This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons.
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface. compute.internal.
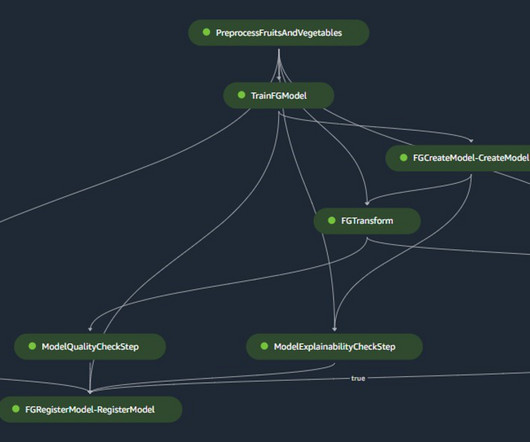
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. The following diagram illustrates the solution architecture.
Prerequisites The following are prerequisites for completing the walkthrough in this post: An AWS account Familiarity with SageMaker concepts, such as an Estimator, training job, and HPO job Familiarity with the Amazon SageMaker Python SDK Python programming knowledge Implement the solution The full code is available in the GitHub repo.
While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. Why did something break?
Hyperparameter overview When training any machine learning (ML) model, you are generally dealing with three types of data: input data (also called the training data), model parameters, and hyperparameters. You use the input data to train your model, which in effect learns your model parameters.
Combining SageMaker with DagsHub provides a single source of truth to the project, managed in one place, including code, data, models, experiments, annotations, and now - computing resources and automation. Amazon SageMaker is a cloud-based machine learning platform provided by Amazon Web Services (AWS).
However, Snowflake runs better on Azure than it does on AWS – so even though it’s not the ideal situation, Microsoft still sees Azure consumption when organizations host Snowflake on Azure. Creating an efficient datamodel can be the difference between having good or bad performance, especially when using DirectQuery.
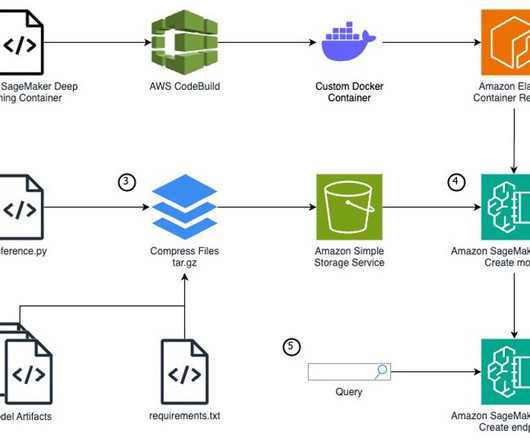
Train and tune a custom model based on one of the major frameworks like Scikit-learn, TensorFlow, or PyTorch. AWS provides a selection of pre-made Docker images for this purpose. As mentioned before, if you have the chance, open the notebook and run the code cells step by step to create the artifacts in your AWS environment.
As a result, we’ve seen it move from a mid-tier customer Data Platform to the Leader position in the 2023 Gartner® Magic Quadrant™ Finally, we can say definitively that Cloudera Data Platform (CDP) is the most robust foundation as a comprehensive data solution inside the Salesforce ecosystem.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. AWS Glue AWS Glue is Amazon’s serverless ETL tool.
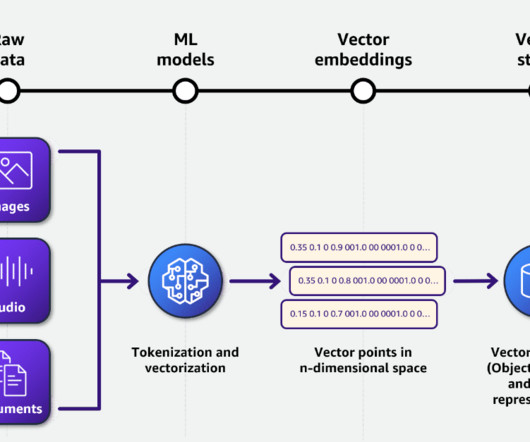
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
Mikiko Bazeley: You definitely got the details correct. I definitely don’t think I’m an influencer. It will store the features (including definitions and values) and then serve them. It’s almost like a very specialized data storage solution. For example, you can use BigQuery , AWS , or Azure.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
In this post, we highlight how the AWS Generative AI Innovation Center collaborated with SailPoint Technologies to build a generative AI-based coding assistant that uses Anthropic’s Claude Sonnet on Amazon Bedrock to help accelerate the development of software as a service (SaaS) connectors.
The following figure shows the framework to evaluate LLMs and LLM-based services: Amazon SageMaker Clarify LLM evaluation is an open-source Foundation Model Evaluation (FMEval) library developed by AWS to help customers easily evaluate LLMs. Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in Netherlands.
It’s about more than just looking at one project; dbt Explorer lets you see the lineage across different projects, ensuring you can track your data’s journey end-to-end without losing track of the details. Version Tracking: Displays version information for models, indicating whether they are prerelease, latest, or outdated.
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. diagram Using ChatGPT to build system diagrams — Part II Generate C4 diagrams using mermaid.js
Enter dbt dbt provides SQL-centric transformations for your datamodeling and transformations, which is efficient for scrubbing and transforming your data while being an easy skill set to hire for and develop within your teams. It should also enable easy sharing of insights across the organization.
In such cases, SageMaker allows you to extend its functionality by creating custom container images and defining custom modeldefinitions. This approach enables you to package your model artifacts, dependencies, and inference code into a container image, which you can deploy as a SageMaker endpoint for real-time inference.
The security measures are inherently integrated into the AWS services employed in this architecture. We used a dataset that consisted of 30 labeled data points and 100,000 unlabeled test data points. If youre interested in working with the AWS Generative AI Innovation Center, please reach out.
JSONs inherently structured format allows for clear and organized representation of complex data such as table schemas, column definitions, synonyms, and sample queries. This structure facilitates quick parsing and manipulation of data in most programming languages, reducing the need for custom parsing logic.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content