This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
It allows datascientists to build models that can automate specific tasks. SageMaker boosts machine learning model development with the power of AWS, including scalable computing, storage, networking, and pricing. AWS SageMaker also has a CLI for model creation and management.
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. This brings reliability to dataETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. Choose Create VPC.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
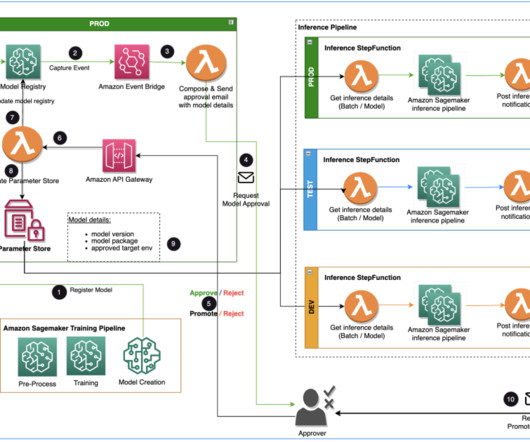
In this post, we discuss how the AWS AI/ML team collaborated with the Merck Human Health IT MLOps team to build a solution that uses an automated workflow for ML model approval and promotion with human intervention in the middle. A model developer typically starts to work in an individual ML development environment within Amazon SageMaker.
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
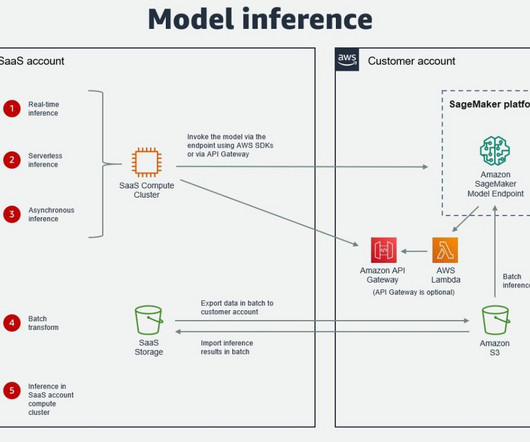
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and datascientists. We also deep dive into the most common architectures and AWS resources to facilitate these integrations. In some cases, an ISV may deploy their software in the customer AWS account.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
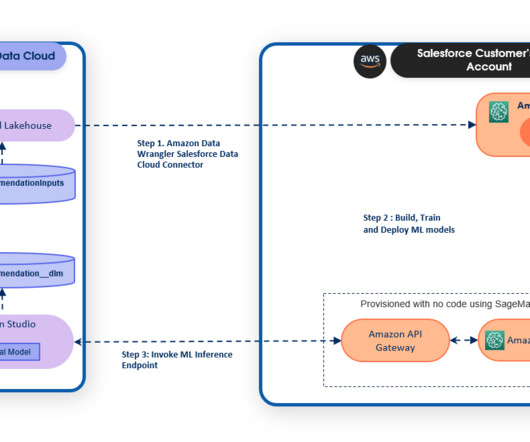
Introducing Einstein Studio on Data Cloud Data Cloud is a data platform that provides businesses with real-time updates of their customer data from any touch point. With Einstein Studio, a gateway to AI tools on the data platform, admins and datascientists can effortlessly create models with a few clicks or using code.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Ensure that data is clean, consistent, and up-to-date. Use ETL (Extract, Transform, Load) processes or data integration tools to streamline data ingestion.
The following diagram illustrates the architecture of a news recommender application powered by Amazon Personalize and supporting AWS services. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. Happy building!
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio. train sst2.train train sst2.train
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. AWS provides several tools to create and manage ML model deployments. An example would be AWS recognition. I would say the same happened in our case. S3 buckets.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
The solution required collecting and preparing user behavior data, training an ML model using Amazon Personalize, generating personalized recommendations through the trained model, and driving marketing campaigns with the personalized recommendations. The user interactions data from various sources is persisted in their data warehouse.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Photo by Jeroen den Otter on Unsplash Who should read this article: Machine and Deep Learning Engineers, Solution Architects, DataScientist, AI Enthusiast, AI Founders What is covered in this article? But it’s interoperable on any cloud like Azure, AWS or GCP. Continuous training is the solution.
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
By following these guidelines, datascientists can quantify the user experience delivered by their generative AI pipelines and communicate meaning to business stakeholders, facilitating ready comparisons across different architectures, such as Retrieval Augmented Generation (RAG) pipelines, off-the-shelf or fine-tuned LLMs, or agentic solutions.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. The Open Connector Framework SDK enables engineers to custom-build data source connectors , which are indexed by Alation. Open Data Quality Initiative.
If you want to get datascientists, engineers, architects, stakeholders, third-party consultants, and a whole myriad of other actors on board, you have to build two things: 1 Bridges between stakeholders and members from all over an organization—from marketing to sales to engineering—working with data on different theoretical and practical levels.
Raw DataData warehouses emerged several decades ago as a means of combining, harmonizing, and preprocessing data in preparation for advanced analytics. A data warehouse implies a certain degree of preprocessing, or at the very least, an organized and well-defined data model.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information.
At Precisely’s Trust ’23 conference, Chief Operating Officer Eric Yau hosted an expert panel discussion on modern data architectures. The group kicked off the session by exchanging ideas about what it means to have a modern data architecture.
Brainly’s journey toward MLOps Since the early days of ML at Brainly, infrastructure, and engineering teams have encouraged datascientists and machine learning engineers working on projects to use best practices for structuring their projects and code bases. We also do not want to research our internal model architectures.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and datascientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors.
Stefan is a software engineer, datascientist, and has been doing work as an ML engineer. He also ran the data platform in his previous company and is also co-creator of open-source framework, Hamilton. For example, let’s take Airflow , AWS SageMaker pipelines. I also recently found out, you are the CEO of DAGWorks.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by DataScientists. How to Become an Azure Data Engineer? For Azure Data Engineer, there are various skills required.
Jupyter notebooks have been one of the most controversial tools in the data science community. Nevertheless, many datascientists will agree that they can be really valuable – if used well. Data on its own is not sufficient for a cohesive story. There are some outspoken critics , as well as passionate fans.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Datascientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
It often requires multiple teams working together and integrating various data sources, tools, and services. For example, creating a targeted marketing app involves data engineers, datascientists, and business analysts using different systems and tools. Install or update the latest version of the AWS CLI.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content