault. With this service, industrial sensors, smart meters, and OPC UA servers can be connected to an AWSdatalake with just a few clicks.
Even Forbes Tech Council has written about the benefits of datalakes in Fortnite. The game’s parent company, Epic Games, processes millions of events each minute, and its mountain of data grows steadily. Processing and analyzing this data — petabytes worth — must happen somewhere.
It includes sensor devices to capture vibration and temperature data, a gateway device to securely transfer data to the AWS Cloud, the Amazon Monitron service that analyzes the data for anomalies with ML, and a companion mobile app to track potential failures in your machinery.
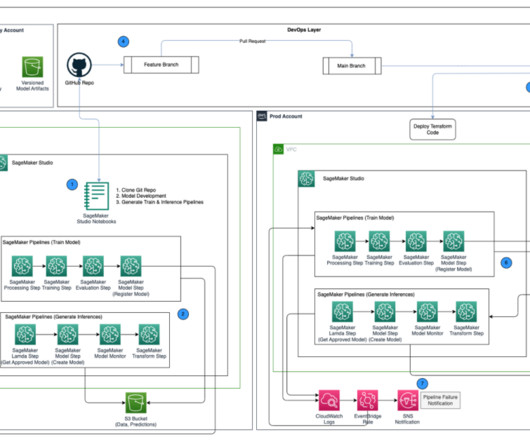
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. with administrative privileges installed on AWS Terraform version 1.5.5 After the key is provisioned, it should be visible on the AWS KMS console.
Imperva Cloud WAF protects hundreds of thousands of websites against cyber threats and blocks billions of security events every day. Counters and insights based on security events are calculated daily and used by users from multiple departments. The data is stored in a datalake and retrieved by SQL using Amazon Athena.
sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas. The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models. Note we have two folders.
To fulfill these requirements, TR built the Enterprise AI platform around the following five pillars: a data service, experimentation workspace, central model registry, model deployment service, and model monitoring. Amazon Simple Storage Service (Amazon S3) object storage acts as a content datalake.
Examples include seasonality, marketing promotions, pricing, and in-stock availability for retail sales, or temperature, length of daylight, or special events for utility demand. Local, regional, and world factors such as commodity prices, financial markets, and events such as COVID-19 can also change demand trajectory.
This account manages templates for setting up new ML Dev Accounts, as well as SageMaker Projects templates for model development and deployment, in AWS Service Catalog. It also hosts a model registry to store ML models developed by data science teams, and provides a single location to approve models for deployment.
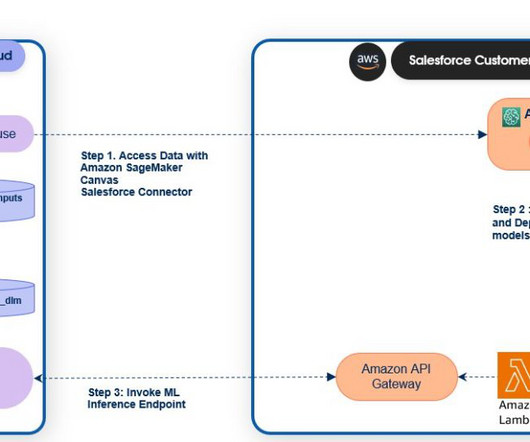
Configure OAuth settings for the Salesforce Data Cloud connector SageMaker Canvas uses AWS Secrets Manager to securely store connection information from the Salesforce connected app. For Data Source , choose Salesforce Data Cloud and Add Connection to import the datalake object.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
These datasets are often a mix of numerical and text data, at times structured, unstructured, or semi-structured. needed to address some of these challenges in one of their many AI use cases built on AWS. The dataset Our structured dataset can reside in a SQL database, datalake, or data warehouse as long as we have support for SQL.
Enterprise data architects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
What Are the Best Third-Party Data Ingestion Tools for Snowflake? Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. For those looking to migrate to Snowflake who prefer using AWS services, DMS is a great solution.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud data warehouse or datalake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance. Best Practice 5.
Read More: How Airbnb Uses Big Data and Machine Learning to Offer World-Class Service Netflix’s Big Data Infrastructure Netflix’s data infrastructure is one of the most sophisticated globally, built primarily on cloud technology. petabytes of data. What Technologies Does Netflix Use for Its Big Data Infrastructure?
Airline Reporting Corporation (ARC) sells data products to travel agencies and airlines. Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 datalake, Snowflake cloud data warehouse and Tableau (and how it can be fixed).
Data ingress and egress Snorkel enables multiple paths to bring data into and out of Snorkel Flow, including but not limited to: Upload from and download to your local computer Data connectors with common third-party datalakes such as Databricks, Snowflake, Google Big Query as well as S3, GCS, and Azure buckets.
They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. The reason this is an important skill is that ETL is a critical process for data warehousing and business intelligence.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
But how do the unfolding events impact your business? So, ARC worked to make data more accessible across domains while capturing tribal knowledge in the data catalog; this reduced the subject-matter-expertise bottlenecks during product development and accelerated higher quality analysis.
Why External Tables are Important Data Ingestion: External tables allow you to easily load data into Snowflake from various external data sources without the need to first stage the data within Snowflake. Data Integration: Snowflake supports seamless integration with other data processing systems and datalakes.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content