This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
RAG helps models access a specific library or database, making it suitable for tasks that require factual accuracy. What is Retrieval-Augmented Generation (RAG) and when to use it Retrieval-Augmented Generation (RAG) is a method that integrates the capabilities of a language model with a specific library or database.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models.
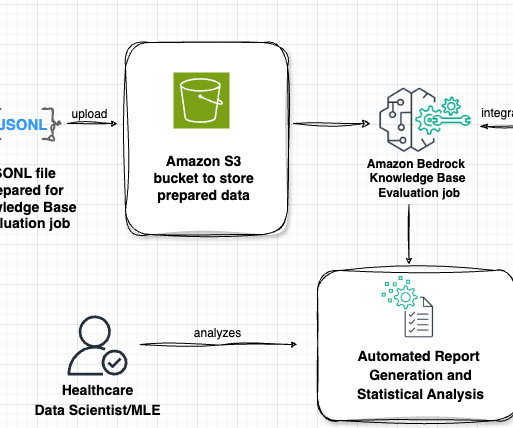
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions.
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. model in Amazon Bedrock.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. AWS CodeBuild is a fully managed continuous integration service in the cloud.
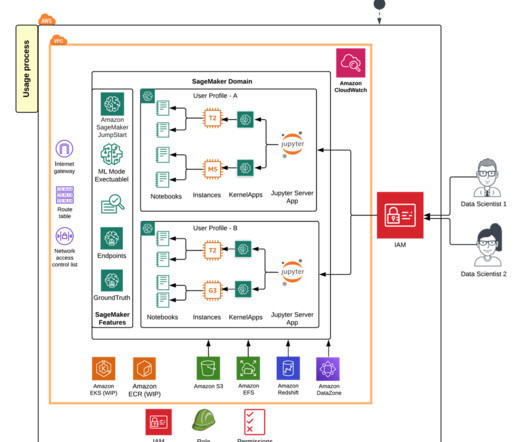
SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
At AWS re:Invent 2023, we announced the general availability of Knowledge Bases for Amazon Bedrock. With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG).
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account. Choose Data Wrangler in the navigation pane.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. The following diagram depicts a high-level RAG architecture. Choose Next.
The post Architecting near real-time personalized recommendations with Amazon Personalize shows how to architect near real-time personalized recommendations using Amazon Personalize and AWS purpose-built data services. For this particular use case, you will be uploading interactions data and items data.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. This allows for data to be aggregated for further manufacturer-agnostic analysis.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics.
To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import , a feature that you can use to import customized models created in other environments—such as Amazon SageMaker , Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
RAG provides additional knowledge to the LLM through its input prompt space and its architecture typically consists of the following components: Indexing : Prepare a corpus of unstructured text, parse and chunk it, and then, embed each chunk and store it in a vector database. client('s3') # Get the region name session = boto3.Session()
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints. To get ready for modeling or reporting, they can visually analyze the database, tables, schema, and author Hive queries to create the ML dataset.
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Below, we show how you can do all these main preprocessing steps from Amazon SageMaker Data Wrangler : Extracting text from a PDF document (powered by Textract) Remove sensitive information (powered by Comprehend) Chunk text into pieces.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. Here, we predict whether an order is a high_value_order or a low_value_order based on the orderpriority as given from the TPC-H data.
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
Welcome to our AWS Redshift to the Snowflake Data Cloud migration blog! In this blog, we’ll walk you through the process of migrating your data from AWS Redshift to the Snowflake Data Cloud. As an experienced data engineering consulting company, phData has helped with numerous migrations to Snowflake.
This allows you to create unique views and filters, and grants management teams access to a streamlined, one-click dashboard without needing to log in to the AWS Management Console and search for the appropriate dashboard. On the AWS CloudFormation console, create a new stack. amazonaws.com docker build -t. docker tag :latest.dkr.ecr.us-east-1.amazonaws.com/
We finish with a case study highlighting the benefits realize by a large AWS and PwC customer who implemented this solution. Solution overview AWS offers a comprehensive portfolio of cloud-native services for developing and running MLOps pipelines in a scalable and sustainable manner. The following diagram illustrates the workflow.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Amazon SageMaker Canvas is a low-code/no-code ML service that enables business analysts to perform datapreparation and transformation, build ML models, and deploy these models into a governed workflow. Prerequisites For this post, you should complete the following prerequisites: Have an AWS account. Set up SageMaker Canvas.
The following is an example of notable proprietary FMs available in AWS (July 2023). The following is an example of notable open-source FM available in AWS (July 2023). Additions are required in historical datapreparation, model evaluation, and monitoring. The following figure illustrates their journey.
Visual modeling: Delivers easy-to-use workflows for data scientists to build datapreparation and predictive machine learning pipelines that include text analytics, visualizations and a variety of modeling methods. foundation models to help users discover, augment, and enrich data with natural language. .”
Solution overview In this solution, we start with datapreparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the Amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors.
Talend Talend is a leading data integration platform known for its extensive tools for transforming, cleansing, and integrating data across multiple sources. It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments.
Advanced tools like AWS QuickSight support large datasets and growing businesses. Microsoft Power BI is a comprehensive business intelligence (BI) tool designed to help organisations turn raw data into meaningful insights. SQL Integration : Easily integrates with most SQL databases via SQL Alchemy. What is Power BI?
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content