This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. This also led to a backlog of data that needed to be ingested.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI).
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more.
Writing data to an AWSdatalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Create VPC.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. The challenge is to assure quality.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Amazon Simple Storage Service (Amazon S3) stores the model artifacts and creates a datalake to host the inference output, document analysis output, and other datasets in CSV format. About the authors Scott Patterson is a Senior Solutions Architect at AWS. The sunburst graph below is a visualization of this classification.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. AWS Athena and S3. Limits of Athena.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources , including Amazon Athena , which supports Apache Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Azure Synapse Analytics This is the future of data warehousing. It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service. SQL Server 2019 SQL Server 2019 went Generally Available. It can be used to do distributed Machine Learning on AWS.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. It offers extensibility and integration with various data engineering tools.
Further to the acquisition, Broadcom decided to discontinue (link resides outside ibm.com) its AWS authorization to resell VMware Cloud on AWS as of 30 April 2024. As a result, AWS will no longer be able to offer new subscriptions or additional services.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. AWS Propelling Hybrid Cloud Environments. The Problem with Hybrid Cloud Environments.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
needed to address some of these challenges in one of their many AI use cases built on AWS. In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution.
Azure Synapse Analytics can be seen as a merge of Azure SQLData Warehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Azure Synapse. I think this announcement will have a very large and immediate impact.
Be sure to check out her talk, “ Don’t Go Over the Deep End: Building an Effective OSS Management Layer for Your DataLake ,” there! Managing a datalake can often feel like being lost at sea — especially when dealing with both structured and unstructured data.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you want to do the process in a low-code/no-code way, you can follow option C.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. The following screenshot shows what the upload looks like when it’s complete.
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
Configure the following scopes on your connected app: Manage user data via APIs ( api ). Perform ANSI SQL queries on Salesforce Data Cloud data (Data Cloud_query_api ). Manage Data Cloud profile data ( Data Cloud_profile_api ). Drag and drop the file, then choose Edit in SQL.
It includes sensor devices to capture vibration and temperature data, a gateway device to securely transfer data to the AWS Cloud, the Amazon Monitron service that analyzes the data for anomalies with ML, and a companion mobile app to track potential failures in your machinery.
Explore VMware Modernization Assessment In this blog, we will share how IBM Consulting can help organizations with a preference for AWS-based cloud-native technologies, leveraging the contemporary tools and modern cloud services that AWS has to offer.
IBM watsonx.data is a hybrid, governed datalake house optimized for data, analytics and AI workloads. Additionally, watsonx.data provides a flexible approach and a unified view of your data across hybrid cloud environments. Key highlights include driving business analytics with engines like Presto and Spark.
How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. When choosing a datalake, here’s something else to consider.
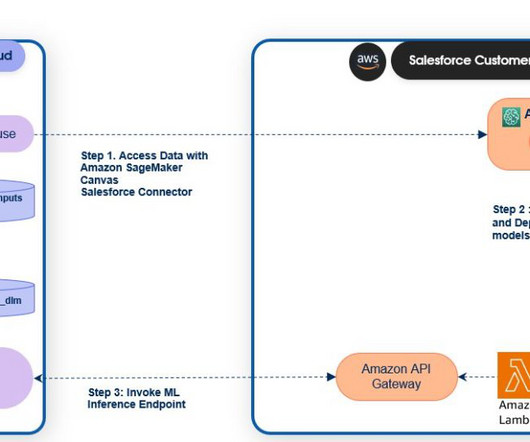
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. The endpoint will be exposed to Salesforce Data Cloud as an API through API Gateway.
External Tables Create a Shared View of the DataLake. We’ve seen external tables become popular with our customers, who use them to provide a normalized relational schema on top of their datalake. Essentially, external tables create a shared view of the datalake, a single pane of glass everyone can reference.
Snowflake-managed Iceberg table’s performance is at par with Snowflake native tables while storing the data in public cloud storage. They are Ideal for situations where the data is already stored in datalakes and do not intend to load into Snowflake but need to use the features and performance of Snowflake.
Key Skills for Data Science: A data scientist typically needs a blend of skills: Mathematics and Statistics: To understand the theoretical underpinnings of models. Programming: Often in languages like Python or R, using libraries for data manipulation, analysis, and machine learning.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Data fabric: A mostly new architecture.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content