This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
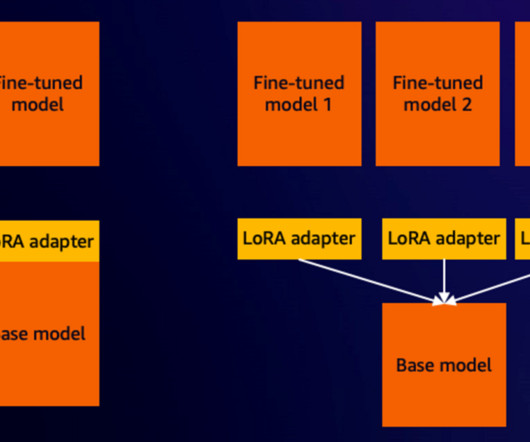
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
Amazon SageMaker has redesigned its Python SDK to provide a unified object-oriented interface that makes it straightforward to interact with SageMaker services. The higher-level abstracted layer is designed for data scientists with limited AWS expertise, offering a simplified interface that hides complex infrastructure details.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
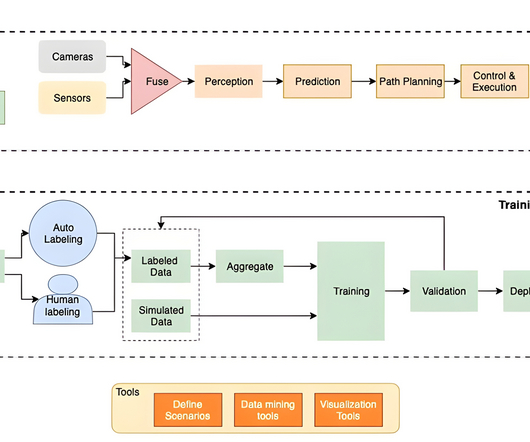
Example code The following code example is a Python script that can be used as an AWS Lambda function or as part of your processing pipeline. Here’s a high-level breakdown of how the Python script is executed: Load the YOLOv9 model – This model is used for detecting objects in each frame. pip install opencv-python ultralytics !pip
We explore two approaches: using the SageMaker Python SDK for programmatic implementation, and using the Amazon SageMaker Studio UI for a more visual, interactive experience. In this post, we walked through the step-by-step process of implementing this feature through both the SageMaker Python SDK and SageMaker Studio UI.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Today, we’ll explore why Amazon’s cloud-based machine learning services could be your perfect starting point for building AI-powered applications.
Key Skills: Mastery in machine learning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods. Stanford AI Lab recommends proficiency in deeplearning, especially if working in experimental or cutting-edge areas.
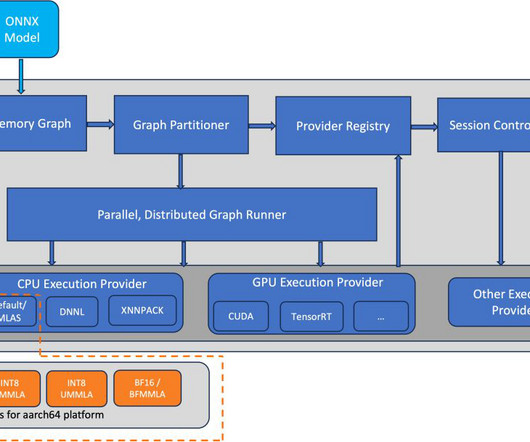
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
70B through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries. Adriana Simmons is a Senior Product Marketing Manager at AWS.
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Programming Languages: Python (most widely used in AI/ML) R, Java, or C++ (optional but useful) 2.
Photo by Marius Masalar on Unsplash Deeplearning. A subset of machine learning utilizing multilayered neural networks, otherwise known as deep neural networks. If you’re getting started with deeplearning, you’ll find yourself overwhelmed with the amount of frameworks. In TensorFlow 2.0,
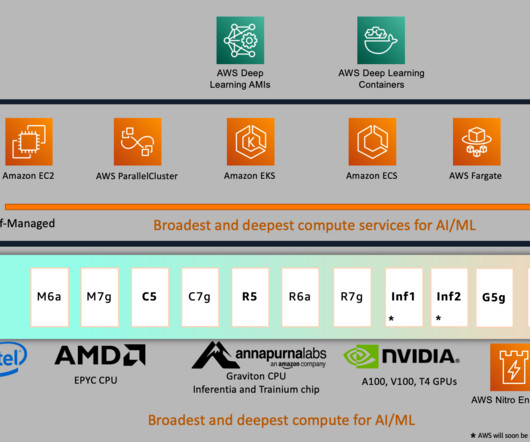
Prime Air (our drones) and the computer vision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deeplearning. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
In this post, we showcase fine-tuning a Llama 2 model using a Parameter-Efficient Fine-Tuning (PEFT) method and deploy the fine-tuned model on AWS Inferentia2. We use the AWS Neuron software development kit (SDK) to access the AWS Inferentia2 device and benefit from its high performance.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
AWS optimized the PyTorch torch.compile feature for AWS Graviton3 processors. the optimizations are available in torch Python wheels and AWS Graviton PyTorch deeplearning container (DLC). The goal for the AWS Graviton team was to optimize torch.compile backend for Graviton3 processors.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. Access to accelerated instances (GPUs) for hosting the LLMs.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. On SageMaker, Triton offers a comprehensive serving stack with support for various backends, including TensorRT, PyTorch, Python, and more.
