This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
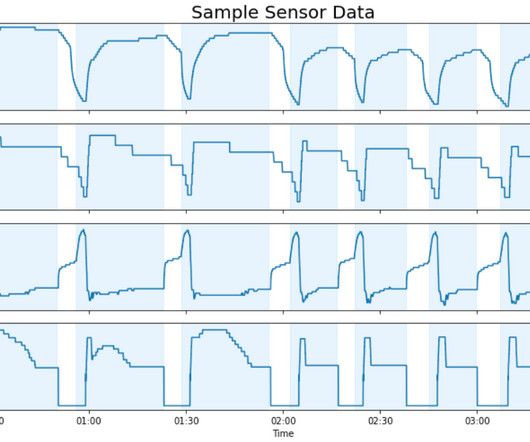
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset datamodel. Text, images, audio, and videos are common examples of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows. Metaflow’s coherent APIs simplify the process of building real-world ML/AI systems in teams.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
In order to improve our equipment reliability, we partnered with the Amazon Machine Learning Solutions Lab to develop a custom machine learning (ML) model capable of predicting equipment issues prior to failure. Our teams developed a framework for processing over 50 TB of historical sensor data and predicting faults with 91% precision.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
In this post, we delve into the essential security best practices that organizations should consider when fine-tuning generative AI models. Security in Amazon Bedrock Cloud security at AWS is the highest priority. Amazon Bedrock prioritizes security through a comprehensive approach to protect customer data and AI workloads.
Growth Outlook: Companies like Google DeepMind, NASA’s Jet Propulsion Lab, and IBM Research actively seek research data scientists for their teams, with salaries typically ranging from $120,000 to $180,000. With the continuous growth in AI, demand for remote data science jobs is set to rise.
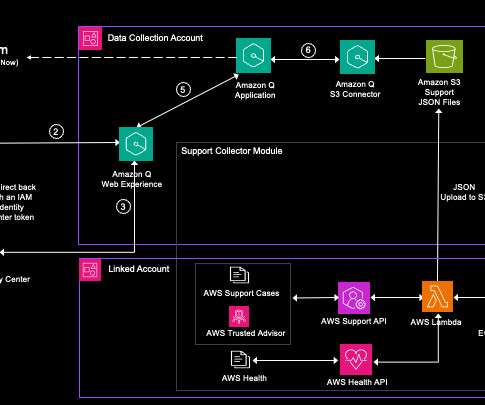
As a customer, you rely on Amazon Web Services (AWS) expertise to be available and understand your specific environment and operations. Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
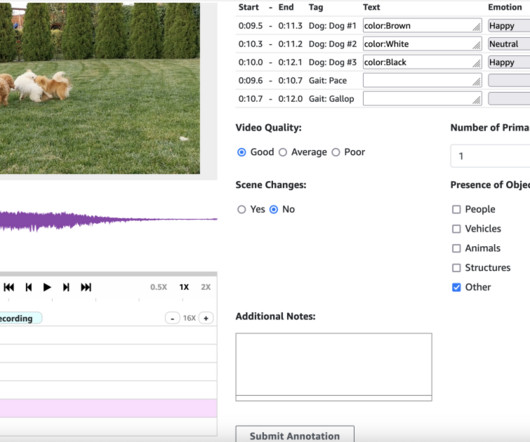
We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job. This precision helps models learn the fine details that separate natural from artificial-sounding speech. We demonstrate how to use Wavesurfer.js
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Add rules to interpret model scores. Deploy the API to make predictions.
The AWS Well-Architected Framework provides a systematic way for organizations to learn operational and architectural best practices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud. These resources introduce common AWS services for IDP workloads and suggested workflows.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Solution overview Amazon Transcribe is the go-to service for speaker diarization in AWS. Hugging Face is a popular open source hub for machine learning (ML) models.
The key reasons that influenced this decision were: Managed service – Amazon Bedrock is a fully serverless offering that offers a choice of industry leading FMs without provisioning infrastructure, procuring GPUs around the clock, or configuring ML frameworks.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
Amazon Forecast is a fully managed service that uses statistical and machine learning (ML) algorithms to deliver highly accurate time series forecasts. With SageMaker Canvas, you get faster model building , cost-effective predictions, advanced features such as a model leaderboard and algorithm selection, and enhanced transparency.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. However, this is beyond the scope of this post.
In this post, AWS collaborates with Meta’s PyTorch team to showcase how you can use Meta’s torchtune library to fine-tune Meta Llama-like architectures while using a fully-managed environment provided by Amazon SageMaker Training. SageMaker Training is a comprehensive, fully managed ML service that enables scalable model training.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. All of this is possible without having to write or compile code.
Fortunately, there are many tools for ML evaluation and frameworks designed to support responsible AI development and evaluation. But let’s first take a look at some of the tools for ML evaluation that are popular for responsible AI. It includes methods for addressing fairness issues by adjusting training data, models, or outputs.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve.
Thomson Reuters , a global content and technology-driven company, has been using artificial intelligence and machine learning (AI/ML) in its professional information products for decades. LLMs disrupt the industry Towards the end of 2022, groundbreaking LLMs were released that realized drastic improvements over previous model capabilities.
Source: Author Introduction Machine learning (ML) models, like other software, are constantly changing and evolving. Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects.
AutoML allows you to derive rapid, general insights from your data right at the beginning of a machine learning (ML) project lifecycle. Understanding up front which preprocessing techniques and algorithm types provide best results reduces the time to develop, train, and deploy the right model.
This can enable the company to leverage the data generated by its IoT edge devices to drive business decisions and gain a competitive advantage. AWS offers a three-layered machine learning stack to choose from based on your skill set and team’s requirements for implementing workloads to execute machine learning tasks.
AWS Inferentia accelerators are custom-built machine learning inference chips designed by Amazon Web Services (AWS) to optimize inference workloads on the AWS platform. The AWS Inferentia chips are designed with a focus on delivering high performance, low latency, and cost efficiency for inference workloads.
Creating high-performance machine learning (ML) solutions relies on exploring and optimizing training parameters, also known as hyperparameters. It provides key functionality that allows you to focus on the ML problem at hand while automatically keeping track of the trials and results. We use a Random Forest from SkLearn.
You can jump AWS authentication steps if you're already in AWS 's environment. Tip: Only include libraries with the most updated version in the requirements.txt file, specially the transformerslibrary as it may miss newly updated models in older versions. You can find here more about it. 1.46k [00:00<?
In this post, we show you how to train the 7-billion-parameter BloomZ model using just a single graphics processing unit (GPU) on Amazon SageMaker , Amazon’s machine learning (ML) platform for preparing, building, training, and deploying high-quality MLmodels. Then, it starts the training job.
With the rapid growth of generative artificial intelligence (AI), many AWS customers are looking to take advantage of publicly available foundation models (FMs) and technologies. This includes Meta Llama 3, Meta’s publicly available large language model (LLM).
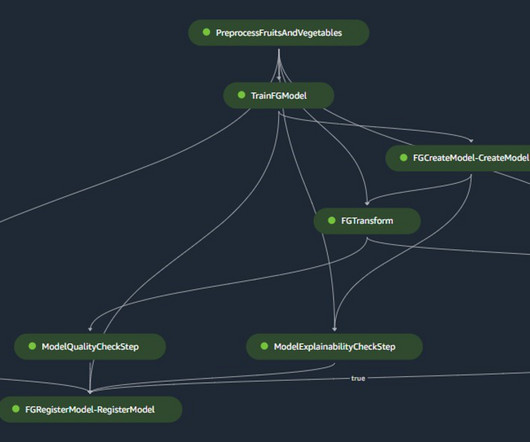
It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs). In this post, we share an ML infrastructure architecture that uses SageMaker HyperPod to support research team innovation in video generation.
Hyperparameter overview When training any machine learning (ML) model, you are generally dealing with three types of data: input data (also called the training data), model parameters, and hyperparameters. You use the input data to train your model, which in effect learns your model parameters.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. How do I develop my body of work?
Data science teams currently struggle with managing multiple experiments and models and need an efficient way to store, retrieve, and utilize details like model versions, hyperparameters, and performance metrics. MLmodel versioning: where are we at? The short answer is we are in the middle of a data revolution.
The role of Python is not just limited to Data Science. It’s a universal programming language that finds application in different technologies like AI, ML, Big Data and others. DataModeling : Using libraries like scikit-learn and Tensorflow, one can build and evaluate predictive models.
All you do is share data along with labeling requirements, and Ground Truth Plus sets up and manages your data labeling workflow based on these requirements. From there, an expert workforce that is trained on a variety of machine learning (ML) tasks labels your data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














