This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
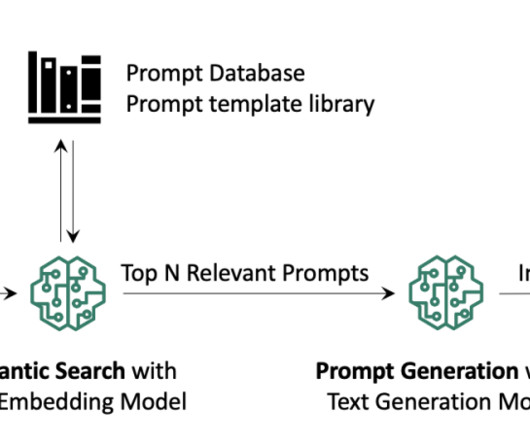
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment. Fetch information for the database tables from the Data Catalog.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Introduction S3 is Amazon Web Services cloud-based object storage service (AWS). S3 provides a simple web interface for uploading and downloading data and a powerful set of APIs for developers to integrate S3. S3 […] The post Top 6 Amazon S3 Interview Questions appeared first on Analytics Vidhya.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The user receives a more accurate response based on their query.
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. Install Python 3.7
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. First, it enables you to include both image and text features in a single database and therefore reduces complexity. You may be prompted to subscribe to this model through AWS Marketplace.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. Open the AWS Management Console, go to Amazon Bedrock, and choose Model access in the navigation pane.
Photo by Caspar Camille Rubin on Unsplash AWS Athena is a serverless interactive query system. The sample data used in this article can be downloaded from the link below, Fruit and Vegetable Prices How much do fruits and vegetables cost? Go to the AWS Glue Console. Next step we want to specify the database. That is it!!
Managing your Amazon Lex bots using AWS CloudFormation allows you to create templates defining the bot and all the AWS resources it depends on. AWS CloudFormation provides and configures those resources on your behalf, removing the risk of human error when deploying bots to new environments. Resources: # 1.
Dataset and background The MIMIC Chest X-ray (MIMIC-CXR) database v2.0.0 Because we used only the radiology report text data, we downloaded just one compressed report file (mimic-cxr-reports.zip) from the MIMIC-CXR website. Dr. Ekta Walia Bhullar is a principal AI/ML/GenAI consultant with AWS Healthcare and Life Sciences business unit.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
In this post, we use Amazon Comprehend and other AWS services to analyze and extract new insights from a repository of documents. To begin, we gather the data to be analyzed and load it into an Amazon Simple Storage Service (Amazon S3) bucket in an AWS account. This file needs to be download and converted to a non-compressed format.
In this post, we describe the scale of our AI offerings, the challenges with diverse AI workloads, and how we optimized mixed AI workload inference performance with AWS Graviton3 based c7g instances and achieved 20% throughput improvement, 30% latency reduction, and reduced our cost by 25–30%.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
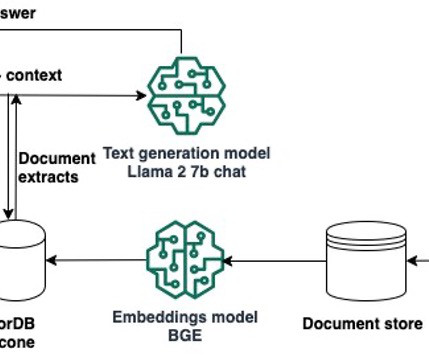
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
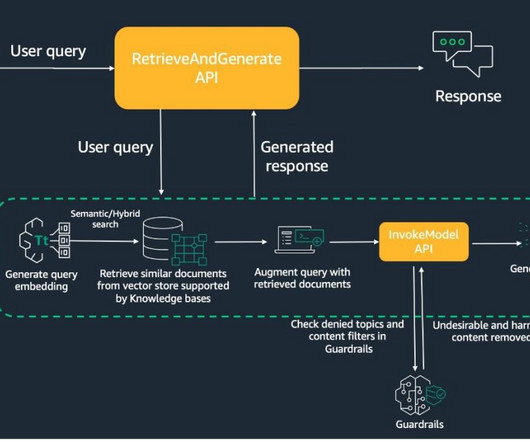
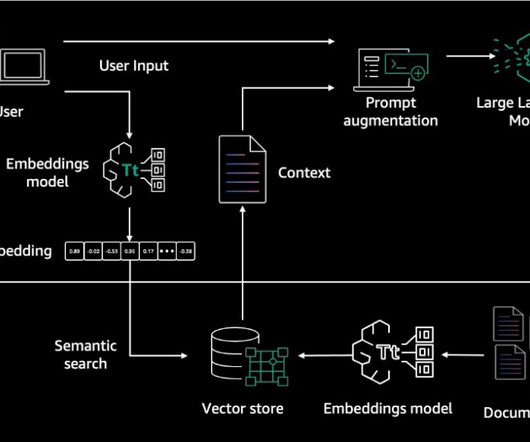
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. When a user asks a question, it searches the vector database and retrieves documents that are most similar to the user’s query.
