This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. AWS CodeArtifact , which provides a private PyPI repository so that SageMaker can use it to download necessary packages.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
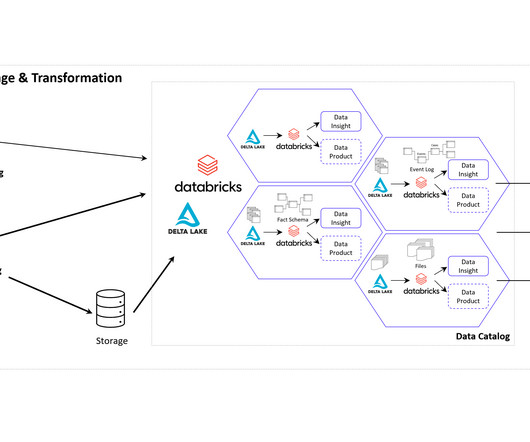
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Prerequisites Before you dive into the integration process, make sure you have the following prerequisites in place: AWS account – You’ll need an AWS account to access and use Amazon Bedrock. You can interact with Amazon Bedrock using AWS SDKs available in Python, Java, Node.js, and more.
As a customer, you rely on Amazon Web Services (AWS) expertise to be available and understand your specific environment and operations. Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data.
Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining. However, this concept on the Azure Cloud is just an example and can easily be implemented on the Google Cloud (GCP), Amazon Cloud (AWS) and now even on the SAP Cloud (Datasphere) using Databricks.
In this post, we delve into the essential security best practices that organizations should consider when fine-tuning generative AI models. Security in Amazon Bedrock Cloud security at AWS is the highest priority. Amazon Bedrock prioritizes security through a comprehensive approach to protect customer data and AI workloads.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons.
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
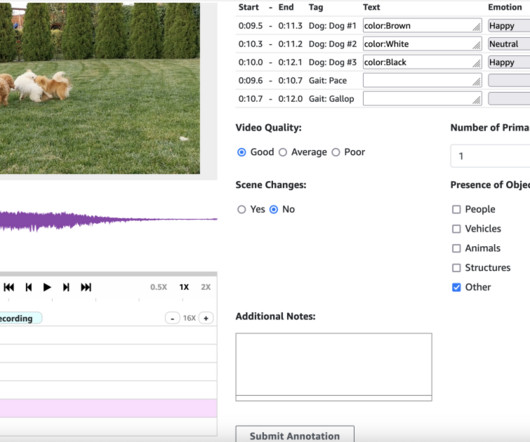
We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job. This precision helps models learn the fine details that separate natural from artificial-sounding speech. We demonstrate how to use Wavesurfer.js
The solution framework is scalable as more equipment is installed and can be reused for a variety of downstream modeling tasks. In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. The effective precision of the trained model is 91.6%.
Understanding how data warehousing works and how to design and implement a data warehouse is an important skill for a data engineer. Learn about datamodeling: Datamodeling is the process of creating a conceptual representation of data.
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with datamodeling and ETL processes.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure. Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern. IaC allows these teams to collaborate more effectively.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Secure model access – Secure, private model access using AWS PrivateLink gives controlled data transfer for inference without traversing the public internet, maintaining data privacy and helping to adhere to compliance requirements.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries. The architecture maps the different capabilities of the ML platform to AWS accounts.
You can only deploy DynamoDB on Amazon Web Services (AWS), and it does not support on-premise deployments. With DynamoDB, you are essentially locked into AWS as your cloud provider. MongoDB is deployable anywhere, and the MongoDB Atlas database-as-a-service can be deployed on AWS, Azure, and Google Cloud Platform (GCP).
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. It is known for its high performance and cost-effectiveness.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. However, this is beyond the scope of this post.
The AWS Well-Architected Framework provides a systematic way for organizations to learn operational and architectural best practices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud. These resources introduce common AWS services for IDP workloads and suggested workflows.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Solution overview Amazon Transcribe is the go-to service for speaker diarization in AWS. Hugging Face is a popular open source hub for machine learning (ML) models.
Forecast uses ML to learn not only the best algorithm for each item, but also the best ensemble of algorithms for each item, automatically creating the best model for your data. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker.
In this post, AWS collaborates with Meta’s PyTorch team to showcase how you can use Meta’s torchtune library to fine-tune Meta Llama-like architectures while using a fully-managed environment provided by Amazon SageMaker Training. cat config_l3.1_8b_lora.yaml # Model Arguments model: _component_: torchtune.models.llama3_1.lora_llama3_1_8b
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
AWS Inferentia accelerators are custom-built machine learning inference chips designed by Amazon Web Services (AWS) to optimize inference workloads on the AWS platform. The AWS Inferentia chips are designed with a focus on delivering high performance, low latency, and cost efficiency for inference workloads.
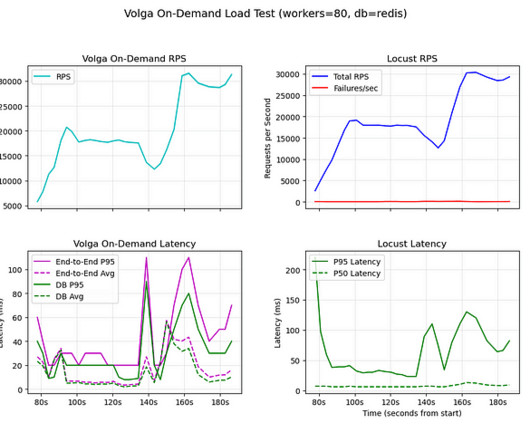
Volgas On-Demand Layer was deployed behind an AWS Application Load Balancer, serving as the primary target for Locust workers and routing requests to the EKS nodes hosting Volga pods (where the OS then distributed the load among workers within the same node/pod). Tests setup We ran load tests on an Amazon EKS cluster using t2.medium
With the rapid growth of generative artificial intelligence (AI), many AWS customers are looking to take advantage of publicly available foundation models (FMs) and technologies. This includes Meta Llama 3, Meta’s publicly available large language model (LLM).
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Add rules to interpret model scores. It’s recommended to use at least 3–6 months of data.
In this post, we explore the journey that Thomson Reuters took to enable cutting-edge research in training domain-adapted large language models (LLMs) using Amazon SageMaker HyperPod , an Amazon Web Services (AWS) feature focused on providing purpose-built infrastructure for distributed training at scale.
You can jump AWS authentication steps if you're already in AWS 's environment. Tip: Only include libraries with the most updated version in the requirements.txt file, specially the transformerslibrary as it may miss newly updated models in older versions. You can find here more about it. 1.46k [00:00<?
Launched in August 2019, Forecast predates Amazon SageMaker Canvas , a popular low-code no-code AWS tool for building, customizing, and deploying ML models, including time series forecasting models. For more information about AWS Region availability, see AWS Services by Region.
This can enable the company to leverage the data generated by its IoT edge devices to drive business decisions and gain a competitive advantage. AWS offers a three-layered machine learning stack to choose from based on your skill set and team’s requirements for implementing workloads to execute machine learning tasks.
By enabling effective management of the ML lifecycle, MLOps can help account for various alterations in data, models, and concepts that the development of real-time image recognition applications is associated with. At-scale, real-time image recognition is a complex technical problem that also requires the implementation of MLOps.
Prerequisites The following are prerequisites for completing the walkthrough in this post: An AWS account Familiarity with SageMaker concepts, such as an Estimator, training job, and HPO job Familiarity with the Amazon SageMaker Python SDK Python programming knowledge Implement the solution The full code is available in the GitHub repo.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content