This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The post AWS Redshift: Cloud DataWarehouse Service appeared first on Analytics Vidhya. The datasets range in size from a few 100 megabytes to a petabyte. […].
Introduction Source – pexels.com Are you struggling to manage and analyze large amounts of data? Are you looking for a cost-effective and scalable solution for your datawarehouse needs? Look no further than AWS Redshift. AWS Redshift is a fully managed, petabyte-scale datawarehouse […].
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. Traditionally, ETL processes are […].
Introduction Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a datawarehouse in the cloud.
Businesses have adopted Snowflake as migration from on-premise enterprise datawarehouses (such as Teradata) or a more flexibly scalable and easier-to-manage alternative to […]. The post Data Warehousing with Snowflake and Other Alternatives appeared first on Analytics Vidhya.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Introduction Amazon Elastic MapReduce (EMR) is a fully managed service that makes it easy to process large amounts of data using the popular open-source framework Apache Hadoop. EMR enables you to run petabyte-scale datawarehouses and analytics workloads using the Apache Spark, Presto, and Hadoop ecosystems.
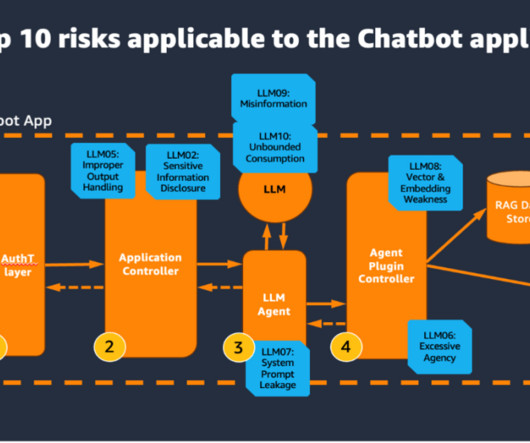
Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.
At PeerDB, we are building a fast and a cost-effective way to replicate data from Postgres to DataWarehouses such as Snowflake, BigQuery, ClickHouse, Postgres and so on. All our customers run Postgres at the heart of the data stack, running fully ma.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. Precise Software Solutions, Inc. The platform helped the agency digitize and process forms, pictures, and other documents.
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a Machine Learning Model in BigQuery appeared first on Analytics Vidhya.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
We are in the midst of an AI revolution where organizations are seeking to leverage data for business transformation and harness generative AI and foundation models to boost productivity, innovate, enhance customer experiences, and gain a competitive edge. Watsonx.data on AWS: Imagine having the power of data at your fingertips.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
Businesses globally recognize the power of generative AI and are eager to harness data and AI for unmatched growth, sustainable operations, streamlining and pioneering innovation. In this quest, IBM and AWS have forged a strategic alliance, aiming to transition AI’s business potential from mere talk to tangible action.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
improved document management capabilities, web portals, mobile applications, datawarehouses, enhanced location services, etc.) Why IBM Consulting and AWS? AWS has the biggest cloud infrastructure services vendor market share worldwide, averaging around 33% as of Q4 2022.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose Create VPC.
This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. Choose Grant.
This post was co-authored by Brian Curry (Founder and Head of Products at OCX Cognition) and Sandhya MN (Data Science Lead at InfoGain) OCX Cognition is a San Francisco Bay Area-based startup, offering a commercial B2B software as a service (SaaS) product called Spectrum AI. This reduced the need to develop new low-level ML code.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. It provides a single web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift datawarehouses. An SSL certificate created and imported into AWS Certificate Manager (ACM).
Alation recently attended AWS re:invent 2021 … in person! AWS Keynote: “Still Early Days” for Cloud. Adam Selipsky, CEO of AWS, brought this energy in his opening keynote, welcoming a packed room and looking back on the progress of AWS. Re:Invent 2021 Keynote by AWS CEO Adam Selipsky. AWS’ Top Cloud Challenges.
In this post, we show you how VistaPrint uses a combination of Amazon Personalize , Twilio Segment , and auxiliary AWS services and partner solutions to better understand their customers’ needs and provide personalized product recommendations. Transform the data to create Amazon Personalize training data.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions. The raw data is processed by an LLM using a preconfigured user prompt.
Welcome to Cloud Data Science 8. This weeks news includes information about AWS working with Azure, time-series, detecting text in videos and more. Amazon Redshift now supports Authentication with Microsoft Azure AD Redshift, a datawarehouse, from Amazon now integrates with Azure Active Directory for login.
TR has a wealth of data that could be used for personalization that has been collected from customer interactions and stored within a centralized datawarehouse. TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting.
Watsonx.data will allow users to access their data through a single point of entry and run multiple fit-for-purpose query engines across IT environments. Through workload optimization an organization can reduce datawarehouse costs by up to 50 percent by augmenting with this solution. [1]
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To capture unanticipated, less obvious data patterns, you can enable anomaly detection.
Understand data warehousing concepts: Data warehousing is the process of collecting, storing, and managing large amounts of data. Understanding how data warehousing works and how to design and implement a datawarehouse is an important skill for a data engineer.
Most enterprises today store and process vast amounts of data from various sources within a centralized repository known as a datawarehouse or data lake, where they can analyze it with advanced analytics tools to generate critical business insights.
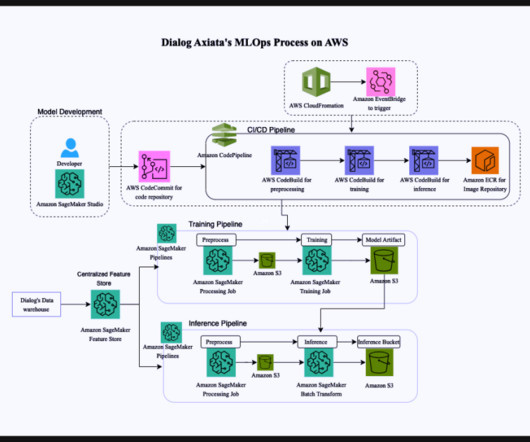
In 2022, Dialog Axiata made significant progress in their digital transformation efforts, with AWS playing a key role in this journey. Dialog Axiata runs some of their business-critical telecom workloads on AWS, including Charging Gateway, Payment Gateway, Campaign Management System, SuperApp, and various analytics tasks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content