When we launched LLM-as-a-judge (LLMaJ) and Retrieval Augmented Generation (RAG) evaluation capabilities in public preview at AWS re:Invent 2024 , customers used them to assess their foundation models (FMs) and generative AI applications, but asked for more flexibility beyond Amazon Bedrock models and knowledge bases.
AWS, Arm, Meta and others helped optimize the performance of PyTorch 2.0 As a result, we are delighted to announce that AWS Graviton-based instance inference performance for PyTorch 2.0 times the speed for BERT, making Graviton-based instances the fastest compute optimized instances on AWS for these models. is up to 3.5
Source: [link] This article describes a solution for a generative AI resume screener that got us 3rd place at DataRobot & AWS Hackathon 2023. You can also set the environment variables on the notebook instance for things like AWS access key etc. Source: author’s screenshot on AWS We used Anthropic Claude 2 in our solution.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. Prerequisites To follow along, familiarity with core AWS services such as Amazon EC2 and Amazon ECS is implied.
AWS has been innovating with purpose-built chips to address the growing need for powerful, efficient, and cost-effective compute hardware. You can use ml.trn1 and ml.inf2 compatible AWSDeepLearning Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and large model inference (LMI) to easily get started.
We explained in a previous post how you can use Amazon SageMaker deeplearning containers (DLCs) to deploy these kinds of large models using a GPU-based instance. In this post, we take the same approach but host the model on AWS Inferentia2. For benchmark performance figures, refer to AWS Neuron Performance.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0 on AWS PyTorch2.0
AWS and NVIDIA have come together to make this vision a reality. AWS, NVIDIA, and other partners build applications and solutions to make healthcare more accessible, affordable, and efficient by accelerating cloud connectivity of enterprise imaging. AHI provides API access to ImageSet metadata and ImageFrames.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
The size of the machine learning (ML) models––large language models ( LLMs ) and foundation models ( FMs )–– is growing fast year-over-year , and these models need faster and more powerful accelerators, especially for generative AI. With AWS Inferentia1, customers saw up to 2.3x With AWS Inferentia1, customers saw up to 2.3x
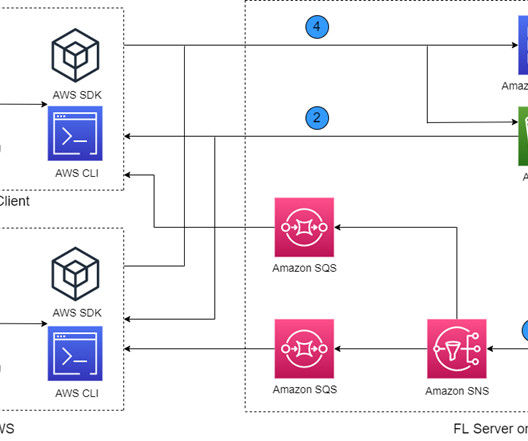
Machine learning (ML), especially deeplearning, requires a large amount of data for improving model performance. Customers often need to train a model with data from different regions, organizations, or AWS accounts. Federated learning (FL) is a distributed ML approach that trains ML models on distributed datasets.
Home Table of Contents Introduction to GitHub Actions for Python Projects Introduction What Is CICD? For Python projects, CI/CD pipelines ensure that your code is consistently integrated and delivered with high quality and reliability. Git is the most commonly used VCS for Python projects, enabling collaboration and version tracking.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. Zeta’s AI innovation is powered by a proprietary machine learning operations (MLOps) system, developed in-house.
You can use the SageMaker Python SDK to trigger a job with data parallelism with minimal modifications to the training script. Data parallelism supports popular deeplearning frameworks PyTorch, PyTorch Lightening, TensorFlow, and Hugging Face Transformers.
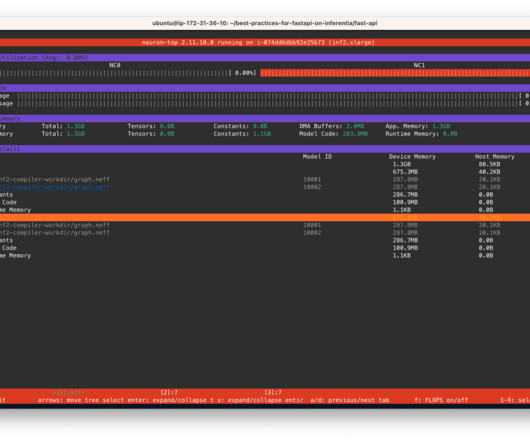
When deploying DeepLearning models at scale, it is crucial to effectively utilize the underlying hardware to maximize performance and cost benefits. In this post we walk you through the process of deploying FastAPI model servers on AWS Inferentia devices (found on Amazon EC2 Inf1 and Amazon EC Inf2 instances).
To achieve this, the Rufus team is using multiple AWS services and AWS AI chips, AWS Trainium and AWS Inferentia. Inferentia and Trainium are purpose-built chips developed by AWS that accelerate deeplearning workloads with high performance and lower overall costs.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI). Solutions Architect at AWS. Varun Mehta is a Sr.
Our innovative new A-POPs (or vending machines) deliver enhanced customer experiences at ten times lower cost because of the performance and cost advantages AWS Inferentia delivers. Unlocking high-performance and cost-effective inference using AWS Inferentia As retailers look to scale operations, cost of A-POPs becomes a consideration.
In this post, we show how you can run Stable Diffusion models and achieve high performance at the lowest cost in Amazon Elastic Compute Cloud (Amazon EC2) using Amazon EC2 Inf2 instances powered by AWS Inferentia2. versions on AWS Inferentia2 cost-effectively. You can run both Stable Diffusion 2.1 The Stable Diffusion 2.1
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content