This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
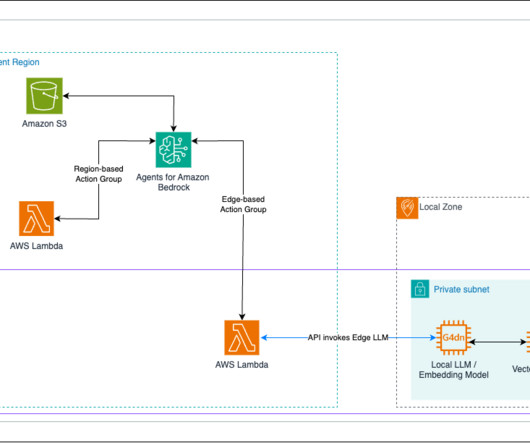
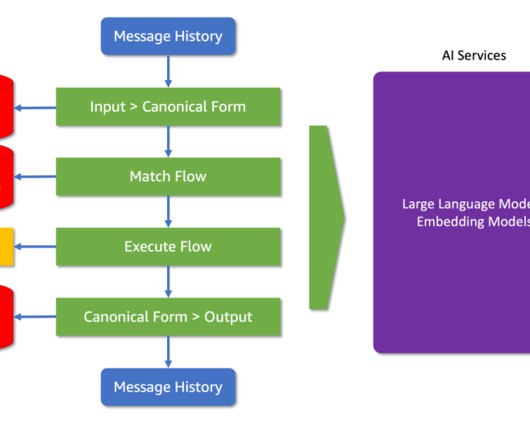
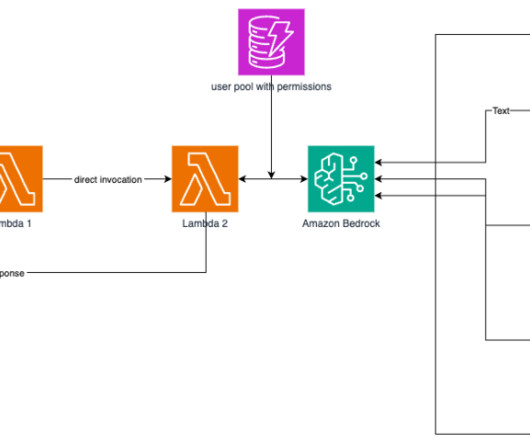
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
Lettria , an AWS Partner, demonstrated that integrating graph-based structures into RAG workflows improves answer precision by up to 35% compared to vector-only retrieval methods. In this post, we explore why GraphRAG is more comprehensive and explainable than vector RAG alone, and how you can use this approach using AWS services and Lettria.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (NaturalLanguageProcessing) for patient and genomic data analysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
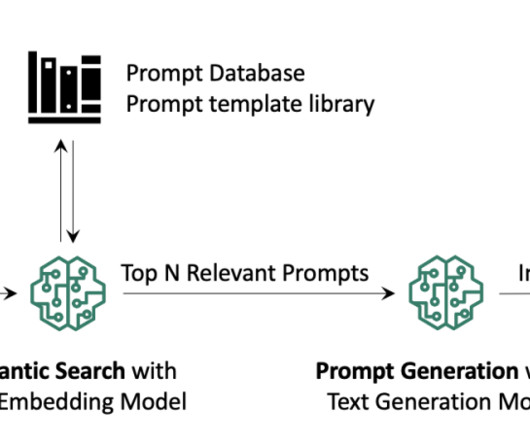
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The user receives a more accurate response based on their query.
Large language models (LLMs) have revolutionized the field of naturallanguageprocessing, enabling machines to understand and generate human-like text with remarkable accuracy. However, despite their impressive language capabilities, LLMs are inherently limited by the data they were trained on.
The learning program is typically designed for working professionals who want to learn about the advancing technological landscape of language models and learn to apply it to their work. It covers a range of topics including generative AI, LLM basics, naturallanguageprocessing, vector databases, prompt engineering, and much more.
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI.
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Let’s understand how these AWS services are integrated in detail.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. However, as data becomes increasingly multimodal in nature, extending these systems to handle various data types is crucial to provide more comprehensive and contextually rich responses.
This arduous, time-consuming process is typically the first step in the grant management process, which is critical to driving meaningful social impact. The AWS Social Responsibility & Impact (SRI) team recognized an opportunity to augment this function using generative AI. These are stored in the DynamoDB database.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. The solution’s scalability quickly accommodates growing data volumes and user queries thanks to AWS serverless offerings.
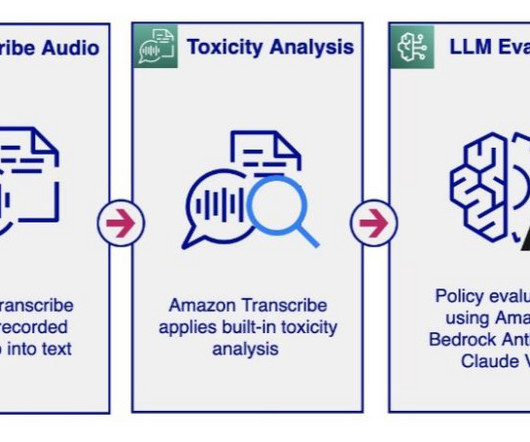
In this post, we introduce solutions that enable audio and text chat moderation using various AWS services, including Amazon Transcribe , Amazon Comprehend , Amazon Bedrock , and Amazon OpenSearch Service. OpenSearch Service is a fully managed service that makes it straightforward to deploy, scale, and operate OpenSearch in the AWS Cloud.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
To help tackle this challenge, Accenture collaborated with AWS to build an innovative generative AI solution called Knowledge Assist. By using AWS generative AI services, the team has developed a system that can ingest and comprehend massive amounts of unstructured enterprise content.
