This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
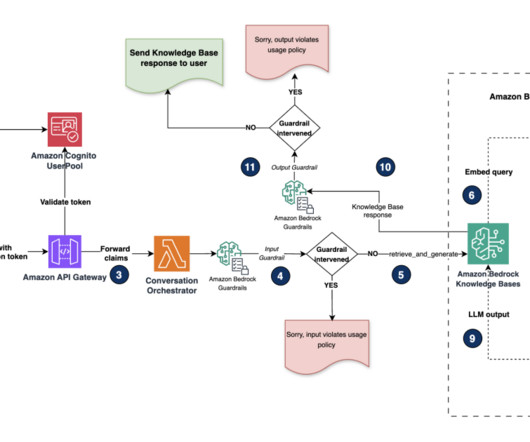
To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models. Document chunks are then encoded with an embedding model to convert them to document embeddings. For all data stored in Amazon Bedrock, the AWS shared responsibility model applies.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWSDeepLearning AMIs) and Neuron DLCs (AWSDeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS Systems Manager Parameter Store support Neuron 2.18
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Today, we’ll explore why Amazon’s cloud-based machine learning services could be your perfect starting point for building AI-powered applications.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
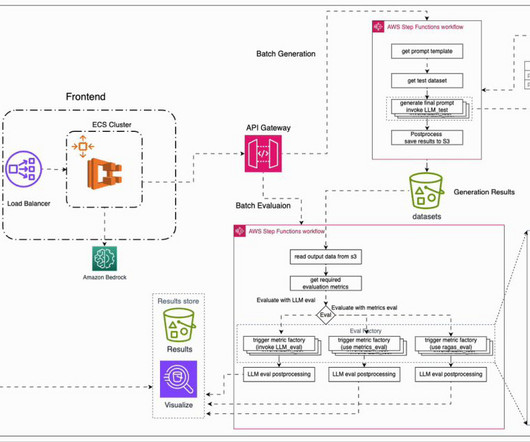
In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. The UI service can be run locally in a Docker container or deployed to AWS Fargate.
There are several ways AWS is enabling ML practitioners to lower the environmental impact of their workloads. Inferentia and Trainium are AWS’s recent addition to its portfolio of purpose-built accelerators specifically designed by Amazon’s Annapurna Labs for ML inference and training workloads.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
With a dramatic increase on supported context length from 128K in Llama 3 , Llama 4 is now suitable for multi-document summarization, parsing extensive user activity for personalized tasks, and reasoning over extensive codebases. Virginia) AWS Region. An AWS Identity and Access Management (IAM) role to access SageMaker AI.
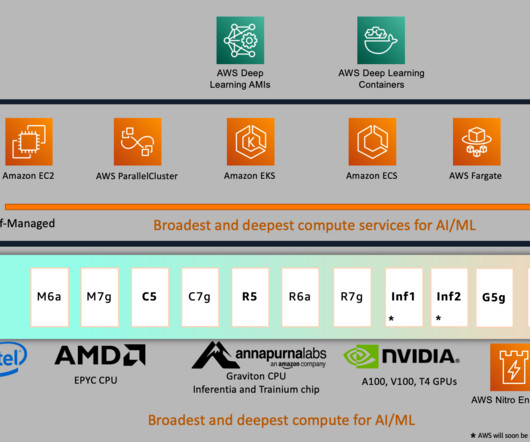
Prime Air (our drones) and the computer vision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deeplearning. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
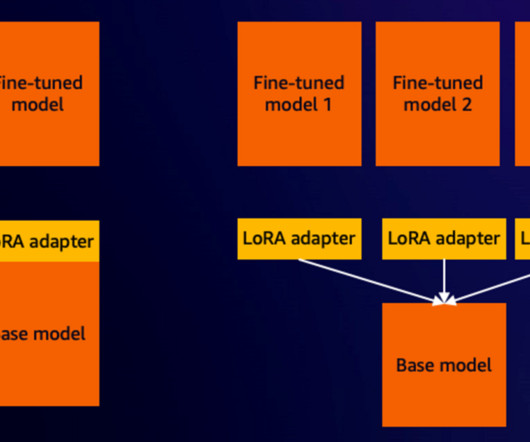
In this post, we showcase fine-tuning a Llama 2 model using a Parameter-Efficient Fine-Tuning (PEFT) method and deploy the fine-tuned model on AWS Inferentia2. We use the AWS Neuron software development kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance.
The higher-level abstracted layer is designed for data scientists with limited AWS expertise, offering a simplified interface that hides complex infrastructure details. For the detailed list of pre-set values, refer to the SDK documentation. Admins and users can also overwrite the defaults using the SDK defaults configuration file.
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. MICR line format).
For example, marketing and software as a service (SaaS) companies can personalize artificial intelligence and machine learning (AI/ML) applications using each of their customer’s images, art style, communication style, and documents to create campaigns and artifacts that represent them. For details, refer to Create an AWS account.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. This feature is only supported when using inference components. dkr.ecr.amazonaws.com/huggingface-pytorch-tgi-inference:2.4.0-tgi2.4.0-gpu-py311-cu124-ubuntu22.04-v2.0",
These longer sequence lengths allow models to better understand long-range dependencies in text, generate more globally coherent outputs, and handle tasks requiring analysis of lengthy documents. More details about FP8 can be found at FP8 Formats For DeepLearning. supports the Llama 3.1 (and Request a Service Quota for 1x p4d.24xlarge
Source: [link] This article describes a solution for a generative AI resume screener that got us 3rd place at DataRobot & AWS Hackathon 2023. You can also set the environment variables on the notebook instance for things like AWS access key etc. Source: author’s screenshot on AWS We used Anthropic Claude 2 in our solution.
