This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
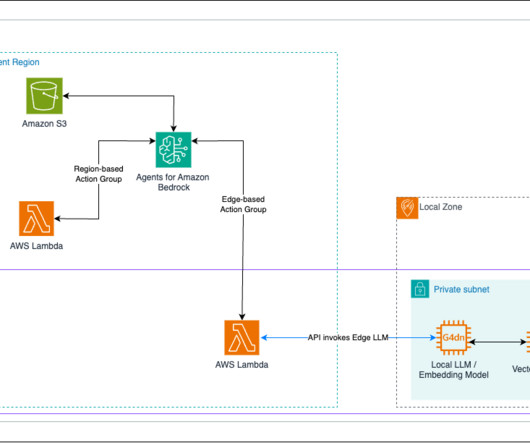
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. It works by analyzing the visual content to find similar images in its database. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
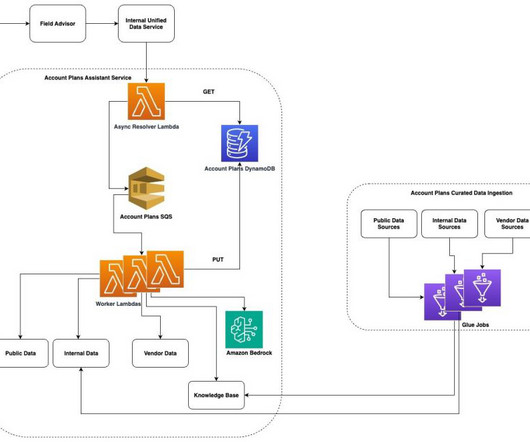
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. Some applications may need to access data with personal identifiable information (PII) while others may rely on noncritical data.
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. This can lead to inefficiencies, delays, and errors, diminishing customer satisfaction.
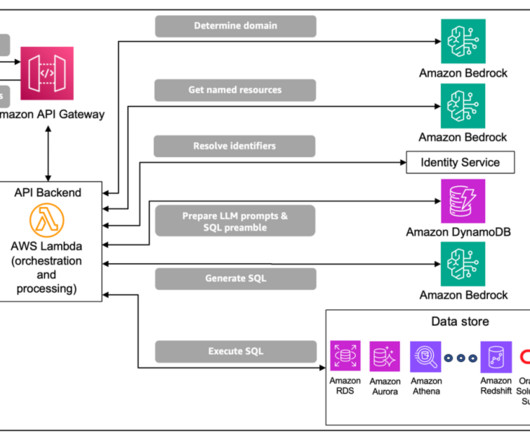
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. As a result, NL2SQL solutions for enterprise data are often incomplete or inaccurate.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. For sales representatives, it empowers them with deeper insights, enabling more informed recommendations.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.
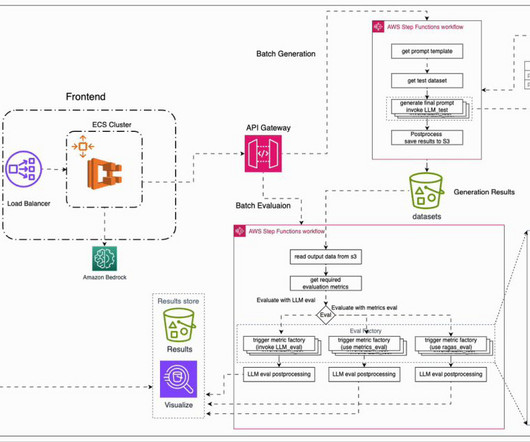
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
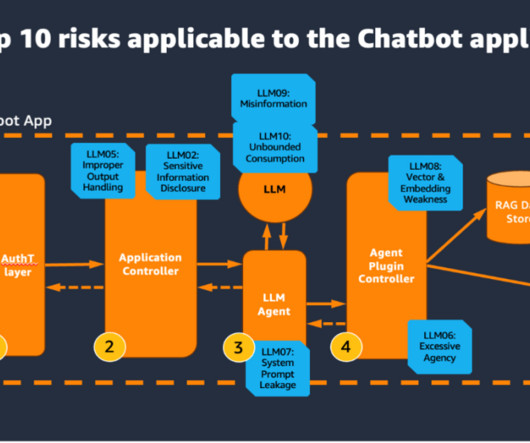
Retrieval Augmented Generation (RAG) applications have become increasingly popular due to their ability to enhance generative AI tasks with contextually relevant information. To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models.
