This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
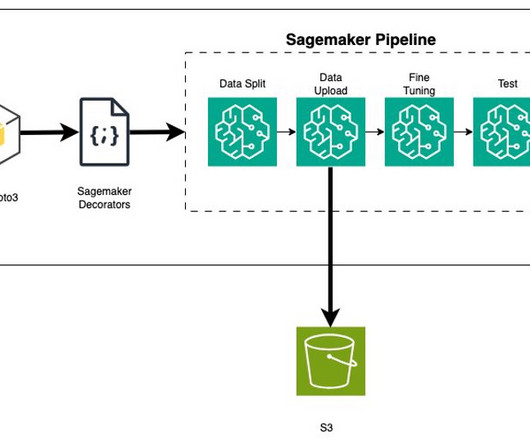
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway. Leave us a comment and we will be glad to collaborate.
Large language models can transform how we bridge the gap between business questions and actionable data insights. For most organizations, this gap remains stubbornly wide, with business teams trapped in endless cycles—decoding metric definitions and hunting for the correct data sources to manually craft each SQL query.
Amazon Bedrock Agents is instrumental in customization and tailoring apps to help meet specific project requirements while protecting private data and securing their applications. These agents work with AWS managed infrastructure capabilities and Amazon Bedrock , reducing infrastructure management overhead.
This creates a seamless bridge between learning about metrics and visualizing them—users can start with simple queries about metric definitions and quickly transition to data exploration without reformulating their requests. Lakshdeep Vatsa is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
Designing the prompt Before starting any scaled use of generative AI, you should have the following in place: A clear definition of the problem you are trying to solve along with the end goal. If prompted, set up a user profile for SageMaker Studio by providing a user name and specifying AWS Identity and Access Management (IAM) permissions.
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
What we like most about Openflow is that it simplifies data ingestion from multiple sources and accelerates Snowflake customers’ success by eliminating the need for third-party ingestion tools, enabling quick prototyping, and supporting reusable datapipelines. This will be the starting point of the flow.
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Machine Learning Operations (MLOps): Overview, Definition, and Architecture (by Kreuzberger, et al., AIIA MLOps blueprints.
The full code can be found on the aws-samples-for-ray GitHub repository. It integrates smoothly with other data processing libraries like Spark, Pandas, NumPy, and more, as well as ML frameworks like TensorFlow and PyTorch. This allows building end-to-end datapipelines and ML workflows on top of Ray.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. Much of what we found was to be expected, though there were definitely a few surprises. You’ll see specific tools in the next section.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Hello from our new, friendly, welcoming, definitely not an AI overlord cookie logo! Some projects manage this folder like the data folder and sync it to a canonical store (e.g., AWS S3) separately from source code. The second is to provide a directed acyclic graph (DAG) for datapipelining and model building.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Read Further: Azure Data Engineer Jobs.
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. The Salesforce Sync Out connector moves Salesforce data directly into Snowflake, simplifying the datapipeline and reducing latency.
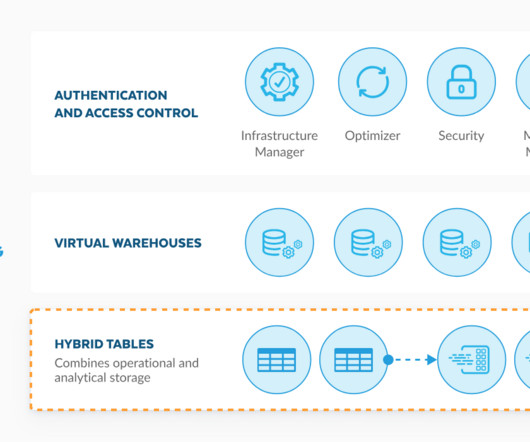
However, it is now available in public preview in specific AWS regions, excluding trial accounts. The real benefit of utilizing Hybrid tables is that they bring transactional and analytical data together in a single platform. Hybrid tables can streamline datapipelines, reduce costs, and unlock deeper insights from data.
The generative AI solutions from GCP Vertex AI, AWS Bedrock, Azure AI, and Snowflake Cortex all provide access to a variety of industry-leading foundational models. It is definitely an exciting time as the open-source community enhances and builds out these frameworks, but they are still being refined with best practices and new features.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do data analysis BI report generation/data analysis In BI/data analysis world, people usually need to query data (small/large).
However, Snowflake runs better on Azure than it does on AWS – so even though it’s not the ideal situation, Microsoft still sees Azure consumption when organizations host Snowflake on Azure. The most commonly used functions that you lose when using DirectQuery are Time Intelligence functions such as TOTALYTD, DATESYTD, and EOMONTH.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Environments are the actual data infrastructure behind a project.
Key Advantages of Governance Simplified Change Managment: The complexity of the underlying systems is abstracted away from the user, allowing them to simply and declaratively build and change datapipelines. This reduces risk, enables automation, and allows for less technical users to assist in the development process.
Prior to that, I spent a couple years at First Orion - a smaller data company - helping found & build out a data engineering team as one of the first engineers. We were focused on building datapipelines and models to protect our users from malicious phonecalls. Some: React, IoT, bit o elm, ML, LLM ops and auotmation.
On the backend we're using 100% Go with AWS primitives. Stack : Python/Django, JavaScript, VueJS, PostgreSQL, Snowflake, Docker, Git, AWS, AI/LLM integrations (OpenAI & Gemini). All on Serverless AWS. Designing AI datapipelines to process billions of data points.
Internally within Netflix’s engineering team, Meson was built to manage, orchestrate, schedule, and execute workflows within ML/Datapipelines. Meson managed the lifecycle of ML pipelines, providing functionality such as recommendations and content analysis, and leveraged the Single Leader Architecture.
reply jasondc 10 hours ago | parent | prev | next [–] Really cool, definitely donating to a few products! This is a great idea and definitely fits into the vision. reply ttd 11 hours ago | root | parent | next [–] Some type of programmatic diagram creation is definitely something I'm interested in supporting. Best of luck.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content