This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
AI Powered Speech Analytics for Amazon Connect This video walks thru the AWS products necessary for converting video to text, translating and performing basic NLP. Amazon Builders’ Library is now available in 16 Languages The Builder’s Library is a huge collection of resources about how Amazon builds and manages software.
In the contemporary age of Big Data, Data Warehouse Systems and DataScience Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures? appeared first on DataScience Blog.
Spark is well suited to applications that involve large volumes of data, real-time computing, model optimization, and deployment. Read about Apache Zeppelin: Magnum Opus of MLOps in detail AWS SageMaker AWS SageMaker is an AI service that allows developers to build, train and manage AI models.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS).
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. We also use these in the final embedding drift analysis component of the application.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 DataScience tools for 2024.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a data engineer. Identify your existing datascience strengths. Stay on top of data engineering trends.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Technologies: Hadoop, Spark, etc. Read more to know.
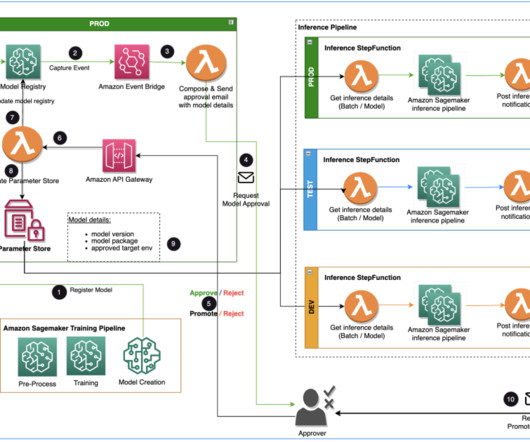
In this post, we discuss how the AWS AI/ML team collaborated with the Merck Human Health IT MLOps team to build a solution that uses an automated workflow for ML model approval and promotion with human intervention in the middle. A model developer typically starts to work in an individual ML development environment within Amazon SageMaker.
Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloud computing resources. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
But it’s interoperable on any cloud like Azure, AWS or GCP. was originally published in IBM DataScience in Practice on Medium, where people are continuing the conversation by highlighting and responding to this story. It focus on the monitoring and retraining policies that are keen for continious training.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Ensure that data is clean, consistent, and up-to-date. Use ETL (Extract, Transform, Load) processes or data integration tools to streamline data ingestion.
As the sibling of datascience, data analytics is still a hot field that garners significant interest. Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently. Cloud Services: Google Cloud Platform, AWS, Azure.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. aws s3 cp s3://sagemaker-sample-files/datasets/text/SST2/sst2.train train sst2.train
Over the past few years DataScience has MIGRATED from individual computers to service cloud platforms. I just finished learning Azure’s service cloud platform using Coursera and the Microsoft Learning Path for DataScience.
billion 50,067 million 50.067 billion What were Amazon’s AWS sales for the second quarter of 2023? Amazon’s AWS sales for the second quarter of 2023 were $22.1 foreign exchange rates 0 0 0 What were Amazon’s AWS sales for the second quarter of 2023? Amazon’s AWS sales for the second quarter of 2023 were $22.1
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
May be useful Best Workflow and Pipeline Orchestration Tools: Machine Learning Guide Phase 1—Data pipeline: getting the house in order Once the dust was settled, we got the Architecture Canvas completed, and the plan was clear to everyone involved, the next step was to take a closer look at the architecture. What’s in the box?
Connecting Snowflake to Python can be a game changer for your data services. Python can be used to migrate your data from a previous platform to Snowflake , create or manage data pipelines for Extract, Transform, and Load (ETL) processes, perform datascience tasks such as machine learning or create data analysis visualizations.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
Image generated with Midjourney In today’s fast-paced world of datascience, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
Jupyter notebooks have been one of the most controversial tools in the datascience community. Nevertheless, many data scientists will agree that they can be really valuable – if used well. I’ll show you best practices for using Jupyter Notebooks for exploratory data analysis.
While Git can store code locally and also on a hosting service like GitHub, GitLab, and Bitbucket, DVC uses a remote repository to store all data and models. It supports most major cloud providers, such as AWS, GCP, and Azure. Data versioning with DVC is very simple and straightforward. size: Size of the file, in kilobytes.
At a high level, we are trying to make machine learning initiatives more human capital efficient by enabling teams to more easily get to production and maintain their model pipelines, ETLs, or workflows. For example, let’s take Airflow , AWS SageMaker pipelines. If you can be data-driven, that is the best.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content