This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” The post AWS Glue: Simplifying ETL Data Processing appeared first on Analytics Vidhya. For the […].
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
Translation memory A translation memory is a database that stores previously translated text segments (typically sentences or phrases) along with their corresponding translations. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
This year’s AWS re:Invent conference, held in Las Vegas from November 27 through December 1, showcased the advancements of Amazon Redshift to help you further accelerate your journey towards modernizing your cloud analytics environments.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
Database Analyst Description Database Analysts focus on managing, analyzing, and optimizing data to support decision-making processes within an organization. They work closely with database administrators to ensure data integrity, develop reporting tools, and conduct thorough analyses to inform business strategies.
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. The following Terraform script will create an Azure Resource Group, a SQL Server, and a SQL Database. So why using IaC for Cloud Data Infrastructures?
High-performance, low-footprint SQL database written in C++. Supports powerful features like JOIN, CDC, UPSERT, and LOOKUP, enabling real-time analytics and ETL at scale. Process millions of rows per second from Kafka, Pulsar, or ClickHouse, and seamlessly write results back.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
Photo by Caspar Camille Rubin on Unsplash AWS Athena is a serverless interactive query system. Glue Crawler Setup The next step is setting up a Glue crawler to extract the schema of this file and create a database. Go to the AWS Glue Console. Create a Glue Job to perform ETL operations on your data. That is it!!
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like data warehouses. What is ETL? What are ETL Tools?
Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database. Incoming questions are converted to embeddings, and then the vector database runs a similarity search to find related content. The question and the reference data then go into the prompt for the LLM.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
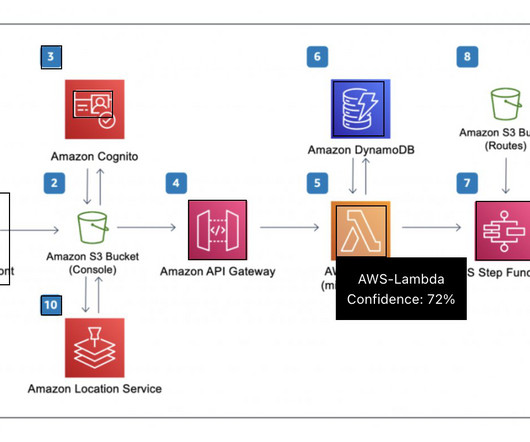
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. This allows for data to be aggregated for further manufacturer-agnostic analysis.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
Embeddings generation – An embeddings model is used to encode the semantic information of each chunk into an embeddings vector, which is stored in a vector database, enabling similarity search of user queries. Based on the query embeddings, the relevant documents are retrieved from the embeddings database using similarity search.
Extraction, Transform, Load (ETL). AWS Glue helps users to build data catalogues, and Quicksight provides data visualisation and dashboard construction. The services from AWS can be catered to meet the needs of each business user. Databases can be SQL or Blob storage for unstructured object data. Master data management.
Welcome to our AWS Redshift to the Snowflake Data Cloud migration blog! In this blog, we’ll walk you through the process of migrating your data from AWS Redshift to the Snowflake Data Cloud. One popular route is leveraging third-party ETL tools like Fivetran to ensure a smooth and successful migration.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Data Architect Designs complex databases and blueprints for data management systems.
Big data pipelines operate similarly to traditional ETL (Extract, Transform, Load) pipelines but are designed to handle much larger data volumes. Components of a Big Data Pipeline Data Sources (Collection): Data originates from various sources, such as databases, APIs, and log files.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
The following diagram illustrates the architecture of a news recommender application powered by Amazon Personalize and supporting AWS services. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. Happy building!
It consolidates data from various systems, such as transactional databases, CRM platforms, and external data sources, enabling organizations to perform complex queries and derive insights. Evaluate integration capabilities with existing data sources and Extract Transform and Load (ETL) tools.
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases. Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Ensure that data is clean, consistent, and up-to-date.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content