This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
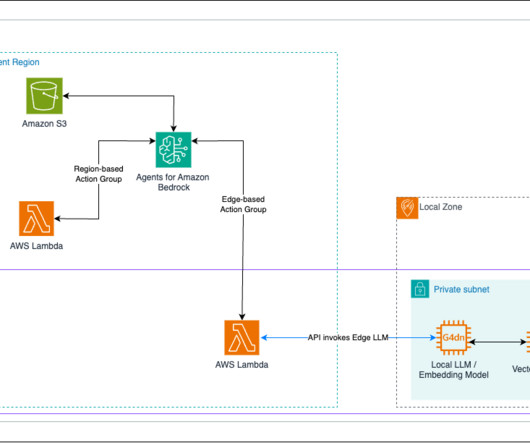
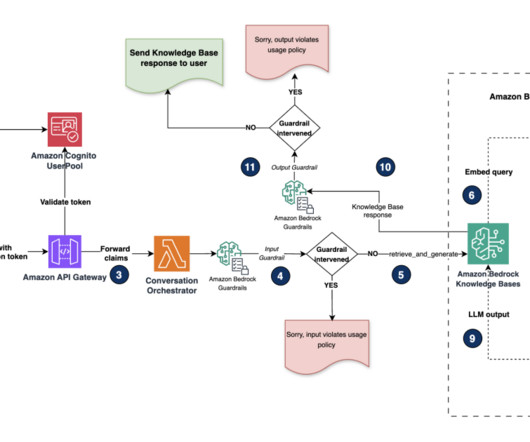
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
InterVision Systems, LLC (InterVision), an AWS Premier Tier Services Partner and Amazon Connect Service Delivery Partner, has been at the forefront of this transformation, with their contact center solution designed specifically for city and county services called ConnectIV CX for Community Engagement.
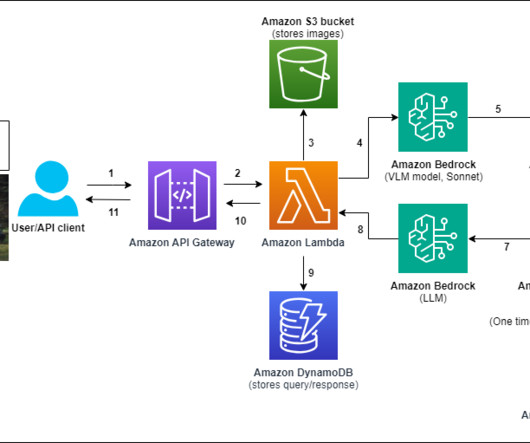
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. Alternatively, you can use Amazon DynamoDB , a serverless, fully managed NoSQL database, to store your prompts.
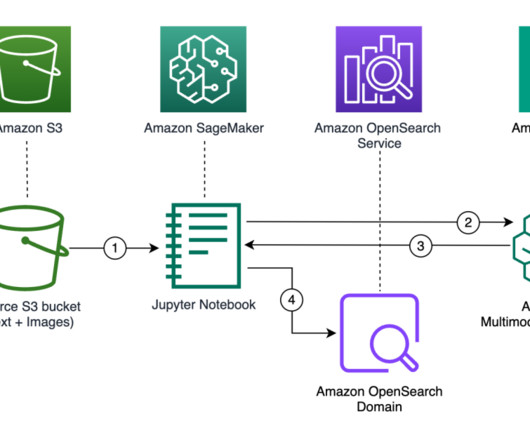
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
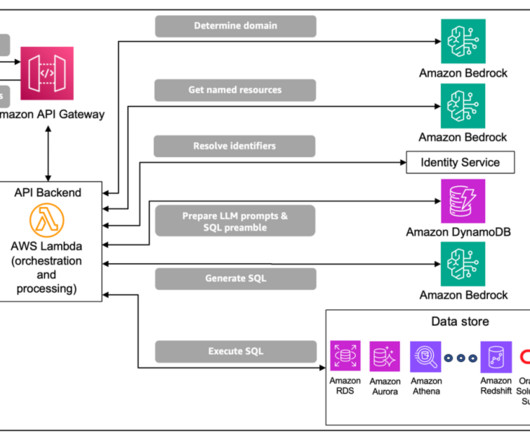
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval. As a result, NL2SQL solutions for enterprise data are often incomplete or inaccurate.
