This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideos I will admit, AWSData Wrangler has become my go-to package for developing extract, transform, and load (ETL) data pipelines and other day-to-day. The post Using AWSData Wrangler with AWS Glue Job 2.0 appeared first on Analytics Vidhya.
Prerequisites To run this step-by-step guide, you need an AWS account with permissions to SageMaker, Amazon Elastic Container Registry (Amazon ECR), AWS Identity and Access Management (IAM), and AWS CodeBuild. Complete the following steps: Sign in to the AWS Management Console and open the IAM console. Dima has a M.Sc
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
FL doesn’t require moving or sharing data across sites or with a centralized server during the model training process. In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. Participants can either choose to maintain their data in their on-premises systems or in an AWS account that they control.
The curriculum includes topics such as datamining, machine learning, and data visualization. Data Science Dojo provides both online and in-person data science bootcamps in Redmond, Washington.
Companies use Business Intelligence (BI), Data Science , and Process Mining to leverage data for better decision-making, improve operational efficiency, and gain a competitive edge. Process Mining offers process transparency, compliance insights, and process optimization.
This post is a follow-up to Generative AI and multi-modal agents in AWS: The key to unlocking new value in financial markets. They face many challenges because of the increasing variety of tools and amount of data. For structured data, the agent uses the SQL Connector and SQLAlchemy to analyze the database through Athena.
At Amazon Web Services (AWS) , not only are we passionate about providing customers with a variety of comprehensive technical solutions, but we’re also keen on deeply understanding our customers’ business processes. This method is called working backwards at AWS. Project background Milk is a nutritious beverage.
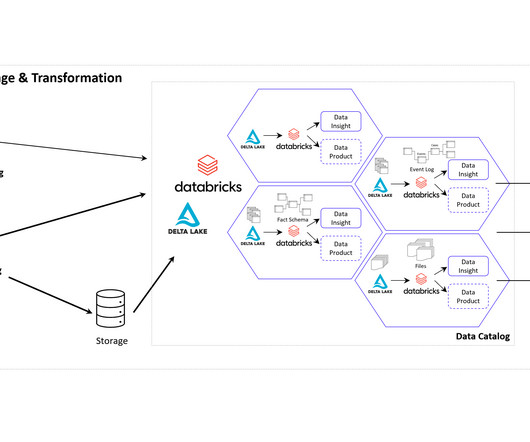
DATANOMIQ Data Mesh Cloud Architecture – This image is animated! Central data models in a cloud-based Data Mesh Architecture (e.g. on Microsoft Azure, AWS, Google Cloud Platform or SAP Dataverse) significantly improve data utilization and drive effective business outcomes. Click to enlarge!
Do Your Research with DataMining. For example, if you want to sell on AWS marketplace , you will need to see what they expect from you. If you plan to sell on AWS marketplace, or with similar online retailers, you will need to prepare your SaaS product. See if they offer guidelines or requirements to sell products.
Natural language processing, computer vision, datamining, robotics, and other competencies are strengthened in the course. Generative AI with LLMs course by AWS AND DEEPLEARNING.AI it consists of 2 courses- a Google AI course for Beginners and a Google AI course for JS Developers.
Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloud computing resources. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options.
It is useful for visualising complex data and identifying patterns and trends. Some of the key platforms used for cloud computing include: AWS (Amazon Web Services) AWS is a cloud computing platform that provides a range of services, including storage, computing, and analytics. Weka and R support this process.
Pedro Domingos, PhD Professor Emeritus, University Of Washington | Co-founder of the International Machine Learning Society Pedro Domingos is a winner of the SIGKDD Innovation Award and the IJCAI John McCarthy Award, two of the highest honors in data science and AI.
While a data analyst isn’t expected to know more nuanced skills like deep learning or NLP, a data analyst should know basic data science, machine learning algorithms, automation, and datamining as additional techniques to help further analytics. Cloud Services: Google Cloud Platform, AWS, Azure.
Pandas: A powerful library for data manipulation and analysis, offering data structures and operations for manipulating numerical tables and time series data. Scikit-learn: A simple and efficient tool for datamining and data analysis, particularly for building and evaluating machine learning models.
Scikit-learn Scikit-learn is a machine learning library in Python that is majorly used for datamining and data analysis. Similar to TensorFlow, PyTorch is also an open-source tool that allows you to develop deep learning models for free.
The end-to-end NeMo Framework includes the following key features that streamline and accelerate AI development: Data curation : NeMo Curator is a Python library that includes a suite of modules for data-mining and synthetic data generation. This solution integrates NeMo Framework 2.0
specializes in AI-powered data-mining and analytics tools designed to facilitate faster and more informed decision-making for its clients. An investment of $1,000 at the stock’s record low would have grown to nearly $5,400 over two years, yet it remains over 70% below its all-time high.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content