This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
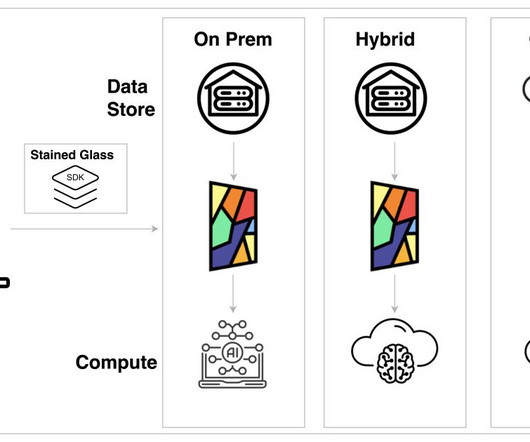
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. This is covered in detail later in the post.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. You can also find Tecton at AWS re:Invent.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
However, they can’t generalize well to enterprise-specific questions because, to generate an answer, they rely on the public data they were exposed to during pre-training. However, the popular RAG design pattern with semantic search can’t answer all types of questions that are possible on documents.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
Consider the following picture, which is an AWS view of the a16z emerging application stack for large language models (LLMs). This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly.
By using the natural language processing and generation capabilities of generative AI, the chat assistant can understand user queries, retrieve relevant information from various data sources, and provide tailored, contextual responses. See Data source connectors for a list of supported data source connectors for Amazon Kendra.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
To enable quick information retrieval, we use Amazon Kendra as the index for these documents. Amazon Kendra uses natural language processing (NLP) to understand user queries and find the most relevant documents. The following figures shows the step-by-step procedure of how a query is processed for the text-to-SQL pipeline.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc.
Better documentation with more examples , clearer explanations of the choices and tools, and a more modern look and feel. Find the latest at [link] (the old documentation will redirect here shortly). Some projects manage this folder like the data folder and sync it to a canonical store (e.g., AWS S3) separately from source code.
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance datapipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. Step 2: Create a Data Catalog table.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. For more information on how to configure an Amazon DocumentDB connection, see the Connect to a database stored in AWS.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
AWS is especially well suited to provide enterprises the tools necessary for deploying LLMs at scale to enable critical decision-making. In their implementation of generative AI technology, enterprises have real concerns about data exposure and ownership of confidential information that may be sent to LLMs.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc.
After reading a few blog posts and DJL’s official documentation, we were sure DJL would provide the best solution to our problem. It also includes support for new hardware like ARM (both in servers like AWS Graviton and laptops with Apple M1 ) and AWS Inferentia. The following diagram outlines the workflow of the DJL solution.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
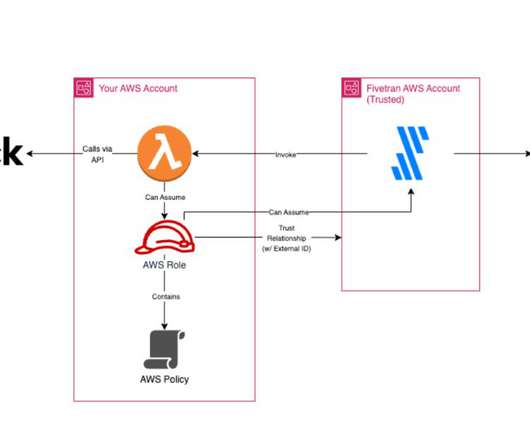
The phData team achieved a major milestone by successfully setting up a secure end-to-end datapipeline for a substantial healthcare enterprise. Functions – Fivetran’s Function connector allows you to code custom data connectors using the following cloud provider services: AWS Lambda, Azure Functions, and Google Cloud Functions.
Implementing proper version control in ML pipelines is essential for efficient management of code, data, and models by ensuring reproducibility and collaboration. Reproducibility ensures that experiments can be reliably reproduced by tracking changes in code, data, and model hyperparameters.
It supports batch and real-time data processing, making it a preferred choice for large enterprises with complex data workflows. Informatica’s AI-powered automation helps streamline datapipelines and improve operational efficiency. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
For enterprises, the value-add of applications built on top of large language models is realized when domain knowledge from internal databases and documents is incorporated to enhance a model’s ability to answer questions, generate content, and any other intended use cases.
Sources of Data in the Pile The Pile draws from a variety of sources to ensure richness and reliability. Open-access books, encyclopedias, and government documents offer well-structured, factual content. It also features data from novels, legal documents, and medical texts.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Read Further: Azure Data Engineer Jobs.
Integration : Can it connect with existing systems like AWS, Azure, or Google Cloud? Real-time processing is essential for applications requiring immediate data insights. Support : Are there resources available for troubleshooting, such as documentation, forums, or customer support?
In a previous post , we talked about setting up all the components necessary to create a pipeline for ingesting data from a custom source into the Snowflake Data Cloud using Fivetran. This involved setting up an AWS Lambda connector in Fivetran, which would query data from the Lambda function and pass it back to Fivetran.
This section outlines key practices focused on automation, monitoring and optimisation, scalability, documentation, and governance. Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
Solution overview SageMaker algorithms have fixed input and output data formats. But customers often require specific formats that are compatible with their datapipelines. Option A In this option, we use the inference pipeline feature of SageMaker hosting. Dhawal Patel is a Principal Machine Learning Architect at AWS.
When building your Processing Docker image, don't place any data required by your container in these directories. The sample bash script will take care of all the AWS-related authentication, create a repository named sm-semantic-similarity, tag it and finally push it to the Amazon ECR repository. docker build -t ${algorithm_name}.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination.
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. See the Salesforce documentation for more information. What is Salesforce Sync Out? Click Next. Select the Snowflake Output Connector.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content