This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Amazon Athena is an interactive query service based on open-source Apache Presto that allows you to analyze data stored in Amazon S3 using ANSI SQL directly. The post How is AWS Athena Different from other Databases appeared first on Analytics Vidhya.
These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval.
Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. The post AWS Redshift: Cloud Data Warehouse Service appeared first on Analytics Vidhya. The datasets range in size from a few 100 megabytes to a petabyte. […].
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
The post Using AWS Athena and QuickSight for Data Analysis appeared first on Analytics Vidhya. Also, have you ever tried doing this with Athena and QuickSight? This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. Amazon’s perfect combination of […].
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Source: Link Introduction In this article, we are going to talk about a dynamo DB a No-SQL, and a very highly scalable database provided by Amazon AWS. DynamoDB is a scalable hosted NoSQL database service that offers low latency and key-value pair databases. It is […].
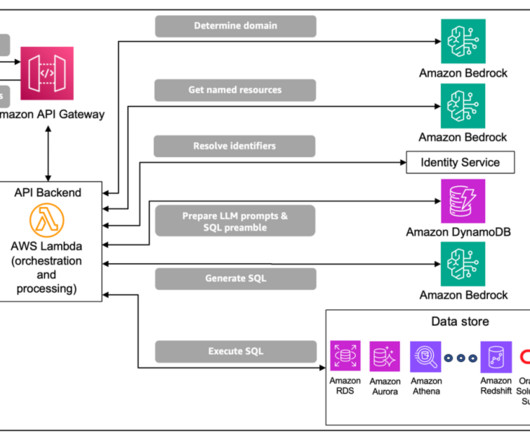
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. Alternatively, you can use Amazon DynamoDB , a serverless, fully managed NoSQL database, to store your prompts.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
Introduction Amazon Athena is an interactive query tool supplied by Amazon Web Services (AWS) that allows you to use conventional SQL queries to evaluate data stored in Amazon S3. Athena is a serverless service. Thus there are no servers to operate, and you pay for the queries you perform.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Database Analyst Description Database Analysts focus on managing, analyzing, and optimizing data to support decision-making processes within an organization. They work closely with database administrators to ensure data integrity, develop reporting tools, and conduct thorough analyses to inform business strategies.
They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference. Previously, data scientists often found themselves juggling multiple tools to support SQL in their workflow, which hindered productivity.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI).
This year’s AWS re:Invent conference, held in Las Vegas from November 27 through December 1, showcased the advancements of Amazon Redshift to help you further accelerate your journey towards modernizing your cloud analytics environments.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
The following Terraform script will create an Azure Resource Group, a SQL Server, and a SQLDatabase. AWS CloudFormation is a service offered by Amazon Web Services (AWS) that allows you to define cloud infrastructure in JSON or YAML templates. So why using IaC for Cloud Data Infrastructures?
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. With the emergence of large language models (LLMs), NLP-based SQL generation has undergone a significant transformation.
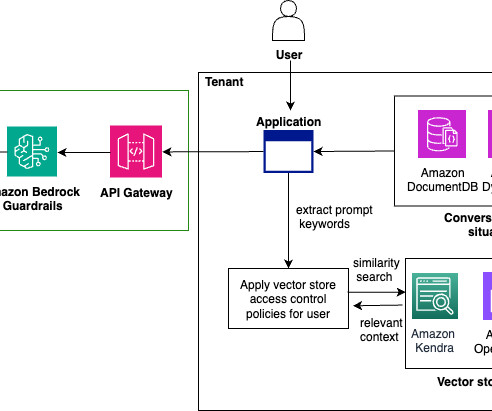
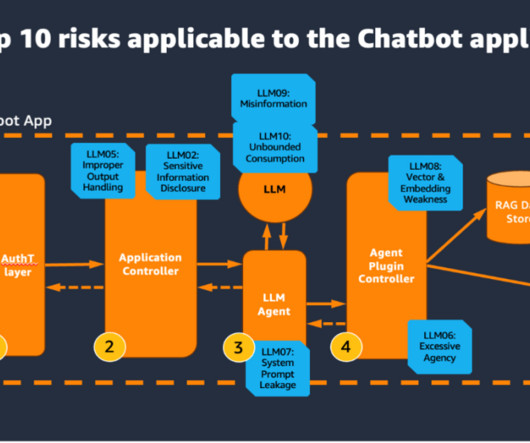
Use the AWS generative AI scoping framework to understand the specific mix of the shared responsibility for the security controls applicable to your application. The following figure of the AWS Generative AI Security Scoping Matrix summarizes the types of models for each scope.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. The framework for connecting Anthropic Claude 2 and CBRE’s sample database was implemented using LangChain.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. Basic knowledge of a SQL query editor. Database name : Enter dev. Database user : Enter awsuser.
