This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Image 1- [link] Whether you are an experienced or an aspiring datascientist, you must have worked on machinelearning model development comprising of data cleaning, wrangling, comparing different ML models, training the models on Python Notebooks like Jupyter. All the […].
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
Machinelearning (ML) has emerged as a powerful tool to help nonprofits expedite manual processes, quickly unlock insights from data, and accelerate mission outcomesfrom personalizing marketing materials for donors to predicting member churn and donation patterns. This reduces operational overhead for your organization.
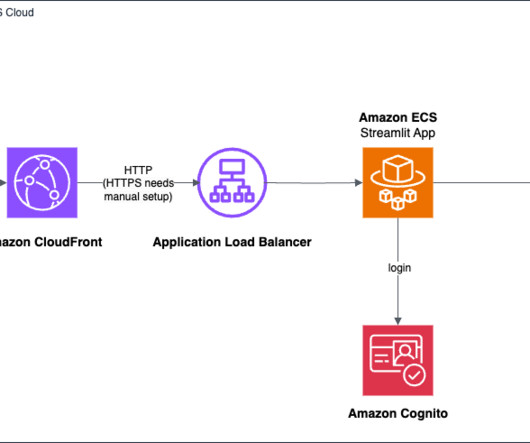
However, as exciting as these advancements are, datascientists often face challenges when it comes to developing UIs and to prototyping and interacting with their business users. Streamlit allows datascientists to create interactive web applications using Python, using their existing skills and knowledge.
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Choose Create stack.
AWS SageMaker is transforming the way organizations approach machinelearning by providing a comprehensive, cloud-based platform that standardizes the entire workflow, from data preparation to model deployment. What is AWS SageMaker?
From social media to e-commerce, businesses generate large amounts of data that can be leveraged to gain insights and make informed decisions. Data science involves the use of statistical and machinelearning techniques to analyze and make […] The post DataScientist at HP Inc.’s
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machinelearning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
This article was published as a part of the Data Science Blogathon. Introduction on AWS Sagemaker Datascientists need to create, train and deploy a large number of models as they work. AWS has created a simple […].
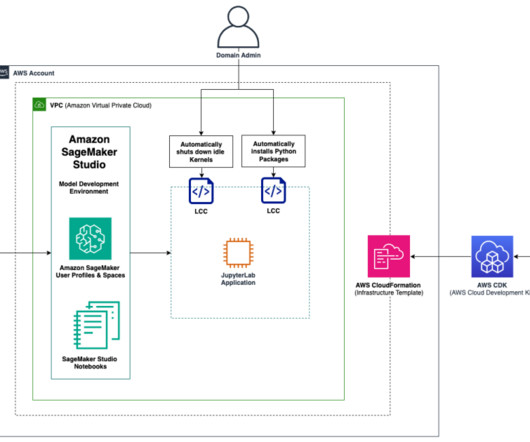
Amazon SageMaker Studio is the first integrated development environment (IDE) purposefully designed to accelerate end-to-end machinelearning (ML) development. You can create multiple Amazon SageMaker domains , which define environments with dedicated data storage, security policies, and networking configurations.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Amazon SageMaker is a cloud-based machinelearning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. By using a combination of AWS services, you can implement this feature effectively, overcoming the current limitations within SageMaker.
The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). It uses deep learning to convert audio to text quickly and accurately. AWS Lambda is used in this architecture as a transcription processor to store the processed transcriptions into an Amazon OpenSearch Service table.
DataScientist Career Path: from Novice to First Job; Understand Neural Networks from a Bayesian Perspective; The Best Ways for Data Professionals to Market AWS Skills; Build Your Own Automated MachineLearning App.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
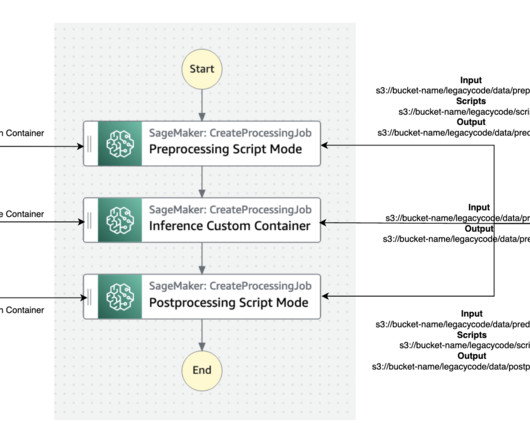
Tens of thousands of AWS customers use AWSmachinelearning (ML) services to accelerate their ML development with fully managed infrastructure and tools. We demonstrate how two different personas, a datascientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
This post is co-authored by Manuel Lopez Roldan, SiMa.ai, and Jason Westra, AWS Senior Solutions Architect. Are you looking to deploy machinelearning (ML) models at the edge? Designed to work on SiMas MLSoC (MachineLearning System on Chip) hardware, your models will have seamless compatibility across the entire SiMa.ai
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, datascientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
Amazon SageMaker supports geospatial machinelearning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. See Amazon SageMaker geospatial capabilities to learn more. About the Author Xiong Zhou is a Senior Applied Scientist at AWS.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
Machinelearning deployment is a crucial step in bringing the benefits of data science to real-world applications. With the increasing demand for machinelearning deployment, various tools and platforms have emerged to help datascientists and developers deploy their models quickly and efficiently.
(Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. This customer wanted to use machinelearning as a tool to digitize images and recognize handwriting.
Artificial intelligence (AI) and machinelearning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. Machinelearning operations (MLOps) applies DevOps principles to ML systems.
Streamlit is an open source framework for datascientists to efficiently create interactive web-based data applications in pure Python. Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. Install Python 3.7
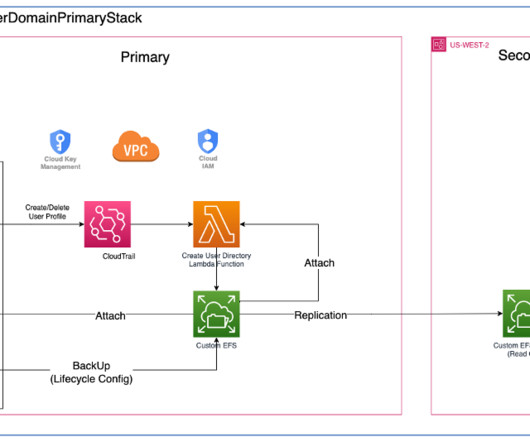
As industries begin adopting processes dependent on machinelearning (ML) technologies, it is critical to establish machinelearning operations (MLOps) that scale to support growth and utilization of this technology. AWS CloudTrail – Monitors and records account activity across AWS infrastructure.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. Generate accurate training data for SageMaker models – For model training, datascientists can use Tecton’s SDK within their SageMaker notebooks to retrieve historical features.
These tools will help you streamline your machinelearning workflow, reduce operational overheads, and improve team collaboration and communication. Machinelearning (ML) is the technology that automates tasks and provides insights. It allows datascientists to build models that can automate specific tasks.
Over the last 18 months, AWS has announced more than twice as many machinelearning (ML) and generative artificial intelligence (AI) features into general availability than the other major cloud providers combined. The following figure highlights where AWS lands in the DSML Magic Quadrant.
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. To view this series from the beginning, start with Part 1.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machinelearning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machinelearning (ML), data sharing and monetization, and more.
Real-world applications vary in inference requirements for their artificial intelligence and machinelearning (AI/ML) solutions to optimize performance and reduce costs. aws s3 rm s3://{bucket}/{prefix_name}/model-monitor/data-capture/{predictor.endpoint_name} --recursive ! DataScientist with AWS Professional Services.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. You can track these job status details in both the AWS Management Console and AWS SDK. Prior to joining AWS, he obtained his Ph.D.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house.
The higher-level abstracted layer is designed for datascientists with limited AWS expertise, offering a simplified interface that hides complex infrastructure details. Datascientists can also seamlessly transition from local training to remote training and training on multiple nodes using the ModelTrainer.
This post demonstrates how to seamlessly automate the deployment of an end-to-end RAG solution using Knowledge Bases for Amazon Bedrock and AWS CloudFormation , enabling organizations to quickly and effortlessly set up a powerful RAG system. On the AWS CloudFormation console, create a new stack. txt,md,html,doc/docx,csv,xls/.xlsx,pdf).
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts.
Increasingly, FMs are completing tasks that were previously solved by supervised learning, which is a subset of machinelearning (ML) that involves training algorithms using a labeled dataset. With a serverless solution, AWS provides a managed solution, facilitating lower cost of ownership and reduced complexity of maintenance.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machinelearning (ML) models.
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. She leads machinelearning projects in various domains such as computer vision, natural language processing, and generative AI. model in Amazon Bedrock.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content