This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. model in Amazon Bedrock.
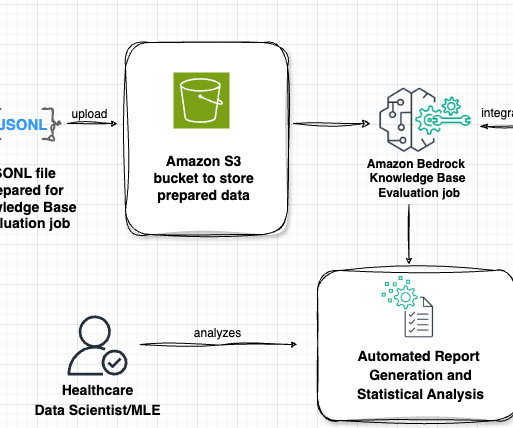
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions. No definite pneumonia.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
Traditionally, developers have had two options when working with SageMaker: the AWS SDK for Python , also known as boto3 , or the SageMaker Python SDK. For this walkthrough, we use a straightforward generative AI lifecycle involving datapreparation, fine-tuning, and a deployment of Meta’s Llama-3-8B LLM. tensorrtllm0.11.0-cu124",
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface. compute.internal.
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
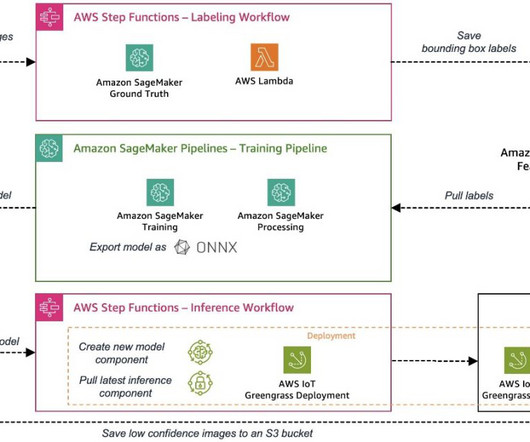
We show you how to use AWS IoT Greengrass to manage model inference at the edge and how to automate the process using AWS Step Functions and other AWS services. AWS IoT Greengrass is an Internet of Things (IoT) open-source edge runtime and cloud service that helps you build, deploy, and manage edge device software.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as data quality, algorithm, scalability, and domain knowledge, to mention a few. We will introduce a custom classifier training pipeline that can be deployed in your AWS account with few clicks.
One of the several challenges faced was adapting the existing on-premises pipeline solution for use on AWS. The solution involved two key components: Modifying and extending existing code – The first part of our solution involved the modification and extension of our existing code to make it compatible with AWS infrastructure.
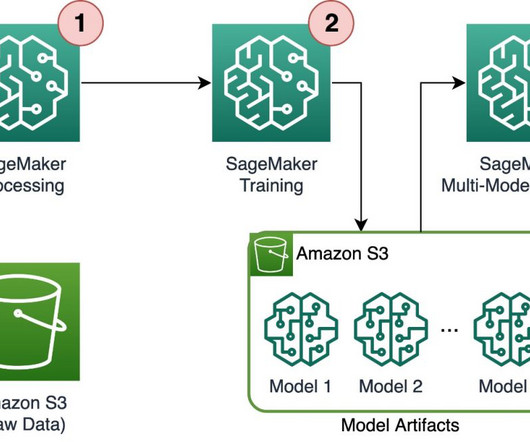
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. The full code can be found on the aws-samples-for-ray GitHub repository. Solution overview This post focuses on the benefits of using Ray and SageMaker together.
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
Prerequisites The following are prerequisites for completing the walkthrough in this post: An AWS account Familiarity with SageMaker concepts, such as an Estimator, training job, and HPO job Familiarity with the Amazon SageMaker Python SDK Python programming knowledge Implement the solution The full code is available in the GitHub repo.
Therefore, a common mistake when interviewing applicants is to focus on the minutia of a particular platform (AWS, GCP, Databricks, MLflow, etc.). A better definition would make use of the directed acyclic graph (DAG) since it may not be a linear process.
With SageMaker, data scientists and developers can quickly build and train ML models, and then deploy them into a production-ready hosted environment. In this post, we demonstrate how to use the managed ML platform to provide a notebook experience environment and perform federated learning across AWS accounts, using SageMaker training jobs.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
SageMaker is a fully managed platform that enables developers and data scientists to build, train, and deploy ML models quickly, while also offering the cost-saving benefits of using the AWS Cloud infrastructure. These checkpoints can be used to resume training at a later moment or as a model to deploy on an endpoint.
Solution overview The AWS predictive maintenance solution for automotive fleets applies deep learning techniques to common areas that drive vehicle failures, unplanned downtime, and repair costs. The connected vehicle sends sensor logs to AWS IoT Core (alternatively, via an HTTP interface). Finally, you launch SageMaker Studio.
Generative AI definitions and differences to MLOps In classic ML, the preceding combination of people, processes, and technology can help you productize your ML use cases. The following is an example of notable proprietary FMs available in AWS (July 2023). Only prompt engineering is necessary for better results.
Amazon SageMaker Clarify can detect potential bias during datapreparation, after model training, and in your deployed model. The definition of these hyperparameters and others available with SageMaker AMT can be found here. About the authors Munish Dabra is a Senior Solutions Architect at Amazon Web Services (AWS).
Launched by Microsoft, Azure ML provides a comprehensive suite of tools and services to support the entire machine learning lifecycle, from datapreparation to model deployment and management. Further Reading and Documentation H2O.ai Documentation H2O.ai
This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes.
We use HyperbandStrategyConfig to configure StrategyConfig , which is later used by the tuning job definition. In his spare time, he enjoys cycling, hiking, and complaining about datapreparation. Based out of Israel, Uri works to empower enterprise customers to design, build, and operate ML workloads at scale.
We don’t claim this is a definitive analysis but rather a rough guide due to several factors: Job descriptions show lagging indicators of in-demand prompt engineering skills, especially when viewed over the course of 9 months. The definition of a particular job role is constantly in flux and varies from employer to employer.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. Cloud Platforms for Machine Learning Cloud platforms like AWS, Google Cloud, and Microsoft Azure provide powerful infrastructures for building and deploying Machine Learning Models.
We also discuss common security concerns that can undermine trust in AI, as identified by the Open Worldwide Application Security Project (OWASP) Top 10 for LLM Applications , and show ways you can use AWS to increase your security posture and confidence while innovating with generative AI.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
Solution overview Scalable Capital’s ML infrastructure consists of two AWS accounts: one as an environment for the development stage and the other one for the production stage. The following diagram shows the workflow for our email classifier project, but can also be generalized to other data science projects. Use Version 2.x
The following figure shows the framework to evaluate LLMs and LLM-based services: Amazon SageMaker Clarify LLM evaluation is an open-source Foundation Model Evaluation (FMEval) library developed by AWS to help customers easily evaluate LLMs. Jagdeep Singh Soni is a Senior Partner Solutions Architect at AWS based in Netherlands.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Environments are the actual data infrastructure behind a project.
We use Amazon SageMaker Pipelines , which helps automate the different steps, including datapreparation, fine-tuning, and creating the model. Prerequisites For this walkthrough, complete the following prerequisite steps: Set up an AWS account. Create a SageMaker Studio environment.
Data preprocessing Text data can come from diverse sources and exist in a wide variety of formats such as PDF, HTML, JSON, and Microsoft Office documents such as Word, Excel, and PowerPoint. Its rare to already have access to text data that can be readily processed and fed into an LLM for training. He received his Ph.D.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content