The data is stored in a data lake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. Data is normally stored in databases, and can be queried using the most common query language, SQL. Constructing SQL queries from natural language isn’t a simple task.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Managing and retrieving the right information can be complex, especially for data analysts working with large data lakes and complex SQL queries.
In this post, we save the data in JSON format, but you can also choose to store it in your preferred SQL or NoSQL database. Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. Install Python 3.7
Managing cloud costs and understanding resource usage can be a daunting task, especially for organizations with complex AWS deployments. AWS Cost and Usage Reports (AWS CUR) provides valuable data insights, but interpreting and querying the raw data can be challenging.
Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation. By using fit-for-purpose databases, customers can efficiently run workloads, using the appropriate engine at the optimal cost to optimize analytics for the best price-performance.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import , a feature that you can use to import customized models created in other environments—such as Amazon SageMaker , Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock.
At AWS, we have played a key role in democratizing ML and making it accessible to anyone who wants to use it, including more than 100,000 customers of all sizes and industries. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
In this post, we explore what an audience overlap analysis is, discuss the current technical approaches and their challenges, and illustrate how you can run secure audience overlap analysis using AWS Clean Rooms. With AWS Clean Rooms, you can create a data clean room in minutes and collaborate with your partners to generate unique insights.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
With the rapid growth of generative artificial intelligence (AI), many AWS customers are looking to take advantage of publicly available foundation models (FMs) and technologies. Meta Llama 3’s capabilities enhance accuracy and efficiency in understanding and generating SQL queries from natural language inputs.
With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents.
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. The primary goal is to automatically generate SQL queries from natural language text. What percentage of customers are from each region?”
For instance, analyzing large tables might require prompting the LLM to generate Python or SQL and running it, rather than passing the tabular data to the LLM. The available data sources are: Stock Prices Database Contains historical stock price data for publicly traded companies. We give more details on that aspect later in this post.
High-performance, low-footprint SQLdatabase written in C++. Process millions of rows per second from Kafka, Pulsar, or ClickHouse, and seamlessly write results back. Supports powerful features like JOIN, CDC, UPSERT, and LOOKUP, enabling real-time analytics and ETL at scale.
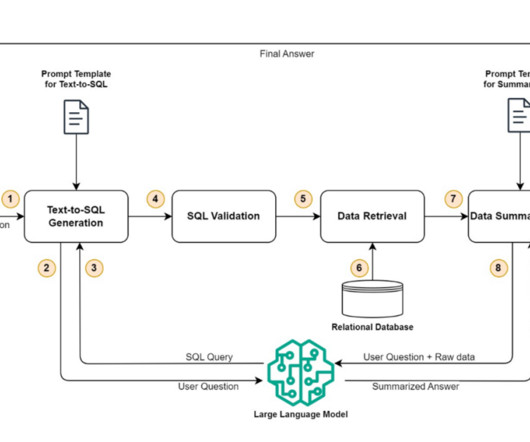
From a broad perspective, the complete solution can be divided into four distinct steps: text-to-SQL generation, SQL validation, data retrieval, and data summarization. A pre-configured prompt template is used to call the LLM and generate a valid SQL query. The following diagram illustrates this workflow.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQLdatabase involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
needed to address some of these challenges in one of their many AI use cases built on AWS. In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. To retrieve data from database, you can use foundation models (FMs) offered by Amazon Bedrock, converting text into SQL queries with specified constraints.
Photo by Caspar Camille Rubin on Unsplash AWS Athena is a serverless interactive query system. So if you are familiar with the Standard SQL queries, you are good to go!! Glue Crawler Setup The next step is setting up a Glue crawler to extract the schema of this file and create a database. Go to the AWS Glue Console.
Implementing a multi-modal agent with AWS consolidates key insights from diverse structured and unstructured data on a large scale. All this is achieved using AWS services, thereby increasing the financial analyst’s efficiency to analyze multi-modal financial data (text, speech, and tabular data) holistically.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content