Advancements in AI and naturallanguageprocessing (NLP) show promise to help lawyers with their work, but the legal industry also has valid questions around the accuracy and costs of these new techniques, as well as how customer data will be kept private and secure. These capabilities are built using the AWS Cloud.
Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity. During this journey, we collaborated with our AWS technical account manager and the Graviton software engineering teams.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
Using an Amazon Q Business custom data source connector , you can gain insights into your organizations third party applications with the integration of generative AI and naturallanguageprocessing. Who are the data stewards for my proprietary database sources?
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. The same approach can be used with different models and vector databases. embeddings.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels. Solution requirements Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS.
Implementing a multi-modal agent with AWS consolidates key insights from diverse structured and unstructured data on a large scale. All this is achieved using AWS services, thereby increasing the financial analyst’s efficiency to analyze multi-modal financial data (text, speech, and tabular data) holistically.
Amazon Comprehend is a fully, managed service that uses naturallanguageprocessing (NLP) to extract insights about the content of documents. In this post, we use Amazon Comprehend and other AWS services to analyze and extract new insights from a repository of documents. In this example, we use text formatted files.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. You can use it via either the Amazon Bedrock REST API or the AWS SDK.
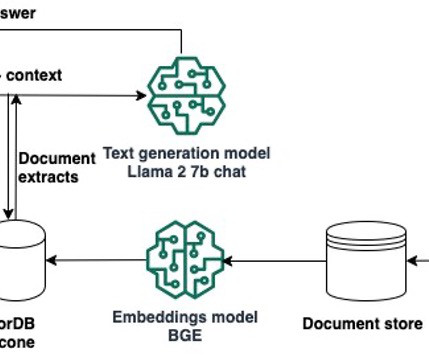
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
One such area that is evolving is using naturallanguageprocessing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data. The raw data is processed by an LLM using a preconfigured user prompt. The Step Functions workflow starts.
AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. I acknowledge that AWS CloudFormation might create IAM resources with custom names. I acknowledge that AWS CloudFormation might require the following capability: CAPABILITY_AUTO_EXPAND checkboxes and choose Submit.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. In the second post , we present the use cases and dataset to show its effectiveness in analyzing real-world healthcare datasets, such as the eICU data , which comprises a multi-center critical care database collected from over 200 hospitals.
As large language models (LLMs) become increasingly integrated into customer-facing applications, organizations are exploring ways to leverage their naturallanguageprocessing capabilities. These vectors are then stored in a vector database designed to efficiently search and retrieve closely related semantic information.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. These steps are completed prior to the user interaction steps.
AI code generation works through a combination of machine learning, naturallanguageprocessing (NLP), and large language models ( LLMs ). Here’s a breakdown of the process: Input Interpretation : The AI-first understands user input, which can be plain language (e.g., AWS Lambda, S3, EC2).
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL. We use Anthropic Claude v2.1
Key AWS services used include: Amazon Bedrock Including Anthropics Claude 3.5 Sonnet model for naturallanguageprocessing. Additionally, if a user tells the assistant something that should be remembered, we store this piece of information in a database and add it to the context every time the user initiates a request.
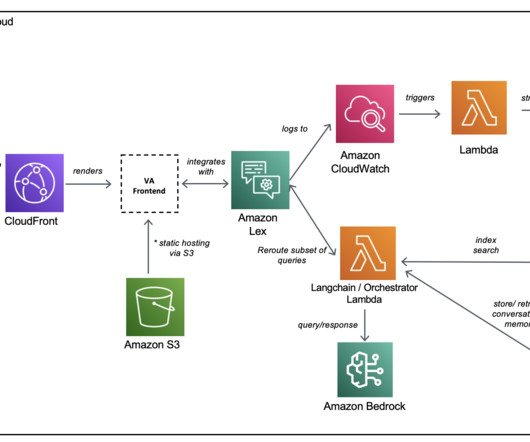
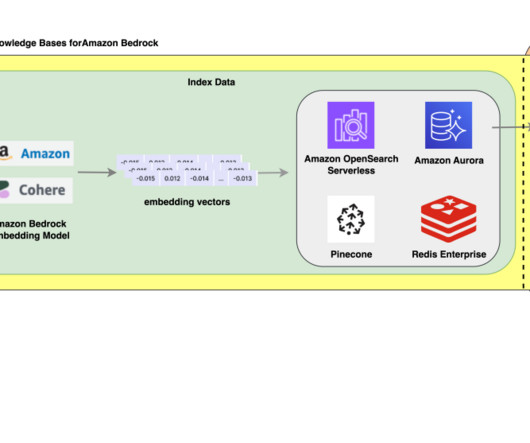
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. We use Knowledge Bases for Amazon Bedrock to fetch from historical data stored as embeddings in the Amazon OpenSearch Service vector database. It serves as the data source to the knowledge base.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
In November 2022, we announced that AWS customers can generate images from text with Stable Diffusion models in Amazon SageMaker JumpStart , a machine learning (ML) hub offering models, algorithms, and solutions. This technique is particularly useful for knowledge-intensive naturallanguageprocessing (NLP) tasks.
