This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
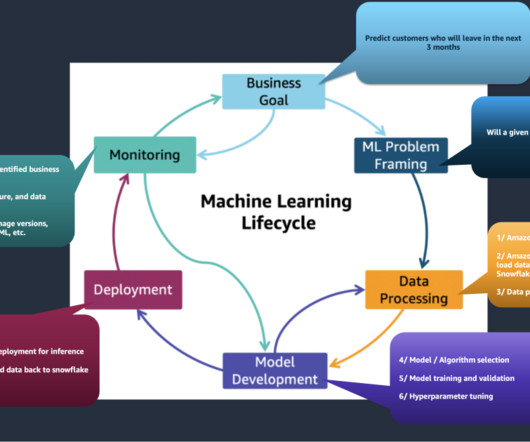
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and datapreparation activities.
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. About the Authors Charles Laughlin is a Principal AI Specialist at Amazon Web Services (AWS).
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Manager DataScience at Marubeni Power International. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. AWS CodeBuild is a fully managed continuous integration service in the cloud.
Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images. The model was then fine-tuned with training data from the datapreparation stage. About the authors Scott Patterson is a Senior Solutions Architect at AWS.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
Build a Large Language Model (From Scratch) by Sebastian Raschka provides a comprehensive guide to constructing LLMs, from datapreparation to fine-tuning. Generative AI on AWS by Chris Fregly and team demystifies generative AI integration into business, emphasizing model selection and deployment on AWS.
Through ML EBA, experienced AWS ML subject matter experts work side by side with your cross-functional team to provide prescriptive guidance, remove blockers, and build organizational capability for a continued ML adoption. Additionally, AWS can offer financial incentives to help offset the costs for your first ML use case.
Snowflake is a cloud data platform that provides data solutions for data warehousing to datascience. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics.
It supports all stages of ML development—from datapreparation to deployment, and allows you to launch a preconfigured JupyterLab IDE for efficient coding within seconds. CodeBuild supports a broad selection of git version control sources like AWS CodeCommit , GitHub, and GitLab.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. Across 180 countries, millions of developers and hundreds of thousands of businesses use Twilio to create magical experiences for their customers.
In this solution, we fine-tune a variety of models on Hugging Face that were pre-trained on medical data and use the BioBERT model, which was pre-trained on the Pubmed dataset and performs the best out of those tried. We implemented the solution using the AWS Cloud Development Kit (AWS CDK).
Boomi funded this solution using the AWS PE ML FastStart program, a customer enablement program meant to take ML-enabled solutions from idea to production in a matter of weeks. The datascience team at Boomi applied the Markov Chain approach to the Step Suggest problem by treating integration steps as states in a state machine.
The built-in project templates provided by Amazon SageMaker include integration with some of third-party tools, such as Jenkins for orchestration and GitHub for source control, and several utilize AWS native CI/CD tools such as AWS CodeCommit , AWS CodePipeline , and AWS CodeBuild. all implemented via CloudFormation.
To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import , a feature that you can use to import customized models created in other environments—such as Amazon SageMaker , Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock.
For more information on Mixtral-8x7B Instruct on AWS, refer to Mixtral-8x7B is now available in Amazon SageMaker JumpStart. Before you get started with the solution, create an AWS account. This identity is called the AWS account root user. For more detailed steps to prepare the data, refer to the GitHub repo.
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. Store your Snowflake account credentials in AWS Secrets Manager. Ingest the data in a table in your Snowflake account.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
Be sure to check out his talk, “ Build Classification and Regression Models with Spark on AWS ,” there! In the unceasingly dynamic arena of datascience, discerning and applying the right instruments can significantly shape the outcomes of your machine learning initiatives. A cordial greeting to all datascience enthusiasts!
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from datapreparation, building and experimentation, training, hosting, and monitoring. Lauren Mullennex is a Senior AI/ML Specialist Solutions Architect at AWS. In his spare time, he loves traveling and writing.
We’re excited to announce Amazon SageMaker Data Wrangler support for Amazon S3 Access Points. Solution Overview Imagine you, as an administrator, have to manage data for multiple datascience teams running their own datapreparation workflows in SageMaker Data Wrangler. Create an S3 access point.
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
Therefore, a common mistake when interviewing applicants is to focus on the minutia of a particular platform (AWS, GCP, Databricks, MLflow, etc.). Every datascience team develops its own approach for each ML library that is used, so the link between the model and the code and parameters is often lost. References [1] J.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). Environments without internet access.
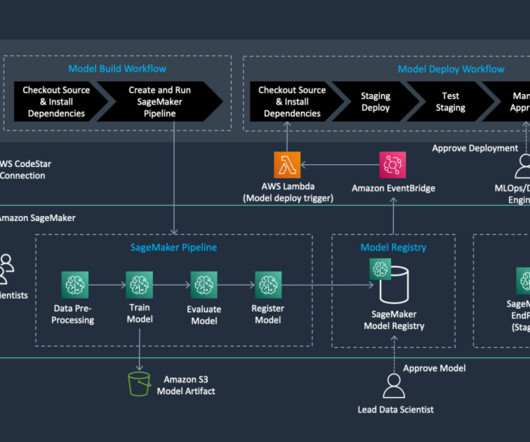
We finish with a case study highlighting the benefits realize by a large AWS and PwC customer who implemented this solution. Solution overview AWS offers a comprehensive portfolio of cloud-native services for developing and running MLOps pipelines in a scalable and sustainable manner. The following diagram illustrates the workflow.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support offering. In Part 1 , we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. You can build custom queries to look up AWS CUR data using standard SQL.
We explain the metrics and show techniques to deal with data to obtain better model performance. Prerequisites If you would like to implement all or some of the tasks described in this post, you need an AWS account with access to SageMaker Canvas. Let’s try to improve the model performance using a data-centric approach.
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. Select Other type of secret. Save the secret and note the ARN of the secret.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
Additional model training benefits can include lower training costs with Managed Spot Training, distributed training libraries to split models and training datasets across AWS GPU instances, and more. input_ids return batch #apply the datapreparation function to all of our fine-tuning dataset samples using dataset's.map method.
Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. Prerequisites Before diving into this use case, complete the following prerequisites: Set up an AWS account. If you are prompted to choose a Kernel, choose the Python 3 (DataScience 3.0) Train, deploy, and test the model.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Here, we’ll discuss the key differences between AIOps and MLOps and how they each help teams and businesses address different IT and datascience challenges. MLOps prioritizes end-to-end management of machine learning models, encompassing datapreparation, model training, hyperparameter tuning and validation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content