Build a Serverless News Data Pipeline using ML on AWS Cloud
KDnuggets
NOVEMBER 18, 2021
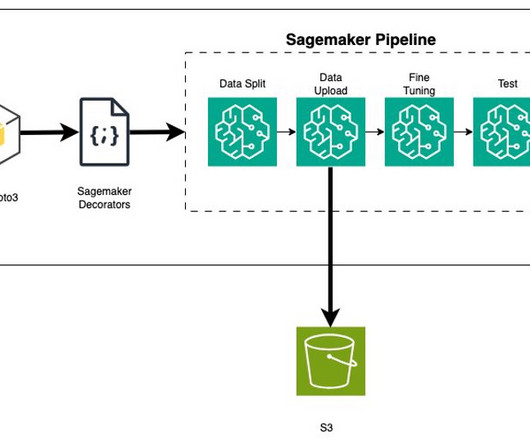
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
 AWS Data Pipeline Python
AWS Data Pipeline Python 
KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.

Analytics Vidhya
AUGUST 3, 2021
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Analytics Vidhya
APRIL 23, 2024
It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring data pipelines. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.

KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.

AWS Machine Learning Blog
JANUARY 7, 2025
The translation playground could be adapted into a scalable serverless solution as represented by the following diagram using AWS Lambda , Amazon Simple Storage Service (Amazon S3), and Amazon API Gateway. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python.

How to Learn Machine Learning
DECEMBER 24, 2024
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!

Data Science Dojo
JULY 6, 2023
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS).

Expert insights. Personalized for you.





































Let's personalize your content