This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
According to International Data Corporation (IDC), stored data is set to increase by 250% by 2025 , with data rapidly propagating on-premises and across clouds, applications and locations with compromised quality. This situation will exacerbate datasilos, increase costs and complicate the governance of AI and data workloads.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Moreover, ETL pipelines play a crucial role in breaking down datasilos and establishing a single source of truth.
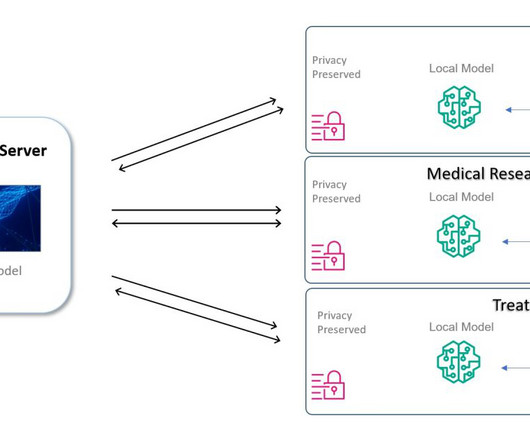
This approach can help heart stroke patients, doctors, and researchers with faster diagnosis, enriched decision-making, and more informed, inclusive research work on stroke-related health issues, using a cloud-native approach with AWS services for lightweight lift and straightforward adoption. Stroke victims can lose around 1.9
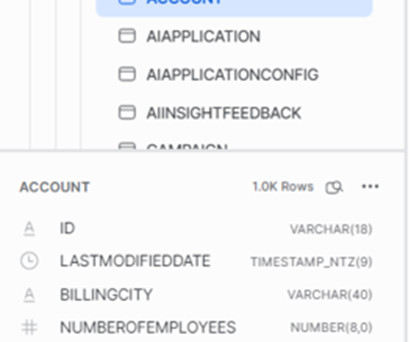
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. The Salesforce Sync Out connector moves Salesforce data directly into Snowflake, simplifying the datapipeline and reducing latency.
To achieve trusted AI outcomes, you need to ground your approach in three crucial considerations related to data’s completeness, quality, and context. You need to break down datasilos and integrate critical data from all relevant sources. Fuel your AI applications with trusted data to power reliable results.
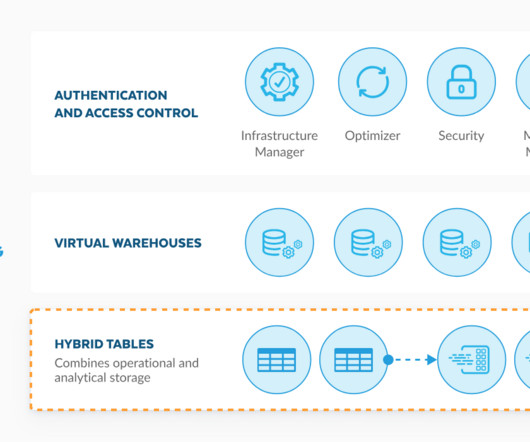
However, it is now available in public preview in specific AWS regions, excluding trial accounts. The real benefit of utilizing Hybrid tables is that they bring transactional and analytical data together in a single platform. Hybrid tables can streamline datapipelines, reduce costs, and unlock deeper insights from data.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of datasilos or the need to copy data between systems. Environments are the actual data infrastructure behind a project.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content