AWS), an Amazon.com, Inc. company (NASDAQ: AMZN), today announced the AWS Generative AI Innovation Center, a new program to help customers successfully build and deploy generative artificial intelligence (AI) solutions. Amazon Web Services, Inc.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. Let’s understand how these AWS services are integrated in detail.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. Deploy the AWS CDK project to provision the required resources in your AWS account.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
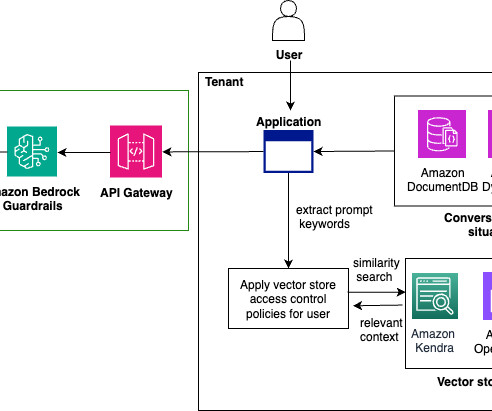
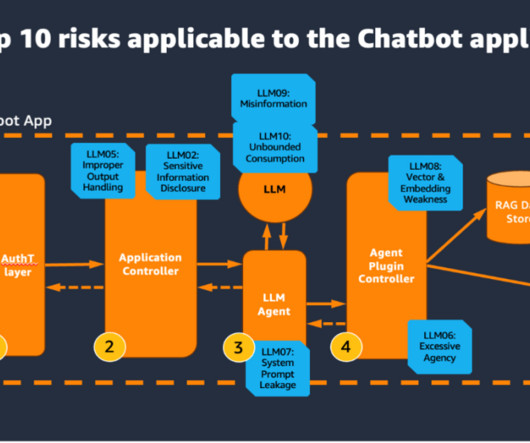
To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models. For all data stored in Amazon Bedrock, the AWS shared responsibility model applies. The following diagram illustrates how RBAC works with metadata filtering in the vector database.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. are the sessions dedicated to AWS DeepRacer ! are the sessions dedicated to AWS DeepRacer !
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The user receives a more accurate response based on their query.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of scalable compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are transforming their businesses.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. Post-authentication, users access the UI Layer, a gateway to the Red Teaming Playground built on AWS Amplify and React.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Learn more about the AWS zero-ETL future with newly launched AWSdatabases integrations with Amazon Redshift.
Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications. Demand for applied ML scientists remains high, as more companies focus on AI-driven solutions for scalability.
Thats why we at Amazon Web Services (AWS) are working on AI Workforcea system that uses drones and AI to make these inspections safer, faster, and more accurate. This post is the first in a three-part series exploring AI Workforce, the AWS AI-powered drone inspection system. In this post, we introduce the concept and key benefits.
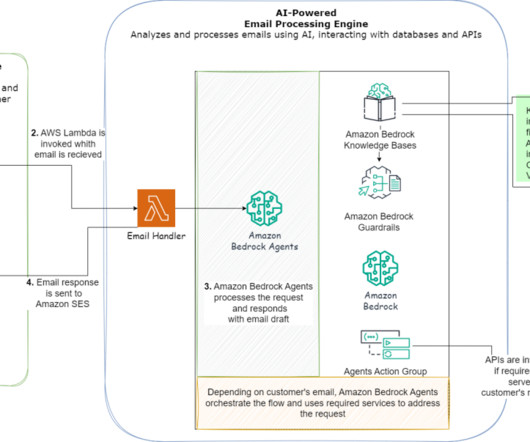
Furthermore, healthcare decisions often require integrating information from multiple sources, such as medical literature, clinical databases, and patient records. AWS Lambda orchestrator, along with tool configuration and prompts, handles orchestration and invokes the Mistral model on Amazon Bedrock.
In this post, we show how to create a multimodal chat assistant on Amazon Web Services (AWS) using Amazon Bedrock models, where users can submit images and questions, and text responses will be sourced from a closed set of proprietary documents. For this post, we recommend activating these models in the us-east-1 or us-west-2 AWS Region.
OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. Its a fully managed service that you can use to deploy, operate, and scale OpenSearch on AWS. OpenSearch is a distributed open-source search and analytics engine composed of a search engine and vector database. An OpenSearch Service domain.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
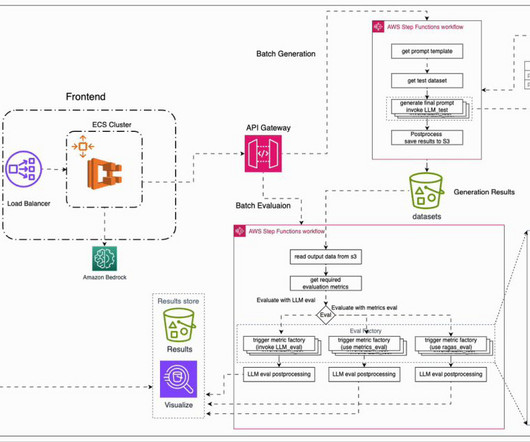
In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. We also provide LLM-as-a-judge evaluation metrics using the newly released Amazon Nova models.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. You can obtain the SageMaker Unified Studio URL for your domains by accessing the AWS Management Console for Amazon DataZone.
In semantic search, documents are stored as vectors, a numeric representation of the document content, in a vector database such as Amazon OpenSearch Service , and are retrieved by performing similarity search with a vector representation of the search query. If you don’t already have an AWS account, you can create one.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
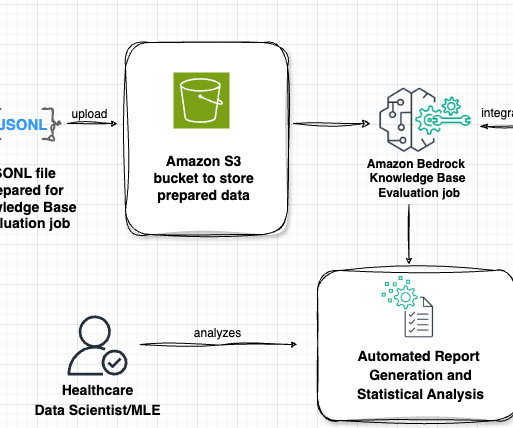
Dataset and background The MIMIC Chest X-ray (MIMIC-CXR) database v2.0.0 Data ScientistGenerative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS. She has extensive experience in development of AI/ML applications for healthcare especially in Radiology.
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. The workflow steps are as follows: AWS Lambda running in your private VPC subnet receives the prompt request from the generative AI application.
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. First, it enables you to include both image and text features in a single database and therefore reduces complexity. You may be prompted to subscribe to this model through AWS Marketplace.
It showcases a variety of specialized agents, including a biomarker database analyst, statistician, clinical evidence researcher, and medical imaging expert in collaboration with a supervisor agent. Similarly, text-to-SQL evaluations will be run on the biomarker database analyst sub-agent.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Specifically, it:nn1.
What Zeta has accomplished in AI/ML In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
In this post, we describe the scale of our AI offerings, the challenges with diverse AI workloads, and how we optimized mixed AI workload inference performance with AWS Graviton3 based c7g instances and achieved 20% throughput improvement, 30% latency reduction, and reduced our cost by 25–30%.
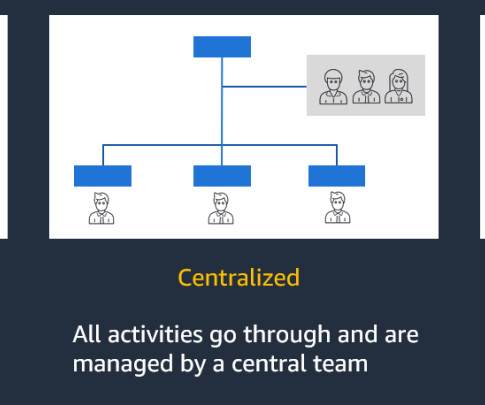
Large organizations often have many business units with multiple lines of business (LOBs), with a central governing entity, and typically use AWS Organizations with an Amazon Web Services (AWS) multi-account strategy. LOBs have autonomy over their AI workflows, models, and data within their respective AWS accounts.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
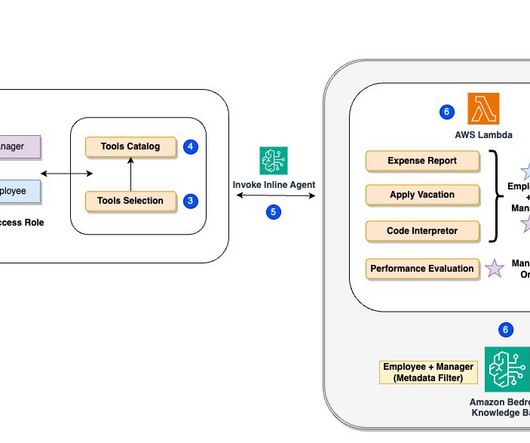
AWS Lambda functions for executing specific actions (such as submitting vacation requests or expense reports). With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. Nitin Eusebius is a Sr.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content