This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A lot of missing values in the dataset can affect the quality of prediction in the long run. Several methods can be used to fill the missing values and Datawig is one of the most efficient ones.
Neuron is the SDK used to run deeplearning workloads on Trainium and Inferentia based instances. AWS AI chips, Trainium and Inferentia, enable you to build and deploy generative AI models at higher performance and lower cost. To get started, see AWS Inferentia and AWS Trainium Monitoring.
This article was published as a part of the Data Science Blogathon The speed of Deeplearning and neural networks is increasingly indispensable for thousands of industries. The post Serverless Tensorflow on AWS Lambda – A Tutorial For beginners appeared first on Analytics Vidhya.
Introduction You must have noticed that for training a very heavy deeplearning model, you required a GPU which is mostly available at a very high cost.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). It uses deeplearning to convert audio to text quickly and accurately. To address this, Intact turned to AI and speech-to-text technology to unlock insights from calls and improve customer service.
AWS), an Amazon.com, Inc. company (NASDAQ: AMZN), today announced the AWS Generative AI Innovation Center, a new program to help customers successfully build and deploy generative artificial intelligence (AI) solutions. Amazon Web Services, Inc.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWSDeepLearning AMIs) and Neuron DLCs (AWSDeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS Systems Manager Parameter Store support Neuron 2.18
GTC—Amazon Web Services (AWS), an Amazon.com company (NASDAQ: AMZN), and NVIDIA (NASDAQ: NVDA) today announced that the new NVIDIA Blackwell GPU platform—unveiled by NVIDIA at GTC 2024—is coming to AWS.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
Amazon Web Services (AWS) announced the general availability of Amazon DataZone, a data management service that enables customers to catalog, discover, govern, share, and analyze data at scale across organizational boundaries.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Today, we’ll explore why Amazon’s cloud-based machine learning services could be your perfect starting point for building AI-powered applications.
Prime Air (our drones) and the computer vision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deeplearning. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
Large-scale deeplearning has recently produced revolutionary advances in a vast array of fields. is a startup dedicated to the mission of democratizing artificial intelligence technologies through algorithmic and software innovations that fundamentally change the economics of deeplearning. Founded in 2021, ThirdAI Corp.
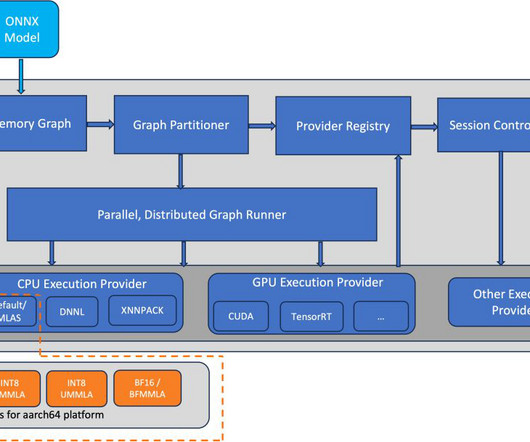
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
In this article, we shall discuss the upcoming innovations in the field of artificial intelligence, big data, machine learning and overall, Data Science Trends in 2022. Deeplearning, natural language processing, and computer vision are examples […]. Times change, technology improves and our lives get better.
Today, we are introducing three key advancements that further expand our AI inference capabilities: NVIDIA NIM microservices are now available in AWS Marketplace for SageMaker Inference deployments , providing customers with easy access to state-of-the-art generative AI models. or Mixtral.
Photo by Marius Masalar on Unsplash Deeplearning. A subset of machine learning utilizing multilayered neural networks, otherwise known as deep neural networks. If you’re getting started with deeplearning, you’ll find yourself overwhelmed with the amount of frameworks. Let’s answer that question.
Objective To learn how to use Amazon Sagemaker to Train and Deploy a Hugging Face Transformer Model. Prerequisites Basic Knowledge of AWS cloud and Hugging Face Transformers. This article was published as a part of the Data Science Blogathon. Amazon Sagemaker offers […].
There are several ways AWS is enabling ML practitioners to lower the environmental impact of their workloads. Inferentia and Trainium are AWS’s recent addition to its portfolio of purpose-built accelerators specifically designed by Amazon’s Annapurna Labs for ML inference and training workloads. times higher inference throughput.
About the Authors Melanie Li , PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions leveraging state-of-the-art AI and machine learning tools. Vivek Gangasani is a Senior GenAI Specialist Solutions Architect at AWS.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
Example code The following code example is a Python script that can be used as an AWS Lambda function or as part of your processing pipeline. Combined with AWS tool offerings such as AWS Lambda and Amazon SageMaker, you can implement such open source tools for your applications.
At AWS re:Invent 2024, we are excited to introduce Amazon Bedrock Marketplace. Through Bedrock Marketplace, organizations can use Nemotron’s advanced capabilities while benefiting from the scalable infrastructure of AWS and NVIDIA’s robust technologies. About the authors James Park is a Solutions Architect at Amazon Web Services.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. Additionally, we discuss how to handle integrations with AWS Lambda and Amazon CloudWatch after enabling Global Resiliency. We walk through the instructions to replicate the bot later in this post.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
In this post, we showcase fine-tuning a Llama 2 model using a Parameter-Efficient Fine-Tuning (PEFT) method and deploy the fine-tuned model on AWS Inferentia2. We use the AWS Neuron software development kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance.
AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Prerequisites If youre new to AWS, you first need to create and set up an AWS account. We use Amazon S3 to store sample documents that are used in this solution.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Cloud Computing: AWS, Google Cloud, Azure (for deploying AI models) Soft Skills: 1. Adaptability and Continuous Learning 4.
Amazon Web Services (AWS) offers AWS Network Firewall, a stateful, managed network firewall that includes intrusion detection and prevention (IDP) for your Amazon Virtual Private Cloud (VPC)."nn[2] nnAnswer:nThis document is a technical blog post that focuses on cost considerations and logging options for AWS Network Firewall.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deeplearning container (DLC). The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deeplearning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. This feature is only supported when using inference components. dkr.ecr.amazonaws.com/huggingface-pytorch-tgi-inference:2.4.0-tgi2.4.0-gpu-py311-cu124-ubuntu22.04-v2.0",
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. The example extracts and contextualizes the buildspec-1-10-2.yml
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. Surya Kari is a Senior Generative AI Data Scientist at AWS.
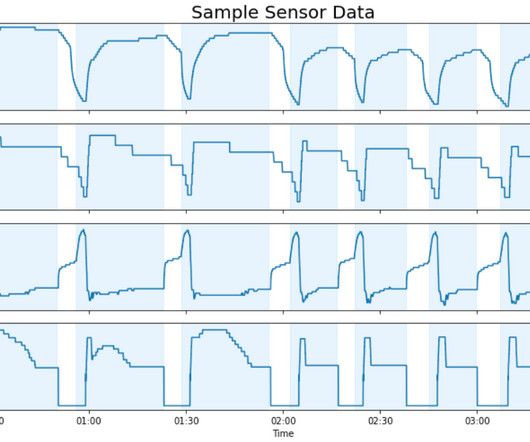
In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. We first highlight how we use AWS Glue for highly parallel data processing. AWS Glue allowed us to easily run parallel data preprocessing and feature extraction. Additionally, 10.4%
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content