This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The post AWS Redshift: Cloud DataWarehouse Service appeared first on Analytics Vidhya. The datasets range in size from a few 100 megabytes to a petabyte. […].
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
AWS’ Legendary Presence at DAIS: Customer Speakers, Featured Breakouts, and Live Demos! Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
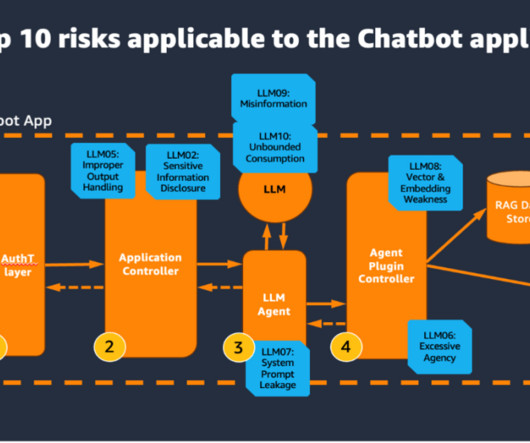
Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
The workflow includes the following steps: Within the SageMaker Canvas interface, the user composes a SQL query to run against the GCP BigQuery datawarehouse. Athena uses the Athena Google BigQuery connector , which uses a pre-built AWS Lambda function to enable Athena federated query capabilities.
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a Machine Learning Model in BigQuery appeared first on Analytics Vidhya.
Data engineering tools offer a range of features and functionalities, including data integration, data transformation, data quality management, workflow orchestration, and data visualization. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose Create VPC.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Learn SQL: As a data engineer, you will be working with large amounts of data, and SQL is the most commonly used language for interacting with databases.
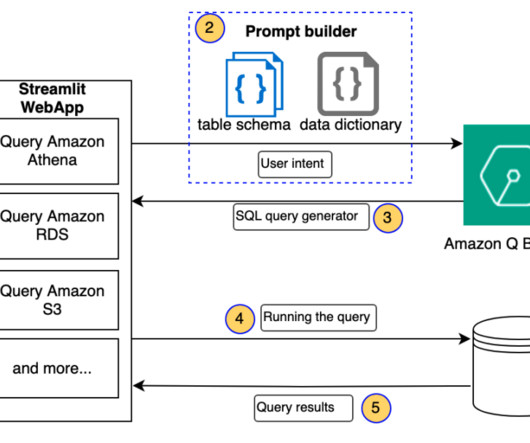
Natural language is ambiguous and imprecise, whereas data adheres to rigid schemas. For example, SQL queries can be complex and unintuitive for non-technical users. Handling complex queries involving multiple tables, joins, and aggregations makes it difficult to interpret user intent and translate it into correct SQL operations.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
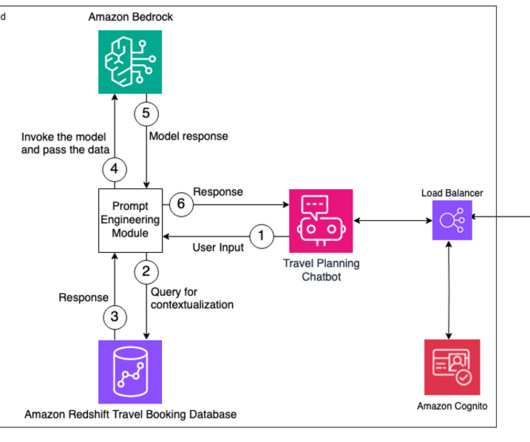
needed to address some of these challenges in one of their many AI use cases built on AWS. In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. It provides a single web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel datawarehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. SharePoint.
Azure Synapse Analytics can be seen as a merge of Azure SQLDataWarehouse and Azure Data Lake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Azure Synapse. I think this announcement will have a very large and immediate impact.
This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. Choose Grant.
Amazon Redshift has announced a feature called Amazon Redshift ML that makes it straightforward for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Redshift datawarehouses. For more details, refer to Importing a certificate.
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To capture unanticipated, less obvious data patterns, you can enable anomaly detection.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Watsonx.data will allow users to access their data through a single point of entry and run multiple fit-for-purpose query engines across IT environments. Through workload optimization an organization can reduce datawarehouse costs by up to 50 percent by augmenting with this solution. [1]
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
In our recent webcast , IBM, AWS, customers and partners came together for an interactive session. In this session: IBM and AWS discussed the benefits and features of this new fully managed offering spanning availability, security, backups, migration and more. Scalability 5. . Amazon RDS
Snowflake enables customers to store and analyze data efficiently—giving them the ability to scale their datawarehouse up and down with demands. Impactful Technology Solution of the Year: AWS. This solution has been highlighted across numerous AWS events such as re:Invent 2020 and TC-ish. We appreciate you AWS!
Amazon Redshift is a fully managed, fast, secure, and scalable cloud datawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. All SageMaker Studio traffic is through the specified VPC and subnets.
One of the main drivers for this problem is that most analytic systems are built within the context of a unified SQL environment. Getting all the data together, in one place, and integrated is generally the main goal of ourwork. Unfortunately in analytic systems, we have been doing little other than tight coupling for decades.
While not all of us are tech enthusiasts, we all have a fair knowledge of how Data Science works in our day-to-day lives. All of this is based on Data Science which is […]. The post Step-by-Step Roadmap to Become a Data Engineer in 2023 appeared first on Analytics Vidhya.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Developers can leverage features like REST APIs, JSON support and enhanced SQL compatibility to easily build cloud-native applications. Chamberlin and Raymond F.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses. Cost : Is the pricing predictable and within budget?
In the fast-moving world of data, the Snowflake AI Data Cloud has established itself as an essential part of the Modern Data Stack. Through its versatile platform, organizations can build efficient datawarehouses and harness the power of data monetization via Secure Data Shares, accessible through the Snowflake Marketplace.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Thankfully, there are tools available to help with metadata management, such as AWS Glue, Azure Data Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content