This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
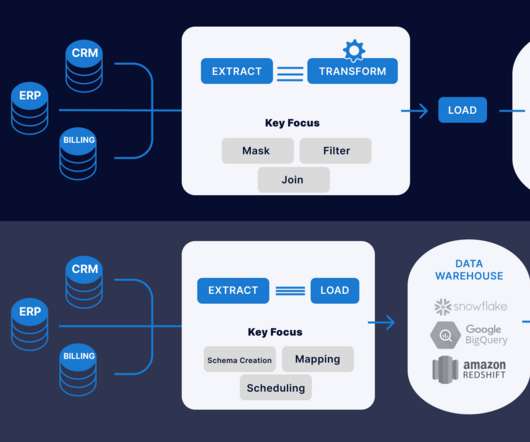
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose Create VPC.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions. The raw data is processed by an LLM using a preconfigured user prompt.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
Extraction, Transform, Load (ETL). The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To capture unanticipated, less obvious data patterns, you can enable anomaly detection.
TR has a wealth of data that could be used for personalization that has been collected from customer interactions and stored within a centralized datawarehouse. TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting.
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
In this blog, we will cover the best practices for developing jobs in Matillion, an ETL/ELT tool built specifically for cloud database platforms. Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP. It offers a cloud-agnostic data productivity hub called Matillion Data Productivity Cloud.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Data integration: Integrate data from various sources into a centralized cloud datawarehouse or data lake. Ensure that data is clean, consistent, and up-to-date.
A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a datawarehouse or data lake. Once ingested, the data is prepared through filtering, error correction, and restructuring for ease of use.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark).
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud datawarehouse like Snowflake. Review the following article for detailed steps on managing and setting up Snowflake Cortex LLM or AWS Bedrock functions.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Typically, this data is scattered across Excel files on business users’ desktops. Cloud Storage Upload Snowflake can easily upload files from cloud storage (AWS S3, Azure Storage, GCP Cloud Storage). Snowflake can not natively read files on these services, so an ETL service is needed to upload the data.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
In this blog, we’ll delve into the intricacies of data ingestion, exploring its challenges, best practices, and the tools that can help you harness the full potential of your data. Batch Processing In this method, data is collected over a period and then processed in groups or batches. The post What is Data Ingestion?
With the importance of data in various applications, there’s a need for effective solutions to organize, manage, and transfer data between systems with minimal complexity. While numerous ETL tools are available on the market, selecting the right one can be challenging. What is Fivetran?
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. The Open Connector Framework SDK enables engineers to custom-build data source connectors , which are indexed by Alation. Open Data Quality Initiative.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
So as you take inventory of your existing skill set, you’ll want to start to identify the areas where you need to focus on to become a data engineer. These areas may include SQL, database design, data warehousing, distributed systems, cloud platforms (AWS, Azure, GCP), and data pipelines. Learn more about the cloud.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content