This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
Welcome to our AWS Redshift to the Snowflake Data Cloud migration blog! In this blog, we’ll walk you through the process of migrating your data from AWS Redshift to the Snowflake Data Cloud. One popular route is leveraging third-party ETL tools like Fivetran to ensure a smooth and successful migration.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
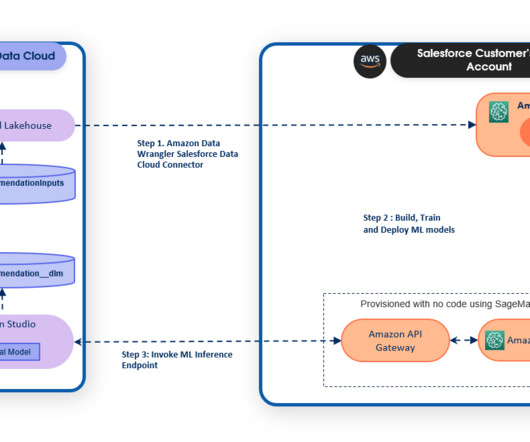
Benefits of the SageMaker and Data Cloud Einstein Studio integration Here’s how using SageMaker with Einstein Studio in Salesforce Data Cloud can help businesses: It provides the ability to connect custom and generative AI models to Einstein Studio for various use cases, such as lead conversion, case classification, and sentiment analysis.
The solution required collecting and preparing user behavior data, training an ML model using Amazon Personalize, generating personalized recommendations through the trained model, and driving marketing campaigns with the personalized recommendations. The user interactions data from various sources is persisted in their data warehouse.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. aws s3 cp s3://sagemaker-sample-files/datasets/text/SST2/sst2.train train sst2.train
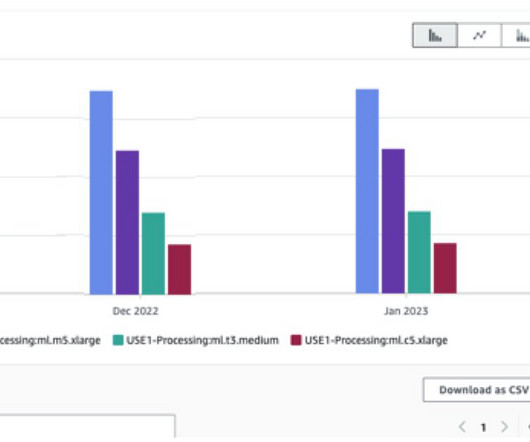
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. However, preparing raw data for ML training and evaluation is often a tedious and demanding task in terms of compute resources, time, and human effort. You can filter processing costs by applying a filter on the usage type.
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries.
Visual modeling: Delivers easy-to-use workflows for data scientists to build datapreparation and predictive machine learning pipelines that include text analytics, visualizations and a variety of modeling methods.
With the importance of data in various applications, there’s a need for effective solutions to organize, manage, and transfer data between systems with minimal complexity. While numerous ETL tools are available on the market, selecting the right one can be challenging.
It enables reporting and Data Analysis and provides a historical data record that can be used for decision-making. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity.
Placing functions for plotting, data loading, datapreparation, and implementations of evaluation metrics in plain Python modules keeps a Jupyter notebook focused on the exploratory analysis | Source: Author Using SQL directly in Jupyter cells There are some cases in which data is not in memory (e.g.,
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. SageMaker Unified Studio provides a unified experience for using data, analytics, and AI capabilities. Create a user with administrative access.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content