This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import , a feature that you can use to import customized models created in other environments—such as Amazon SageMaker , Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock.
SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI. Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment.
Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images. The model was then fine-tuned with training data from the datapreparation stage. About the authors Scott Patterson is a Senior Solutions Architect at AWS.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface. Choose Create stack.
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. Store your Snowflake account credentials in AWS Secrets Manager. Ingest the data in a table in your Snowflake account.
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. All pipeline parameters used in this solution exist in a single config.yml file.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using the Amazon Web Services (AWS) tools without having to manage infrastructure. The following screenshot shows what the upload looks like when it’s complete.
Finally, they can also train and deploy models with SageMaker Autopilot , schedule jobs, or operationalize datapreparation in a SageMaker Pipeline from Data Wrangler’s visual interface. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
Additionally, using Amazon Comprehend with AWS PrivateLink means that customer data never leaves the AWS network and is continuously secured with the same data access and privacy controls as the rest of your applications. For more details, refer to Integrating SageMaker Data Wrangler with SageMaker Pipelines.
Welcome to our AWS Redshift to the Snowflake Data Cloud migration blog! In this blog, we’ll walk you through the process of migrating your data from AWS Redshift to the Snowflake Data Cloud. As an experienced data engineering consulting company, phData has helped with numerous migrations to Snowflake.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support offering. In Part 1 , we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. You can build custom queries to look up AWS CUR data using standard SQL.
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Create a dataflow Complete the following steps to create a data flow in SageMaker Canvas: On the SageMaker Canvas home page, choose Datapreparation. This will land on a data flow page. Choose your domain.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Be sure to check out his talk, “ Build Classification and Regression Models with Spark on AWS ,” there! In the unceasingly dynamic arena of data science, discerning and applying the right instruments can significantly shape the outcomes of your machine learning initiatives. A cordial greeting to all data science enthusiasts!
This allows you to create unique views and filters, and grants management teams access to a streamlined, one-click dashboard without needing to log in to the AWS Management Console and search for the appropriate dashboard. On the AWS CloudFormation console, create a new stack. amazonaws.com docker build -t. docker tag :latest.dkr.ecr.us-east-1.amazonaws.com/
The following steps give an overview of how to use the new capabilities launched in SageMaker for Salesforce to enable the overall integration: Set up the Amazon SageMaker Studio domain and OAuth between Salesforce and the AWS account s. Select Other type of secret. Save the secret and note the ARN of the secret.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Advanced tools like AWS QuickSight support large datasets and growing businesses. Microsoft Power BI is a comprehensive business intelligence (BI) tool designed to help organisations turn raw data into meaningful insights. It supports various Visualisations and can connect to various SQL-based data sources.
Visual modeling: Delivers easy-to-use workflows for data scientists to build datapreparation and predictive machine learning pipelines that include text analytics, visualizations and a variety of modeling methods. Presto engine: Incorporates the latest performance enhancements to the Presto query engine.
Data Wrangler simplifies the process of datapreparation and feature engineering like data selection, cleansing, exploration, and visualization from a single visual interface. Data Wrangler has more than 300 preconfigured data transformations that can effectively be used in transforming the data.
Example template for an exploratory notebook | Source: Author How to organize code in Jupyter notebook For exploratory tasks, the code to produce SQL queries, pandas data wrangling, or create plots is not important for readers. in a pandas DataFrame) but in the company’s data warehouse (e.g., documentation. Redshift).
If you answer “yes” to any of these questions, you will need cloud storage, such as Amazon AWS’s S3, Azure Data Lake Storage or GCP’s Google Storage. Copy Into When loading data into Snowflake, the very first and most important rule to follow is: do not load data with SQL inserts!
By implementing efficient data pipelines , organisations can enhance their data processing capabilities, reduce time spent on datapreparation, and improve overall data accessibility. Data Storage Solutions Data storage solutions are critical in determining how data is organised, accessed, and managed.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Tools like Apache NiFi, Talend, and Informatica provide user-friendly interfaces for designing workflows, integrating diverse data sources, and executing ETL processes efficiently. Choosing the right tool based on the organisation’s specific needs, such as data volume and complexity, is vital for optimising ETL efficiency.
Databricks: Powered by Apache Spark, Databricks is a unified data processing and analytics platform, facilitates datapreparation, can be used for integration with LLMs, and performance optimization for complex prompt engineering tasks. Kubernetes: A long-established tool for containerized apps.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
We also discuss common security concerns that can undermine trust in AI, as identified by the Open Worldwide Application Security Project (OWASP) Top 10 for LLM Applications , and show ways you can use AWS to increase your security posture and confidence while innovating with generative AI.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
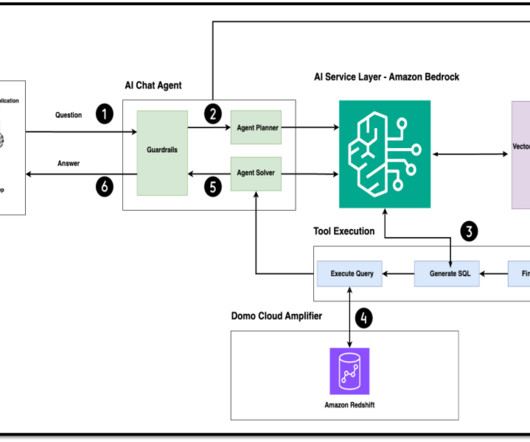
The next step is to provide them with a more intuitive and conversational interface to interact with their data, empowering them to generate meaningful visualizations and reports through natural language interactions. Solution overview The following diagram illustrates the solution architecture and data flow.
With this launch, Canvas empowers you to capitalize on data stored in disparate sources by supporting in-app data import and aggregation from over 40 data sources. This feature is made possible through new native connectors to Athena and to Amazon AppFlow via the AWS Glue Data Catalog.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Create a user with administrative access.
Augmented Analytics Augmented analytics is revolutionising the way businesses analyse data by integrating Artificial Intelligence (AI) and Machine Learning (ML) into analytics processes. Understand data structures and explore data warehousing concepts to efficiently manage and retrieve large datasets.
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content