Second, using this graph database along with generative AI to detect second and third-order impacts from news events. With AWS, you can deploy this solution in a serverless, scalable, and fully event-driven architecture. With AWS, you can deploy this solution in a serverless, scalable, and fully event-driven architecture.
Google AutoML for NaturalLanguage goes GA Extracting meaning from text is still a challenging and important task faced by many organizations. Google AutoML for NLP (NaturalLanguageProcessing) provides sentiment analysis, classification, and entity extraction from text. It now also supports PDF documents.
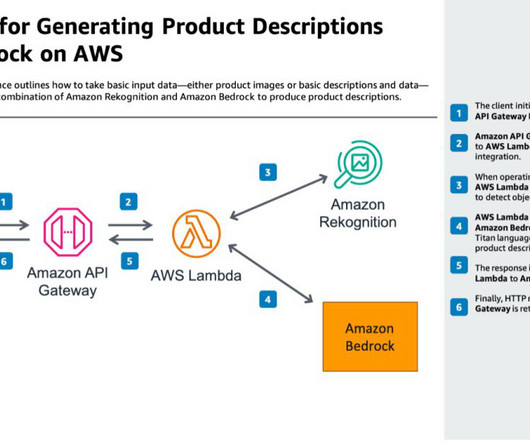
This solution is available in the AWS Solutions Library. AWS Lambda – AWS Lambda provides serverless compute for processing. Product database – The central repository stores vendor products, images, labels, and generated descriptions. This could be any database of your choice.
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















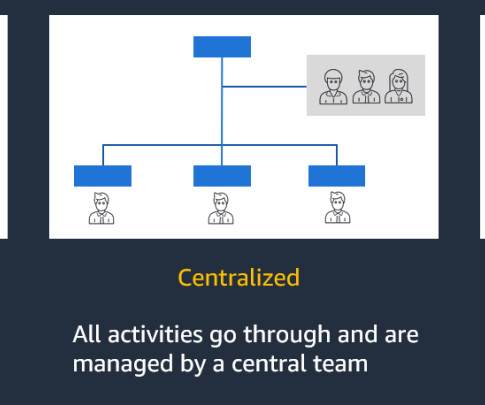
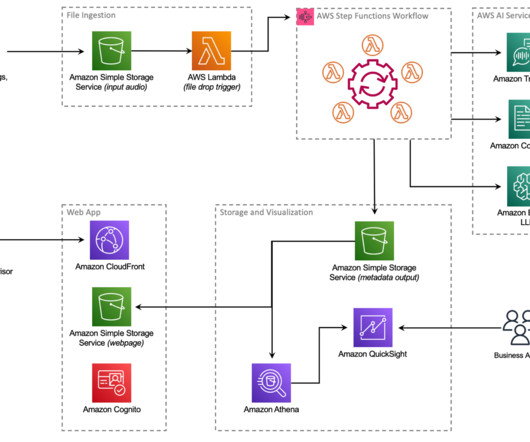

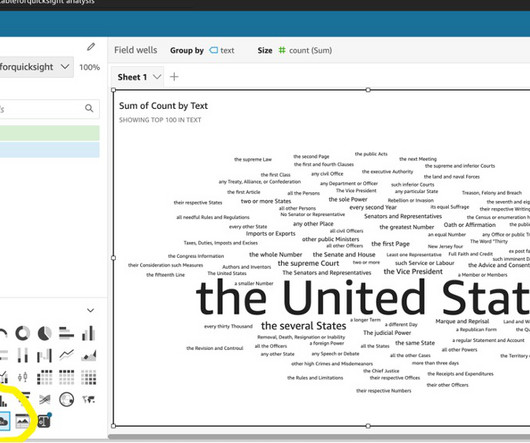

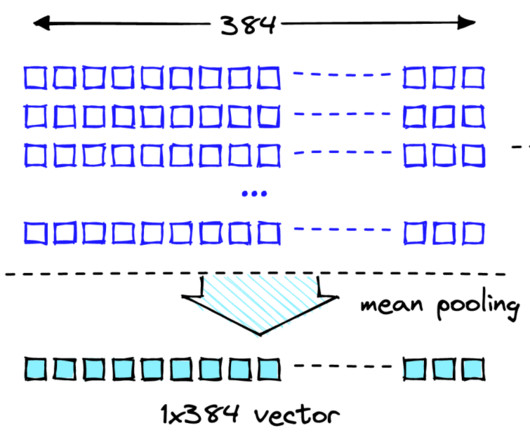


















Let's personalize your content