

Unlocking the power of Model Context Protocol (MCP) on AWS
JUNE 3, 2025
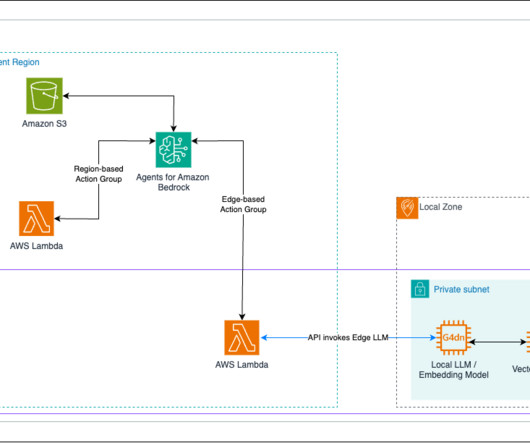
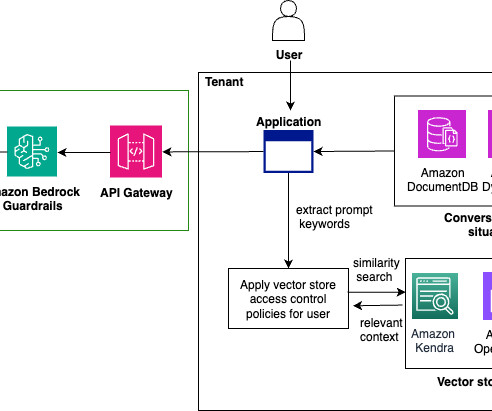
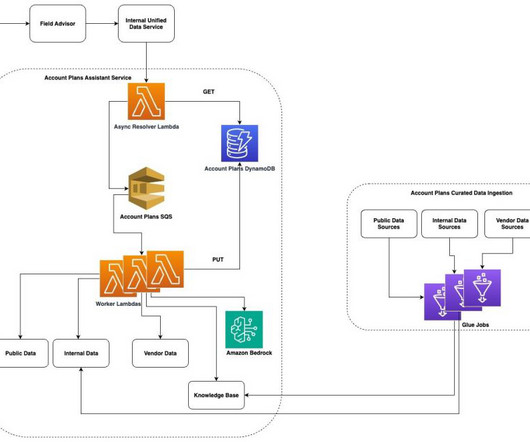
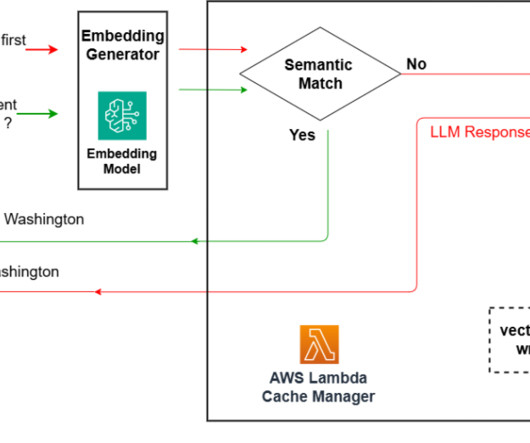
If youre an AI-focused developer, technical decision-maker, or solution architect working with Amazon Web Services (AWS) and language models, youve likely encountered these obstacles firsthand. Why MCP matters for AWS users For AWS customers, MCP represents a particularly compelling opportunity. What is the MCP?









































Let's personalize your content