This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe. You will see a product ARN displayed.
At AWS re:Invent 2023, we announced the general availability of Knowledge Bases for Amazon Bedrock. With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for fully managed Retrieval Augmented Generation (RAG).
This approach is ideal for use cases requiring accuracy and up-to-date information, like providing technical product documentation or customer support. Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes.
Traditionally, developers have had two options when working with SageMaker: the AWS SDK for Python , also known as boto3 , or the SageMaker Python SDK. For this walkthrough, we use a straightforward generative AI lifecycle involving datapreparation, fine-tuning, and a deployment of Meta’s Llama-3-8B LLM. %pip
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. These stages are applicable to both use case and model stages.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
This archive, along with 765,933 varied-quality inspection photographs, some over 15 years old, presented a significant data processing challenge. Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
If you’re implementing complex RAG applications into your daily tasks, you may encounter common challenges with your RAG systems such as inaccurate retrieval, increasing size and complexity of documents, and overflow of context, which can significantly impact the quality and reliability of generated answers.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. Dataset preparation for visual question and answering tasks The Meta Llama 3.2
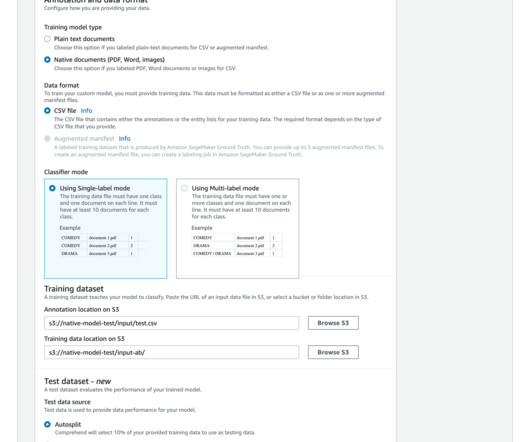
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. politics, sports) that a document belongs to.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
The recently published IDC MarketScape: Asia/Pacific (Excluding Japan) AI Life-Cycle Software Tools and Platforms 2022 Vendor Assessment positions AWS in the Leaders category. AWS met the criteria and was evaluated by IDC along with eight other vendors. AWS is positioned in the Leaders category based on current capabilities.
AWS published Guidance for Optimizing MLOps for Sustainability on AWS to help customers maximize utilization and minimize waste in their ML workloads. The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. This leads to substantial resource consumption.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. Each embedding aims to capture the semantic or contextual meaning of the data.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics.
We go through several steps, including datapreparation, model creation, model performance metric analysis, and optimizing inference based on our analysis. We use an Amazon SageMaker notebook and the AWS Management Console to complete some of these steps. We will be using the Data-Preparation notebook.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
Enterprise search is a critical component of organizational efficiency through document digitization and knowledge management. Enterprise search covers storing documents such as digital files, indexing the documents for search, and providing relevant results based on user queries. Initialize DocumentStore and index documents.
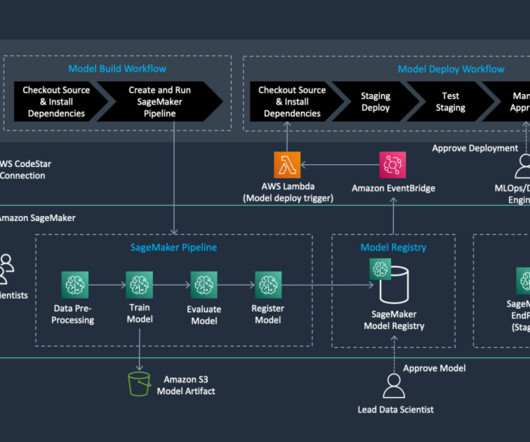
The built-in project templates provided by Amazon SageMaker include integration with some of third-party tools, such as Jenkins for orchestration and GitHub for source control, and several utilize AWS native CI/CD tools such as AWS CodeCommit , AWS CodePipeline , and AWS CodeBuild.
Amazon Comprehend is a managed AI service that uses natural language processing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art natural language processing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. The recommendation system has driven an 8.6%
It does so by covering the ML workflow end-to-end: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, and ready-to-use models powered by AWS AI services and Generative AI, SageMaker Canvas can help you to achieve your goals.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. Across 180 countries, millions of developers and hundreds of thousands of businesses use Twilio to create magical experiences for their customers.
The explosion of data creation and utilization, paired with the increasing need for rapid decision-making, has intensified competition and unlocked opportunities within the industry. AWS has been at the forefront of domain adaptation, creating a framework to allow creating powerful, specialized AI models.
Finally, they can also train and deploy models with SageMaker Autopilot , schedule jobs, or operationalize datapreparation in a SageMaker Pipeline from Data Wrangler’s visual interface. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
The next step is to provide them with a more intuitive and conversational interface to interact with their data, empowering them to generate meaningful visualizations and reports through natural language interactions. Solution overview The following diagram illustrates the solution architecture and data flow.
This simplifies access to generative artificial intelligence (AI) capabilities to business analysts and data scientists without the need for technical knowledge or having to write code, thereby accelerating productivity. Provide the AWS Region, account, and model IDs appropriate for your environment.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
Due to various government regulations and rules, customers have to find a mechanism to handle this sensitive data with appropriate security measures to avoid regulatory fines, possible fraud, and defamation. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines. A SageMaker Studio domain and user.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. With Amazon Kendra, you can find relevant answers to your questions quickly, without sifting through documents.
In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload. Datapreparation LLM developers train their models on large datasets of naturally occurring text.
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from datapreparation, building and experimentation, training, hosting, and monitoring. The documentation lists the steps to migrate from SageMaker Studio Classic. In his spare time, he loves traveling and writing.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























