This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
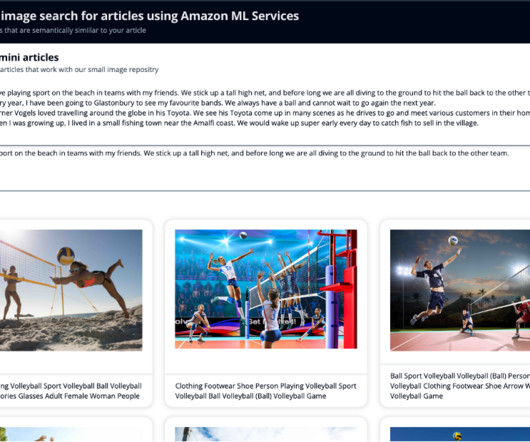
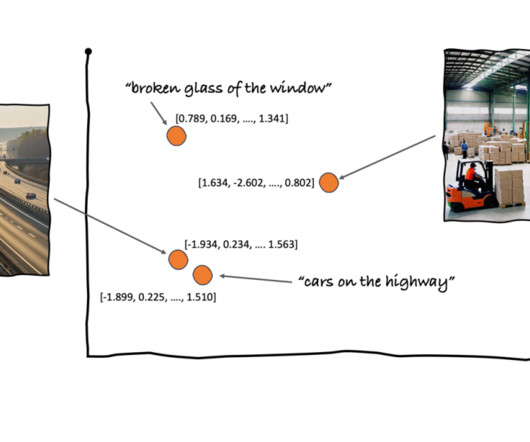
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. Display results : Display the top K similar results to the user.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. Interested users are invited to try out FloTorch from AWS Marketplace or from GitHub.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
The available data sources are: Stock Prices Database Contains historical stock price data for publicly traded companies. Analyst Notes Database Knowledge base containing reports from Analysts on their interpretation and analyis of economic events. Stock Prices Database The question is about a stock price.
The listing indexer AWS Lambda function continuously polls the queue and processes incoming listing updates. These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
It also relies on the images in the repository being tagged correctly, which can also be automated (for a customer success story, refer to Aller Media Finds Success with KeyCore and AWS ). In this post, we demonstrate how to use Amazon Rekognition , Amazon SageMaker JumpStart , and Amazon OpenSearch Service to solve this business problem.
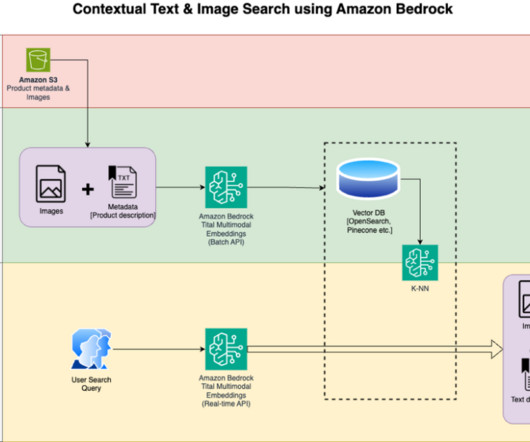
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality. Virginia) and US West (Oregon) AWS Regions.
This post shows you how to set up RAG using DeepSeek-R1 on Amazon SageMaker with an OpenSearch Service vector database as the knowledge base. You will execute scripts to create an AWS Identity and Access Management (IAM) role for invoking SageMaker, and a role for your user to create a connector to SageMaker.
and AWS services including Amazon Bedrock and Amazon SageMaker to perform similar generative tasks on multimodal data. We use OpenSearch Serverless as a vector database for storing embeddings generated by the Titan Multimodal Embeddings model. Setting k=1 retrieves the most relevant slide to the user question.
Kinesis Video Streams makes it straightforward to securely stream video from connected devices to AWS for analytics, machine learning (ML), playback, and other processing. This solution was created with AWS Amplify. It enables real-time video ingestion, storage, encoding, and streaming across devices.
Many AWS media and entertainment customers license IMDb data through AWS Data Exchange to improve content discovery and increase customer engagement and retention. We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. Background. Solution overview. Launch solution resources.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
The integration with Amazon Bedrock is achieved through the Boto3 Python module, which serves as an interface to the AWS, enabling seamless interaction with Amazon Bedrock and the deployment of the classification model. Take the first step in your generative AI transformationconnect with an AWS expert today to begin your journey.
The whole process is shown in the following image: Implementation steps This solution has been tested in AWS Region us-east-1. To set up a JupyterLab space Sign in to your AWS account and open the AWS Management Console. However, it can also work in other Regions where the following services are available.
Structured data refers to neatly organised data that fits into tables, such as spreadsheets or databases, where each column represents a feature and each row represents an instance. This data can come from databases, APIs, or public datasets. K-NearestNeighbors), while others can handle large datasets efficiently (e.g.,
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. You can do this by deleting the stacks using the AWS CloudFormation console.
The AWS Generative AI Innovation Center (GenAIIC) is a team of AWS science and strategy experts who have deep knowledge of generative AI. They help AWS customers jumpstart their generative AI journey by building proofs of concept that use generative AI to bring business value. doc,pdf, or.txt).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content