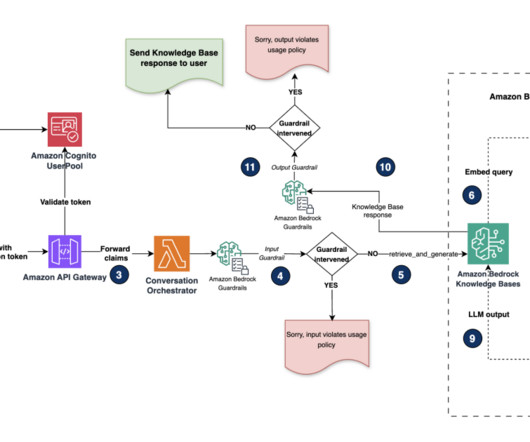
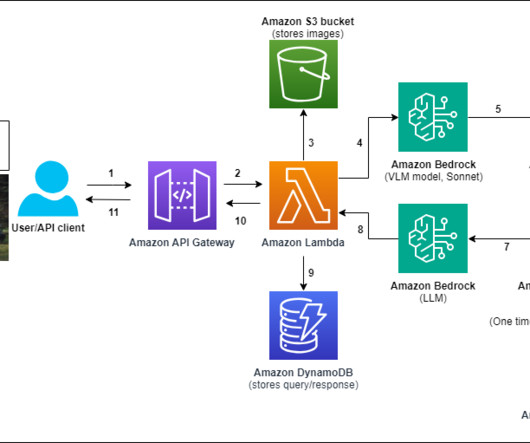
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Despite their wealth of general knowledge, state-of-the-art LLMs only have access to the information they were trained on. This can lead to factual inaccuracies (hallucinations) when the LLM is prompted to generate text based on information they didn’t see during their training.
Robust evaluation methodologies enable informed decision-making regarding the choice of models and prompts. In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. Methods such as human evaluation provide valuable insights but are costly and difficult to scale.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Without proper data segregation, companies risk exposing sensitive information between customers or creating complex, hard-to-maintain systems.
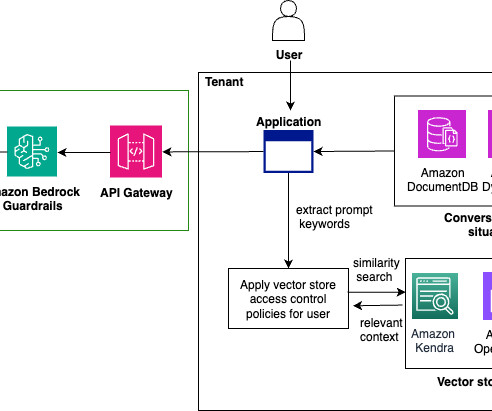
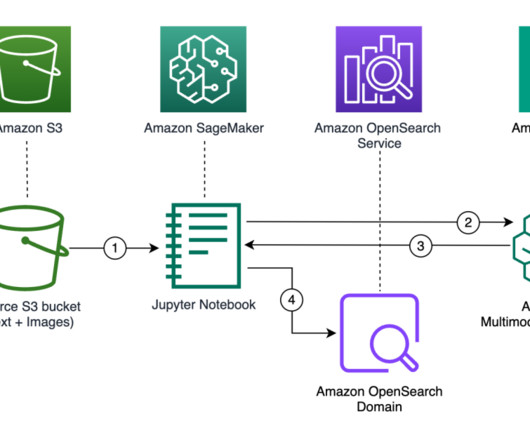
In semantic search, documents are stored as vectors, a numeric representation of the document content, in a vector database such as Amazon OpenSearch Service , and are retrieved by performing similarity search with a vector representation of the search query. The following diagram depicts the solution architecture.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. These challenges manifest in two key ways: through inherent model vulnerabilities and adversarial threats.
These models are designed to understand and generate text about images, bridging the gap between visual information and natural language. Solution overview For our custom multimodal chat assistant, we start by creating a vector database of relevant text documents that will be used to answer user queries. us-east-1 or bash deploy.sh
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (Natural Language Processing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. Its a fully managed service that you can use to deploy, operate, and scale OpenSearch on AWS. OpenSearch is a distributed open-source search and analytics engine composed of a search engine and vector database. An OpenSearch Service domain.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
The results are shown in a Streamlit app, with the invoices and extracted information displayed side-by-side for quick review. After uploading, you can set up a regular batch job to process these invoices, extract key information, and save the results in a JSON file. Make sure your AWS credentials are configured correctly.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach can also enhance the quality of retrieved information and responses generated by the RAG applications.
Their knowledge is static and confined to the information they were trained on, which becomes problematic when dealing with dynamic and constantly evolving domains like healthcare. Furthermore, healthcare decisions often require integrating information from multiple sources, such as medical literature, clinical databases, and patient records.
Agent function calling represents a critical capability for modern AI applications, allowing models to interact with external tools, databases, and APIs by accurately determining when and how to invoke specific functions. You can track these job status details in both the AWS Management Console and AWS SDK.