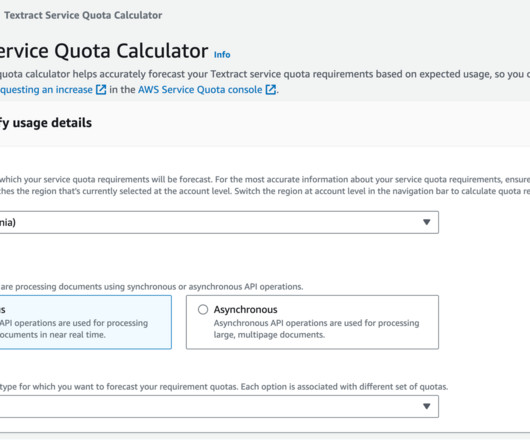
























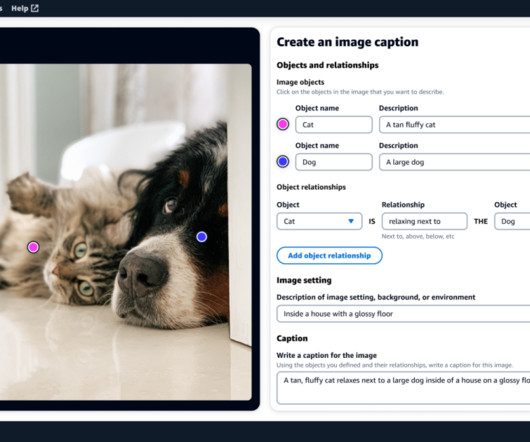






Let's personalize your content