In addition to Amazon Bedrock, you can use other AWS services like Amazon SageMaker JumpStart and Amazon Lex to create fully automated and easily adaptable generative AI order processing agents. In this post, we show you how to build a speech-capable order processing agent using Amazon Lex, Amazon Bedrock, and AWS Lambda.
AWS makes it possible for organizations of all sizes and developers of all skill levels to build and scale generative AI applications with security, privacy, and responsible AI. In this post, we dive into the architecture and implementation details of GenASL, which uses AWS generative AI capabilities to create human-like ASL avatar videos.
In this post, we demonstrate a solution using Amazon FSx for NetApp ONTAP with Amazon Bedrock to provide a RAG experience for your generative AI applications on AWS by bringing company-specific, unstructured user file data to Amazon Bedrock in a straightforward, fast, and secure way. The following diagram illustrates the end-to-end flow.
Second, using this graph database along with generative AI to detect second and third-order impacts from news events. With AWS, you can deploy this solution in a serverless, scalable, and fully event-driven architecture. With AWS, you can deploy this solution in a serverless, scalable, and fully event-driven architecture.
models are available in SageMaker JumpStart initially in the US East (Ohio) AWS Region. The models can be provisioned on dedicated SageMaker Inference instances, including AWS Trainium and AWS Inferentia powered instances, and are isolated within your virtual private cloud (VPC). Prerequisites To try out the Llama 3.2
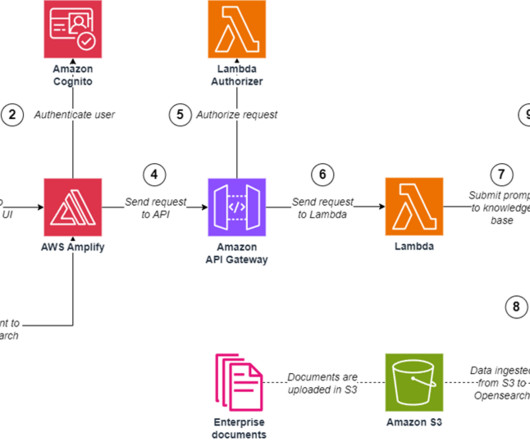
AWS Amplify to create and deploy the web application. Amazon API Gateway and AWS Lambda to create an API with an authentication layer and integrate with Amazon Bedrock. The AWS Well-Architected Framework documentation. The Implementing Microservices on AWS whitepaper. Refer to the Amazon Bedrock FAQs for further details.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a user name, password, and database name. About the authors Adeleke Coker is a Global Solutions Architect with AWS.
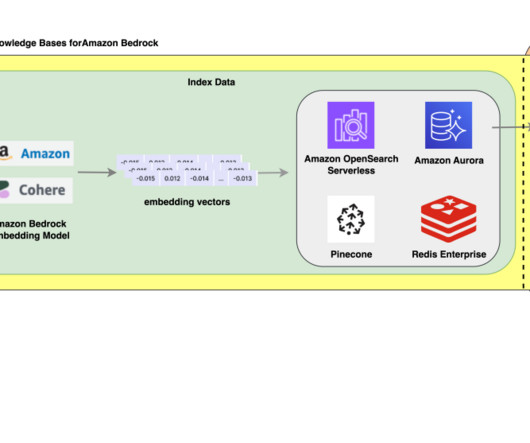
By default, knowledge bases allow your RAG applications to query the entire vector database, accessing all records and retrieving relevant results. If you want to follow along in your AWS account, download the file. In the Vector database section, choose Quick create a new vector store.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Second, you might need to build text-to-SQL features for every database because data is often not stored in a single target. Our solution aims to address those challenges using Amazon Bedrock and AWS Analytics Services.
Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution. The document embeddings are split into chunks and stored as indexes in a vector database. We use the Amazon letters to shareholders dataset to develop this solution.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. You will execute scripts to create an AWS Identity and Access Management (IAM) role for invoking SageMaker, and a role for your user to create a connector to SageMaker.
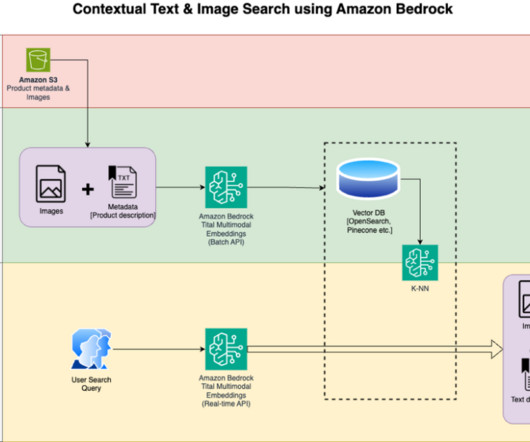
and AWS services including Amazon Bedrock and Amazon SageMaker to perform similar generative tasks on multimodal data. We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. We also use SageMaker notebooks to orchestrate and demonstrate this solution end to end.
Prerequisites You should have some knowledge of generative AI, ML, and the services used in this solution, including Amazon Bedrock, Amazon ECS, Amazon CloudFront, Elastic Load Balancing, Amazon DynamoDB and Amazon S3 We use AWS CDK to build and deploy the solution. It uses the function download_image to download an image from the S3 bucket.
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. join(batch_text_arr) s3.put_object(
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
At AWS re:Invent 2023, we announced the general availability of Knowledge Bases for Amazon Bedrock. You can query using either the AWS Management Console or SDK. If you want to follow along in your own AWS account, download the file. In the Vector database section, choose Quick create a new vector store.
In November 2022, we announced that AWS customers can generate images from text with Stable Diffusion models in Amazon SageMaker JumpStart , a machine learning (ML) hub offering models, algorithms, and solutions. AWS provides a plethora of options and services to facilitate this endeavor.
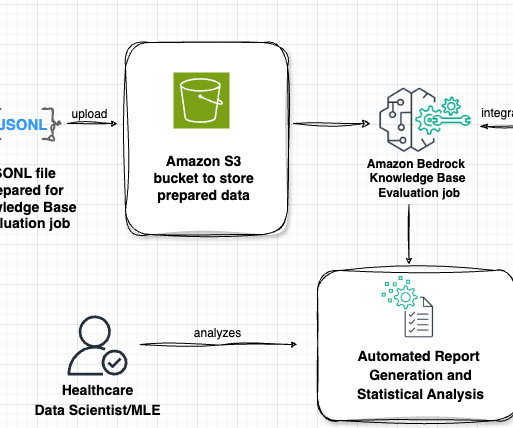
After the documents are successfully copied to the S3 bucket, the event automatically invokes an AWS Lambda The Lambda function invokes the Amazon Bedrock knowledge base API to extract embeddings—essential data representations—from the uploaded documents. Choose the AWS Region where you want to create the bucket. Choose Create bucket.
To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import , a feature that you can use to import customized models created in other environments—such as Amazon SageMaker , Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock.
The application sends the user query to the vector database to find similar documents. The QnA application submits a request to the SageMaker JumpStart model endpoint with the user query and context returned from the vector database. Basic familiarity with SageMaker and AWS services that support LLMs.
With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. Virginia) and US West (Oregon) AWS Regions.
This includes provisioning Amazon Simple Storage Service (Amazon S3) buckets, AWS Identity and Access Management (IAM) access permissions, Snowflake storage integration for individual users, and an ongoing mechanism to manage or clean up data copies in Amazon S3. An AWS account with admin access. This is a one-time setup.
Built on AWS technologies like AWS Lambda , Amazon API Gateway , and Amazon DynamoDB , this tool automates the creation of customizable templates and supports both text and image inputs. The API generates pre-signed URLs for image uploads and downloads to and from an S3 bucket (S3 Images).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content