This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. Lets assume that the question What date will AWS re:invent 2024 occur? If the question was Whats the schedule for AWS events in December?,
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build datapipelines to move data from Amazon Aurora to Amazon Redshift.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. You can also find Tecton at AWS re:Invent.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. AWS CodeBuild is a fully managed continuous integration service in the cloud.
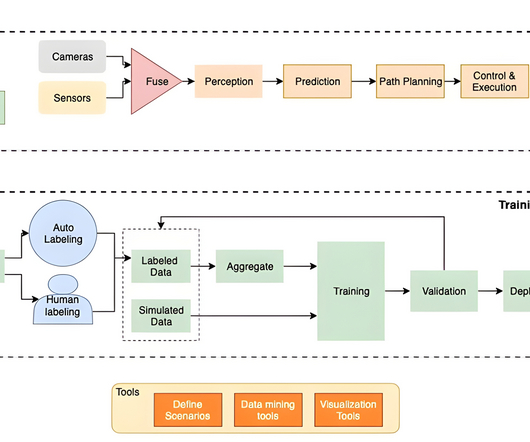
At the higher levels of automation (Level 2 and above), the AD system performs multiple functions: Data collection – The AV system gathers information about the vehicle’s surroundings in real time with centimeter accuracy. AV systems fuse data from the devices that are integrated together to build a comprehensive perception.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. For more information, see Zeta Global’s home page. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker. These types of data are historical raw data from an ML perspective.
Consider the following picture, which is an AWS view of the a16z emerging application stack for large language models (LLMs). This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). Control plane and data plane implementation SnapLogic’s Agent Creator platform follows a decoupled architecture, separating the control plane and data plane for enhanced security and scalability.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Recent improvements in Generative AI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval. Given the data sources, LLMs provided tools that would allow us to build a Q&A chatbot in weeks, rather than what may have taken years previously, and likely with worse performance.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. These skilled professionals are tasked with building and deploying models that improve the quality and efficiency of BMW’s business processes and enable informed leadership decisions.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. The attempt is disadvantaged by the current focus on data cleaning, diverting valuable skills away from building ML models for sensor calibration.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. For more information, refer to Preview: Use Amazon SageMaker to Build, Train, and Deploy ML Models Using Geospatial Data.
Furthermore, the democratization of AI and ML through AWS and AWS Partner solutions is accelerating its adoption across all industries. For example, a health-tech company may be looking to improve patient care by predicting the probability that an elderly patient may become hospitalized by analyzing both clinical and non-clinical data.
Despite the proliferation of information and data in business environments, employees and stakeholders often find themselves searching for information and struggling to get their questions answered quickly and efficiently. See Data source connectors for a list of supported data source connectors for Amazon Kendra.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Their task is to construct and oversee efficient datapipelines.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
AWS is especially well suited to provide enterprises the tools necessary for deploying LLMs at scale to enable critical decision-making. In their implementation of generative AI technology, enterprises have real concerns about data exposure and ownership of confidential information that may be sent to LLMs.
SageMaker requires that the training data for an ML model be present either in Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS) or Amazon FSx for Lustre (for more information, refer to Access Training Data). Store your Snowflake account credentials in AWS Secrets Manager.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
By walking through this specific implementation, we aim to showcase how you can adapt batch inference to suit various data processing needs, regardless of the data source or nature. Prerequisites To use the batch inference feature, make sure you have satisfied the following requirements: An active AWS account.
Kafka And ETL Processing: You might be using Apache Kafka for high-performance datapipelines, stream various analytics data, or run company critical assets using Kafka, but did you know that you can also use Kafka clusters to move data between multiple systems. 5 Key Comparisons in Different Apache Kafka Architectures.
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
Today, personally identifiable information (PII) is everywhere. It refers to any data or information that can be used to identify a specific individual. It’s a critical component of modern data management and cybersecurity practices. PII is in emails, slack messages, videos, PDFs, and so on.
In this post, we describe how AWS Partner Airis Solutions used Amazon Lookout for Equipment , AWS Internet of Things (IoT) services, and CloudRail sensor technologies to provide a state-of-the-art solution to address these challenges. It’s an easy way to run analytics on IoT data to gain accurate insights.
This empowers you to make well-informed and responsive decisions based on the most recent data. By following these steps, businesses can harness the power of robust time series forecasting to make informed decisions and stay ahead in a rapidly changing environment. The following diagram illustrates the inference pipeline.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
which play a crucial role in building end-to-end datapipelines, to be included in your CI/CD pipelines. These practices also establish a unified and reliable source of information for all changes, ensuring that the history of changes is readily accessible for auditing purposes.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline.
By providing authorities with the tools and insights they need to make informed decisions about environmental and social impact, Gramener is playing a vital role in building a more sustainable future. Discover the potential of integrating Earth observation data in your sustainability projects with SageMaker.
Data contains information, and information can be used to predict future behaviors, from the buying habits of customers to securities returns. The financial services industry (FSI) is no exception to this, and is a well-established producer and consumer of data and analytics.
The full code can be found on the aws-samples-for-ray GitHub repository. It integrates smoothly with other data processing libraries like Spark, Pandas, NumPy, and more, as well as ML frameworks like TensorFlow and PyTorch. This allows building end-to-end datapipelines and ML workflows on top of Ray.
DagsHub integration with DVC includes a fully configured remote object storage managed by DVC, showing and diffing DVC tracked files hosted on DagsHub Storage or S3 compatible, and DataPipeline visualization. This means you can see your data and diff it, next to your code file, and create a single source of truth for your project.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. Certified Information Systems Security Professional a.k.a.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content