This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. model in Amazon Bedrock.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
NLP with Transformers introduces readers to transformer architecture for naturallanguageprocessing, offering practical guidance on using Hugging Face for tasks like text classification.
Genomic language models are a new and exciting field in the application of large language models to challenges in genomics. In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
Processing unstructured data has become easier with the advancements in naturallanguageprocessing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend. We use an Amazon SageMaker notebook and the AWS Management Console to complete some of these steps.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
In this solution, we fine-tune a variety of models on Hugging Face that were pre-trained on medical data and use the BioBERT model, which was pre-trained on the Pubmed dataset and performs the best out of those tried. We implemented the solution using the AWS Cloud Development Kit (AWS CDK).
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful dataprocessing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
The built-in project templates provided by Amazon SageMaker include integration with some of third-party tools, such as Jenkins for orchestration and GitHub for source control, and several utilize AWS native CI/CD tools such as AWS CodeCommit , AWS CodePipeline , and AWS CodeBuild. all implemented via CloudFormation.
For more information on Mixtral-8x7B Instruct on AWS, refer to Mixtral-8x7B is now available in Amazon SageMaker JumpStart. Before you get started with the solution, create an AWS account. This identity is called the AWS account root user. For more detailed steps to prepare the data, refer to the GitHub repo.
It can be difficult to find insights from this data, particularly if efforts are needed to classify, tag, or label it. Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. politics, sports) that a document belongs to.
Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. In this section, we cover how to discover these models in SageMaker Studio.
One of the several challenges faced was adapting the existing on-premises pipeline solution for use on AWS. The solution involved two key components: Modifying and extending existing code – The first part of our solution involved the modification and extension of our existing code to make it compatible with AWS infrastructure.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art naturallanguageprocessing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. The recommendation system has driven an 8.6%
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. Prerequisites For this walkthrough, you should have the following prerequisites: An AWS account set up.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Large language models (LLMs) have achieved remarkable success in various naturallanguageprocessing (NLP) tasks, but they may not always generalize well to specific domains or tasks. This is where MLflow can help streamline the ML lifecycle, from datapreparation to model deployment.
Boomi funded this solution using the AWS PE ML FastStart program, a customer enablement program meant to take ML-enabled solutions from idea to production in a matter of weeks. Alternatives to SageMaker Boomi was already an AWS customer before the AWS PE ML FastStart program.
Solution overview This solution uses Amazon Comprehend and SageMaker Data Wrangler to automatically redact PII data from a sample dataset. Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required.
As AI adoption continues to accelerate, developing efficient mechanisms for digesting and learning from unstructured data becomes even more critical in the future. This could involve better preprocessing tools, semi-supervised learning techniques, and advances in naturallanguageprocessing. Choose your domain.
In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload. Datapreparation LLM developers train their models on large datasets of naturally occurring text.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using naturallanguageprocessing (NLP) and advanced search algorithms. With Amazon Kendra, you can find relevant answers to your questions quickly, without sifting through documents.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. You now run the datapreparation step in the notebook.
Amazon Comprehend is a managed AI service that uses naturallanguageprocessing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
Amazon OpenSearch OpenSearch Service is a fully managed service that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. as our example data to perform retrieval augmented question answering on. Here, we walk through the steps for indexing to an OpenSearch service deployed on AWS.
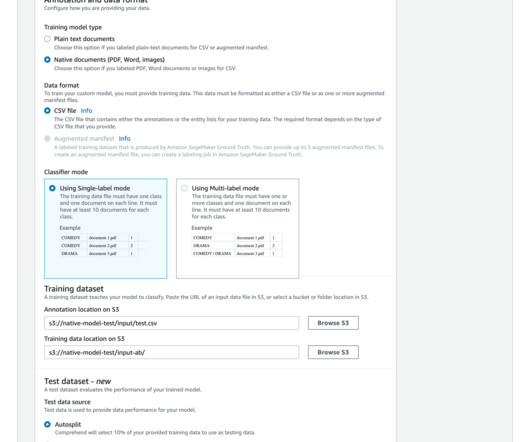
At AWS re:Invent 2022, Amazon Comprehend , a naturallanguageprocessing (NLP) service that uses machine learning (ML) to discover insights from text, launched support for native document types. This data is useful to evaluate model performance, iterate, and improve the accuracy of your model.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
These personas need dedicated environments to perform the different processes, as illustrated in the following figure. They have deep end-to-end ML and naturallanguageprocessing (NLP) expertise and data science skills, and massive data labeler and editor teams.
As a result, diffusion models have become a popular tool in many fields of artificial intelligence, including computer vision, naturallanguageprocessing, and audio synthesis. Diffusion models have numerous applications in computer vision, naturallanguageprocessing, and audio synthesis.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data. The process includes activities such as anomaly detection, event correlation, predictive analytics, automated root cause analysis and naturallanguageprocessing (NLP).
Neural networks are inspired by the structure of the human brain, and they are able to learn complex patterns in data. Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition.
Libraries and Extensions: Includes torchvision for image processing, touchaudio for audio processing, and torchtext for NLP. Notable Use Cases PyTorch is extensively used in naturallanguageprocessing (NLP), including applications like sentiment analysis, machine translation, and text generation.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as datapreparation, model training, tuning and validation. About the Authors Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. In his free time, he enjoys playing chess and traveling.
The process typically involves several key steps: Model Selection: Users choose from a library of pre-trained models tailored for specific applications such as NaturalLanguageProcessing (NLP), image recognition, or predictive analytics. Predictive Analytics : Models that forecast future events based on historical data.
Table of Contents Introduction to PyCaret Benefits of PyCaret Installation and Setup DataPreparation Model Training and Selection Hyperparameter Tuning Model Evaluation and Analysis Model Deployment and MLOps Working with Time Series Data Conclusion 1. or higher and a stable internet connection for the installation process.
Major cloud infrastructure providers such as IBM, Amazon AWS, Microsoft Azure and Google Cloud have expanded the market by adding AI platforms to their offerings. Some AI platforms also provide advanced AI capabilities, such as naturallanguageprocessing (NLP) and speech recognition.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content