This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Neuron is the SDK used to run deeplearning workloads on Trainium and Inferentia based instances. AWS AI chips, Trainium and Inferentia, enable you to build and deploy generative AI models at higher performance and lower cost. To get started, see AWS Inferentia and AWS Trainium Monitoring.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
AWS), an Amazon.com, Inc. company (NASDAQ: AMZN), today announced the AWS Generative AI Innovation Center, a new program to help customers successfully build and deploy generative artificial intelligence (AI) solutions. Amazon Web Services, Inc.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). It uses deeplearning to convert audio to text quickly and accurately. To address this, Intact turned to AI and speech-to-text technology to unlock insights from calls and improve customer service.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWSDeepLearning AMIs) and Neuron DLCs (AWSDeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. PyTorch 1.13, Transformers NeuronX, and TensorFlow 2.10.
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. Admins and users can also overwrite the defaults using the SDK defaults configuration file.
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Today, we’ll explore why Amazon’s cloud-based machine learning services could be your perfect starting point for building AI-powered applications.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. This year, learn about LLMOps, not just MLOps! are the sessions dedicated to AWS DeepRacer !
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. SageMaker Processing provisions cluster resources for you to run city-, country-, or continent-scale geospatial ML workloads.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Programming Languages: Python (most widely used in AI/ML) R, Java, or C++ (optional but useful) 2.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. Unlocking high-performance and cost-effective inference using AWS Inferentia As retailers look to scale operations, cost of A-POPs becomes a consideration.
Challenges in deploying advanced ML models in healthcare Rad AI, being an AI-first company, integrates machine learning (ML) models across various functions—from product development to customer success, from novel research to internal applications. Rad AI’s ML organization tackles this challenge on two fronts.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
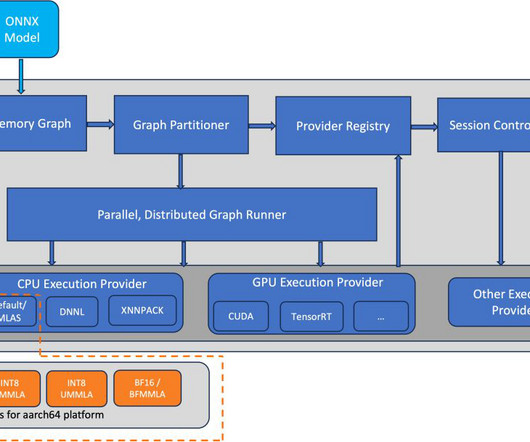
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
For example, marketing and software as a service (SaaS) companies can personalize artificial intelligence and machine learning (AI/ML) applications using each of their customer’s images, art style, communication style, and documents to create campaigns and artifacts that represent them. For details, refer to Create an AWS account.
Amazon Rekognition people pathing is a machine learning (ML)–based capability of Amazon Rekognition Video that users can use to understand where, when, and how each person is moving in a video. Example code The following code example is a Python script that can be used as an AWS Lambda function or as part of your processing pipeline.
JupyterLab applications flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows. AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. samples/2003.10304/page_0.png'
It’s one of the prerequisite tasks to prepare training data to train a deeplearning model. Specifically, for deeplearning-based autonomous vehicle (AV) and Advanced Driver Assistance Systems (ADAS), there is a need to label complex multi-modal data from scratch, including synchronized LiDAR, RADAR, and multi-camera streams.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0 DLAMI + DLC.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. supports the Llama 3.1 (and and prior Llama models), Mixtral, and Mistral.
In this post, we showcase fine-tuning a Llama 2 model using a Parameter-Efficient Fine-Tuning (PEFT) method and deploy the fine-tuned model on AWS Inferentia2. We use the AWS Neuron software development kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance.
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS).
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. Deploy traditional models to SageMaker endpoints In the following examples, we showcase how to use ModelBuilder to deploy traditional ML models.
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
Key Skills: Mastery in machine learning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Stanford AI Lab recommends proficiency in deeplearning, especially if working in experimental or cutting-edge areas.
In order to improve our equipment reliability, we partnered with the Amazon Machine Learning Solutions Lab to develop a custom machine learning (ML) model capable of predicting equipment issues prior to failure. We first highlight how we use AWS Glue for highly parallel data processing.
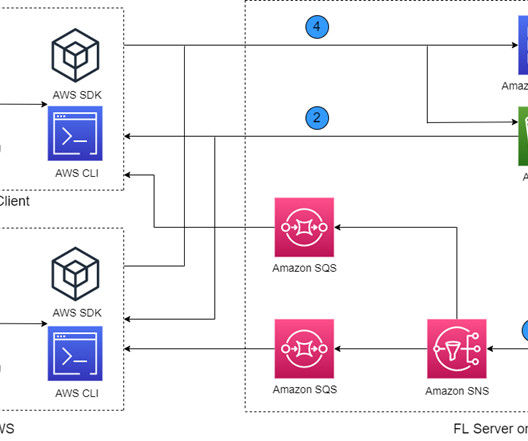
Machine learning (ML), especially deeplearning, requires a large amount of data for improving model performance. Customers often need to train a model with data from different regions, organizations, or AWS accounts. Existing partner open-source FL solutions on AWS include FedML and NVIDIA FLARE.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. Store your Snowflake account credentials in AWS Secrets Manager.
We’re thrilled to announce an expanded collaboration between AWS and Hugging Face to accelerate the training, fine-tuning, and deployment of large language and vision models used to create generative AI applications. AWS has a deep history of innovation in generative AI. Or they can self-manage on Amazon EC2.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deeplearning container (DLC). It’s easier to use, more suitable for machine learning (ML) researchers, and hence is the default mode.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deeplearning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 2048 256 10.4
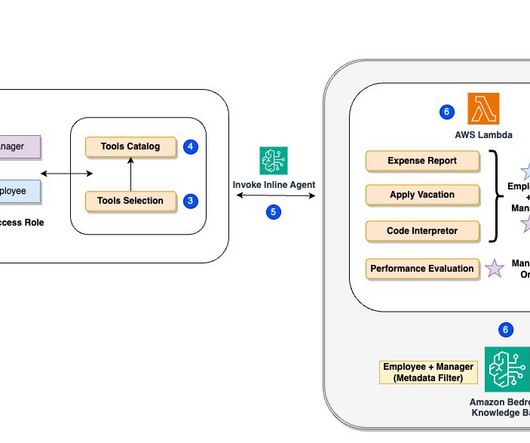
AWS Lambda functions for executing specific actions (such as submitting vacation requests or expense reports). With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Maira Ladeira Tanke is a Senior Generative AI Data Scientist at AWS. Nitin Eusebius is a Sr.
Source: [link] This article describes a solution for a generative AI resume screener that got us 3rd place at DataRobot & AWS Hackathon 2023. You can also set the environment variables on the notebook instance for things like AWS access key etc. Source: author’s screenshot on AWS We used Anthropic Claude 2 in our solution.
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. Additionally, we discuss how to handle integrations with AWS Lambda and Amazon CloudWatch after enabling Global Resiliency. We walk through the instructions to replicate the bot later in this post.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content