This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
Text-to-SQL empowers people to explore data and draw insights using natural language, without requiring specialized database knowledge. Amazon Web Services (AWS) has helped many customers connect this text-to-SQL capability with their own data, which means more employees can generate insights.
Their role is crucial in understanding the underlying data structures and how to leverage them for insights. Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Programming Questions Data science roles typically require knowledge of Python, SQL, R, or Hadoop.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This can be overwhelming for nontechnical users who lack proficiency in SQL. This application allows users to ask questions in natural language and then generates a SQL query for the users request.
So why using IaC for Cloud Data Infrastructures? This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure. Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern.
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
With the rapid growth of generative artificial intelligence (AI), many AWS customers are looking to take advantage of publicly available foundation models (FMs) and technologies. This includes Meta Llama 3, Meta’s publicly available large language model (LLM).
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. It is known for its high performance and cost-effectiveness.
Model Development and Validation: Building machine learning models tailored to business problems such as customer churn prediction, fraud detection, or demand forecasting. Validation techniques ensure models perform well on unseen data. Data Manipulation: Pandas, NumPy, dplyr. Big Data: Apache Hadoop, Apache Spark.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. The following screenshot shows what the upload looks like when it’s complete.
You can only deploy DynamoDB on Amazon Web Services (AWS), and it does not support on-premise deployments. With DynamoDB, you are essentially locked into AWS as your cloud provider. MongoDB is deployable anywhere, and the MongoDB Atlas database-as-a-service can be deployed on AWS, Azure, and Google Cloud Platform (GCP).
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Forecast uses ML to learn not only the best algorithm for each item, but also the best ensemble of algorithms for each item, automatically creating the best model for your data. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements.
The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode. However, Snowflake runs better on Azure than it does on AWS – so even though it’s not the ideal situation, Microsoft still sees Azure consumption when organizations host Snowflake on Azure.
Advanced tools like AWS QuickSight support large datasets and growing businesses. Microsoft Power BI is a comprehensive business intelligence (BI) tool designed to help organisations turn raw data into meaningful insights. It supports various Visualisations and can connect to various SQL-based data sources.
Lookers strength lies in its ability to connect to a wide variety of data sources. Examples include SQl, DWH, and Cloud based systems (Google Bigquery). With Looker, you can share dashboards and visualizations seamlessly across teams, providing stakeholders with access to real-time data.
The answer probably depends more on the complexity of your queries than the connectedness of your data. Relational databases (with recursive SQL queries), document stores, key-value stores, etc., Multi-model databases combine graphs with two other NoSQL datamodels – document and key-value stores.
Understand the fundamentals of data engineering: To become an Azure Data Engineer, you must first understand the concepts and principles of data engineering. Knowledge of datamodeling, warehousing, integration, pipelines, and transformation is required. Hands-on experience working with SQLDW and SQL-DB.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Scalability: Designed to handle large volumes of data efficiently.
Estimates start at around $2 million, ranging up to $12 million or so for the newest (and largest) models. Facebook/Meta’s LLaMA, which is smaller than GPT-3 and GPT-4, is thought to have taken roughly one million GPU hours to train, which would cost roughly $2 million on AWS. However, very few companies need to build their own models.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. Uses secure protocols for data security. Cons Limited connectors.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Support for Numerous Data Sources: Fivetran supports over 200 data sources, including popular databases, applications, and cloud platforms like Salesforce, Google Analytics, SQL Server, Snowflake, and many more. Additionally, unsupported data sources can be integrated using Fivetran’s cloud function connectors.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. In contrast, such traditional query languages struggle to interpret unstructured data. This text has a lot of information, but it is not structured.
It’s about more than just looking at one project; dbt Explorer lets you see the lineage across different projects, ensuring you can track your data’s journey end-to-end without losing track of the details. Figure 3: Multi-project lineage graph with dbt explorer. Source: Dave Connor's Loom.
Model Deployment and Serving Platforms Some of the most popular tools for development, serving and scaling are as follows: Amazon SageMaker Developed by Amazon Web Services (AWS) , Amazon Sagemaker is a fully managed machine learning service that allows developers and data scientists to build, train, and deploy machine learning models at scale.
You see them all the time with a headline like: “data science, machine learning, Java, Python, SQL, or blockchain, computer vision.” It’s almost like a specialized data processing and storage solution. For example, you can use BigQuery , AWS , or Azure. How awful are they?” It’s two things.
Uncomfortable reality: In the era of large language models (LLMs) and AutoML, traditional skills like Python scripting, SQL, and building predictive models are no longer enough for data scientist to remain competitive in the market. Programming expertise: A medium/high proficiency in Python and SQL is enough.
With the Amazon Bedrock serverless experience, you can experiment with and evaluate top foundation models (FMs) for your use cases, privately customize them with your data using techniques such as fine-tuning and RAG, and build agents that run tasks using enterprise systems and data sources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




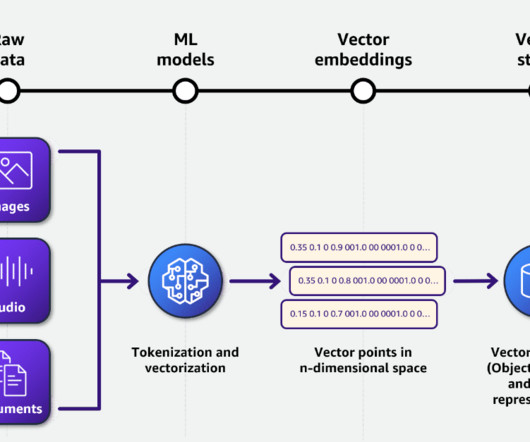


















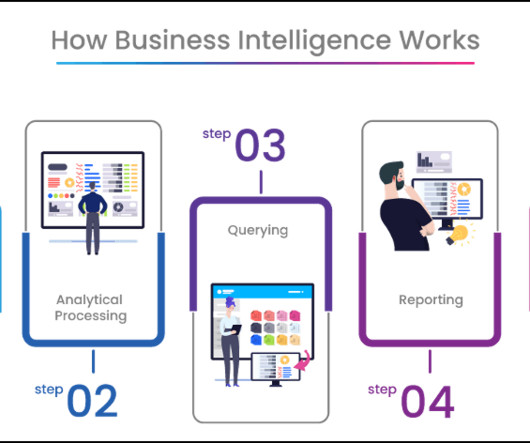






















Let's personalize your content