When we launched LLM-as-a-judge (LLMaJ) and Retrieval Augmented Generation (RAG) evaluation capabilities in public preview at AWS re:Invent 2024 , customers used them to assess their foundation models (FMs) and generative AI applications, but asked for more flexibility beyond Amazon Bedrock models and knowledge bases.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0 on AWS PyTorch2.0
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
This intuitive platform enables the rapid development of AI-powered solutions such as conversational interfaces, document summarization tools, and content generation apps through a drag-and-drop interface. The IDP solution uses the power of LLMs to automate tedious document-centric processes, freeing up your team for higher-value work.
AWS and NVIDIA have come together to make this vision a reality. AWS, NVIDIA, and other partners build applications and solutions to make healthcare more accessible, affordable, and efficient by accelerating cloud connectivity of enterprise imaging. Metadata contains all DICOM attributes in a JSON document.
The size of the machine learning (ML) models––large language models ( LLMs ) and foundation models ( FMs )–– is growing fast year-over-year , and these models need faster and more powerful accelerators, especially for generative AI. With AWS Inferentia1, customers saw up to 2.3x With AWS Inferentia1, customers saw up to 2.3x
We’re thrilled to announce an expanded collaboration between AWS and Hugging Face to accelerate the training, fine-tuning, and deployment of large language and vision models used to create generative AI applications. AWS has a deep history of innovation in generative AI. Or they can self-manage on Amazon EC2.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. Zeta’s AI innovation is powered by a proprietary machine learning operations (MLOps) system, developed in-house.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture. im', 0.08224299065420558), ('jun 23.
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Set up permissions that allows your AWS account to access Amazon Fraud Detector.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
Manually identifying all mentions of specific types of information in documents is extremely time-consuming and labor-intensive. Some examples include extracting players and positions in an NFL game summary, products mentioned in an AWS keynote transcript, or key names from an article on a favorite tech company.
For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information. These PDFs will serve as the source for generating document chunks. Open SageMaker Studio. Test the deployed model.
The protocol between researchers and engineers is reduced to pull request reviews, eliminating the need for circulating documents or holding alignment meetings. We use AWS Fargate to run CPU inferences and other supporting components, usually alongside a comprehensive frontend API. No one writes any code manually.
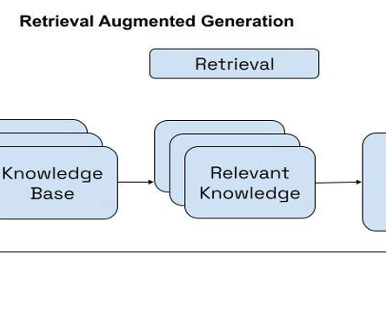
Workflow of RAG Orchestration The RAG orchestration generally consists of two steps: Retrieval – RAG fetches relevant documents from an external data source using the generated search queries. When presented with the search queries, the RAG-based application searches the data source for relevant documents or passages.
NIM is available as a paid offering as part of the NVIDIA AI Enterprise software subscription available on AWS Marketplace. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. Qing Lan is a Software Development Engineer in AWS.
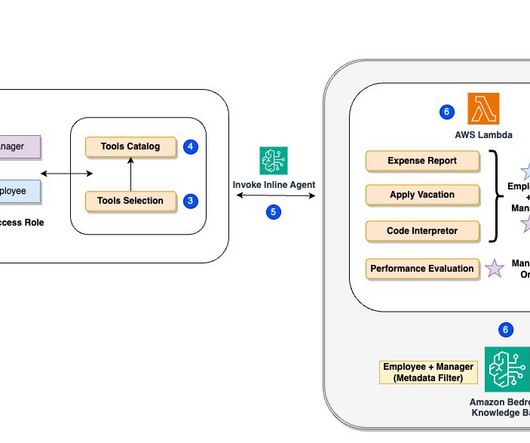
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. AWS Lambda functions for executing specific actions (such as submitting vacation requests or expense reports). Nitin Eusebius is a Sr.
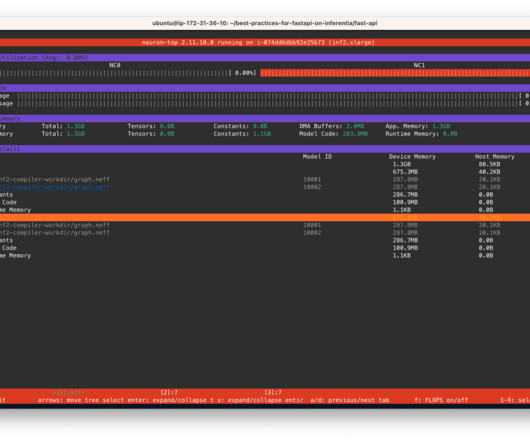
When deploying DeepLearning models at scale, it is crucial to effectively utilize the underlying hardware to maximize performance and cost benefits. In this post we walk you through the process of deploying FastAPI model servers on AWS Inferentia devices (found on Amazon EC2 Inf1 and Amazon EC Inf2 instances).
Use Amazon Sagemaker to add ML predictions in Amazon QuickSight Amazon QuickSight, the AWS BI tool, now has the capability to call Machine Learning models. Amazon Comprehend launches real-time classification Amazon Comprehend is a service which uses Natural Language Processing (NLP) to examine documents.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content