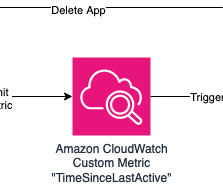

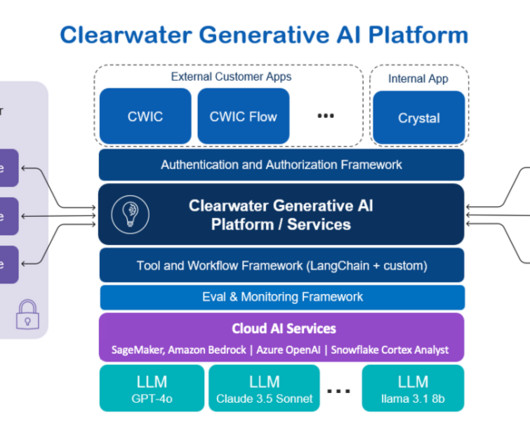

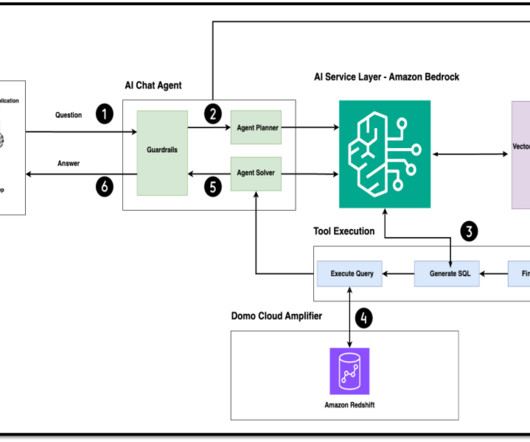
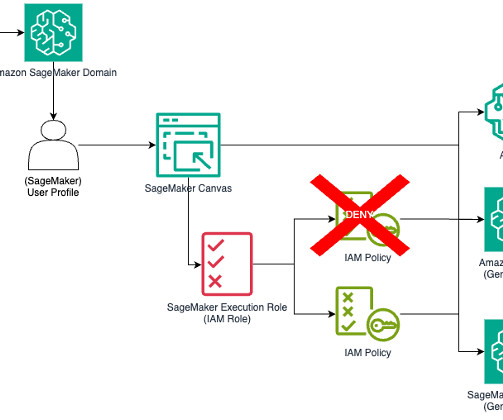












Let's personalize your content