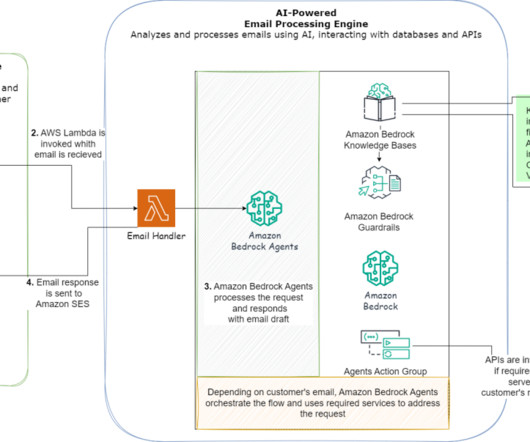
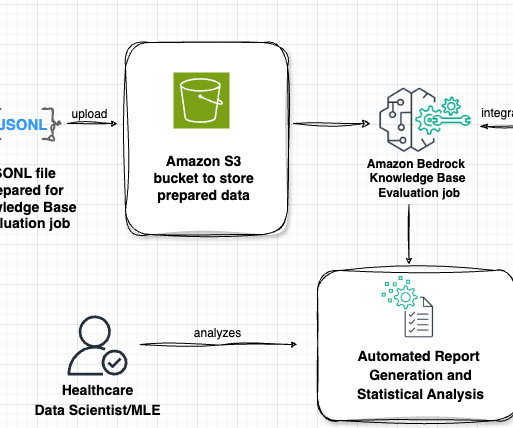
Amazon Bedrock Agents uses the reasoning of foundation models (FMs) available on Amazon Bedrock , APIs, and data to break down user requests, gather relevant information, and efficiently complete tasksfreeing teams to focus on high-value work. Similarly, text-to-SQL evaluations will be run on the biomarker database analyst sub-agent.
These meetings often involve exchanging information and discussing actions that one or more parties must take after the session. This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
Thats why we at Amazon Web Services (AWS) are working on AI Workforcea system that uses drones and AI to make these inspections safer, faster, and more accurate. This post is the first in a three-part series exploring AI Workforce, the AWS AI-powered drone inspection system. In this post, we introduce the concept and key benefits.
Dynamic content, including user-specific information, should be placed at the end of the prompt. n - Select quotes that provide key information, context, or support for the answer." n - Provide a clear, concise, and accurate answer to the question based on the information in the document." "n 2][3]'" "nn5.
Overview of multimodal embeddings and multimodal RAG architectures Multimodal embeddings are mathematical representations that integrate information not only from text but from multiple data modalities—such as product images, graphs, and charts—into a unified vector space.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Through real-time retrieval of relevant medical information, RAG systems can provide more reliable and contextually appropriate responses, making them particularly valuable for healthcare applications where precision is crucial. Dataset and background The MIMIC Chest X-ray (MIMIC-CXR) database v2.0.0
Our e-commerce recommendations engine is driven by ML; the paths that optimize robotic picking routes in our fulfillment centers are driven by ML; and our supply chain, forecasting, and capacity planning are informed by ML. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
Amazon Q Business is a fully managed generative AI-powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. Who are the data stewards for my proprietary database sources?
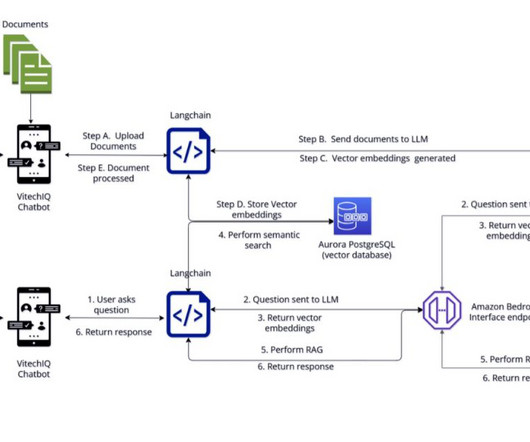
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders).
The AWS Social Responsibility & Impact (SRI) team recognized an opportunity to augment this function using generative AI. Historically, AWS Health Equity Initiative applications were reviewed manually by a review committee. Start with a default score of 0 and increase it based on the information in the proposal.
Today at the AWS New York Summit, we announced a wide range of capabilities for customers to tailor generative AI to their needs and realize the benefits of generative AI faster. Each application can be immediately scaled to thousands of users and is secure and fully managed by AWS, eliminating the need for any operational expertise.
It covers a range of topics including generative AI, LLM basics, natural language processing, vector databases, prompt engineering, and much more. You get a chance to work on various projects that involve practical exercises with vector databases, embeddings, and deployment frameworks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content