This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
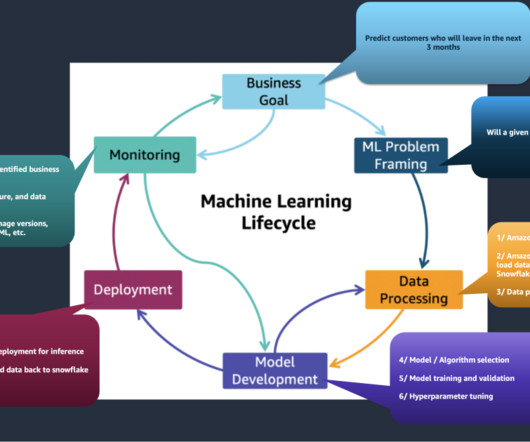
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes. Importance of qualitydata in fine-tuning Dataquality is paramount in the fine-tuning process.
We made this process much easier through Snorkel Flow’s integration with Amazon SageMaker and other tools and services from Amazon Web Services (AWS). At its core, Snorkel Flow empowers data scientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Businesses face significant hurdles when preparingdata for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface. Choose Create stack.
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account. Choose Data Wrangler in the navigation pane.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. million per year.
In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. based single sign-on (SSO) methods, such as AWS IAM Identity Center.
Then, they can quickly profile data using Data Wrangler visual interface to evaluate dataquality, spot anomalies and missing or incorrect data, and get advice on how to deal with these problems. For each option, we deploy a unique stack of AWS CloudFormation templates.
Ensuring dataquality, governance, and security may slow down or stall ML projects. Through ML EBA, experienced AWS ML subject matter experts work side by side with your cross-functional team to provide prescriptive guidance, remove blockers, and build organizational capability for a continued ML adoption.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few. We will introduce a custom classifier training pipeline that can be deployed in your AWS account with few clicks.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care. Data Management – Efficient data management is crucial for AI/ML platforms.
We explain the metrics and show techniques to deal with data to obtain better model performance. Prerequisites If you would like to implement all or some of the tasks described in this post, you need an AWS account with access to SageMaker Canvas. Let’s try to improve the model performance using a data-centric approach.
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. Select Other type of secret. Save the secret and note the ARN of the secret.
We made this process much easier through Snorkel Flows integration with Amazon SageMaker and other tools and services from Amazon Web Services (AWS). At its core, Snorkel Flow empowers data scientists and domain experts to encode their knowledge into labeling functions, which are then used to generate high-quality training datasets.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML. Choose Create.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering. However, generalizing feature engineering is challenging.
We use a test datapreparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. When fine-tuning is complete, this notebook is run using run magic and prepares a test dataset for sample inference with the fine-tuned model. train sst2.train train sst2.train
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. This process involves extracting data from multiple sources, transforming it into a consistent format, and loading it into the data warehouse. ETL is vital for ensuring dataquality and integrity.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality.
DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes. This section explores the essential steps in preparingdata for AI applications, emphasising dataquality’s active role in achieving successful AI models.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
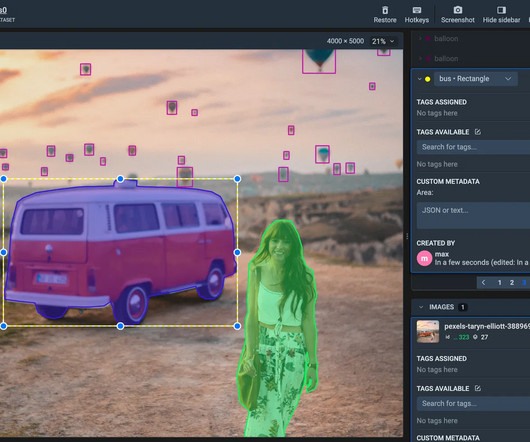
Your decision will impact your dataset’s datapreparation speed, manual effort, consistency, and accuracy. Amazon SageMaker Ground Truth Amazon SageMaker Ground Truth is a cloud-based application for data annotation that allows users to efficiently create quality labeled datasets in bulk.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, datapreparation, and algorithm selection. Dataquality significantly impacts model performance.
Source: Author SuperAnnotate helps annotate data with a wide range of tools like bounding boxes, polygons, and speech tagging. On top of that, it helps to manage teams, assign tasks, and ensure dataquality through collaborative annotation features. Pros: Seamless integration with AWS ecosystem.
Data Transformation Transforming dataprepares it for Machine Learning models. Encoding categorical variables converts non-numeric data into a usable format for ML models, often using techniques like one-hot encoding. Outlier detection identifies extreme values that may skew results and can be removed or adjusted.
We also discuss common security concerns that can undermine trust in AI, as identified by the Open Worldwide Application Security Project (OWASP) Top 10 for LLM Applications , and show ways you can use AWS to increase your security posture and confidence while innovating with generative AI.
3 Quickly build and deploy an end-to-end ML pipeline with Kubeflow Pipelines on AWS. The components comprise implementations of the manual workflow process you engage in for automatable steps, including: Data ingestion (extraction and versioning). Data validation (writing tests to check for dataquality).
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
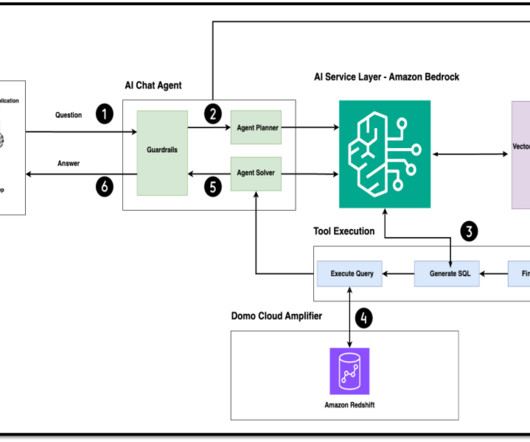
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis. powered by Amazon Bedrock Domo.AI
These activities are recorded in a model recipe , which is a series of steps towards datapreparation. This recipe is maintained throughout the lifecycle of a particular ML model from datapreparation to generating predictions. About the author Shyam Srinivasan is on the AWS low-code/no-code ML product team.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Create a user with administrative access.
This required custom integration efforts, along with complex AWS Identity and Access Management (IAM) policy management, further complicating the model governance process. It helps organizations comply with regulations, manage risks, and maintain operational efficiency through robust model lifecycles and dataquality management.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content