This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
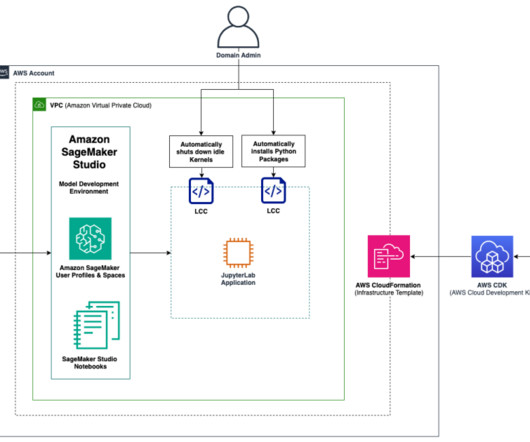
Amazon SageMaker Studio is the first integrated development environment (IDE) purposefully designed to accelerate end-to-end machine learning (ML) development. These automations can greatly decrease overhead related to ML project setup, facilitate technical consistency, and save costs related to running idle instances.
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks.
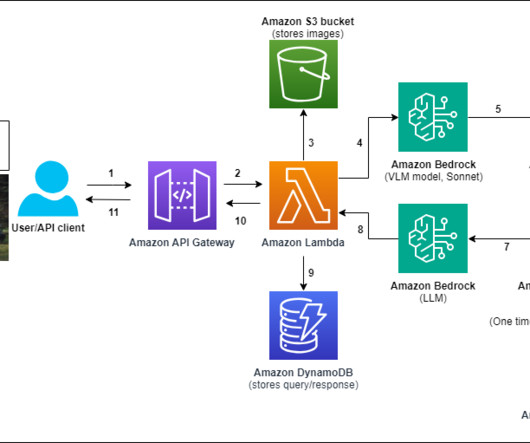
In this post, we show how to create a multimodal chat assistant on Amazon Web Services (AWS) using Amazon Bedrock models, where users can submit images and questions, and text responses will be sourced from a closed set of proprietary documents. For this post, we recommend activating these models in the us-east-1 or us-west-2 AWS Region.
No definite pneumonia. This indicates that the key findings from the radiology report are the presence of a moderate hiatal hernia and the absence of any definite pneumonia. Data ScientistGenerative AI, Amazon Bedrock, where he contributes to cutting edge innovations in foundational models and generative AI applications at AWS.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. and above. Any version above 2.231.0
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. Our innovative new A-POPs (or vending machines) deliver enhanced customer experiences at ten times lower cost because of the performance and cost advantages AWS Inferentia delivers.
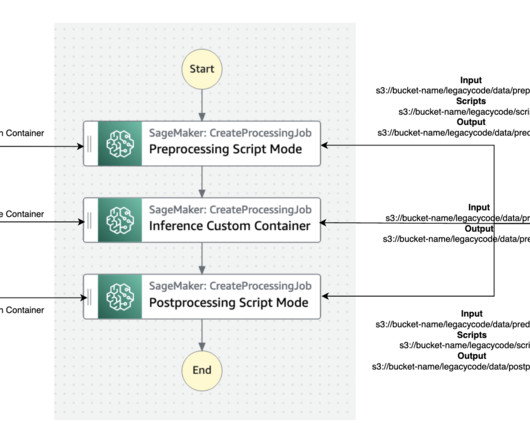
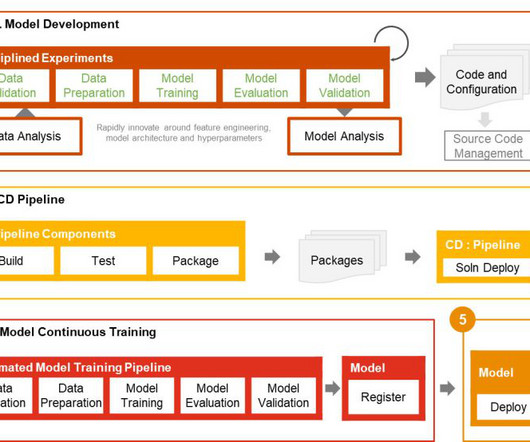
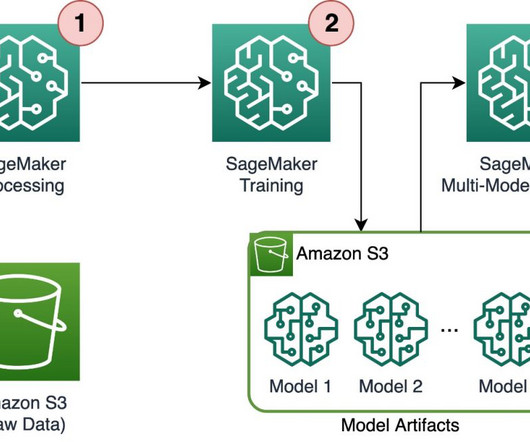
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. This entire workflow is shown in the following solution diagram.
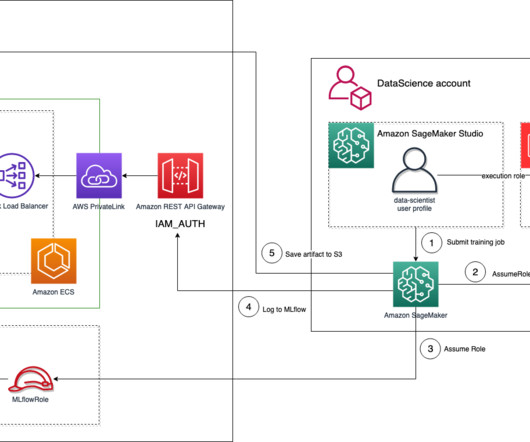
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. The data scientist is responsible for moving the code into SageMaker, either manually or by cloning it from a code repository such as AWS CodeCommit.
By caching the system prompts and complex tool definitions, the time to process each step in the agentic flow can be reduced. Amazon Web Services (AWS) offers AWS Network Firewall, a stateful, managed network firewall that includes intrusion detection and prevention (IDP) for your Amazon Virtual Private Cloud (VPC)."nn[2]
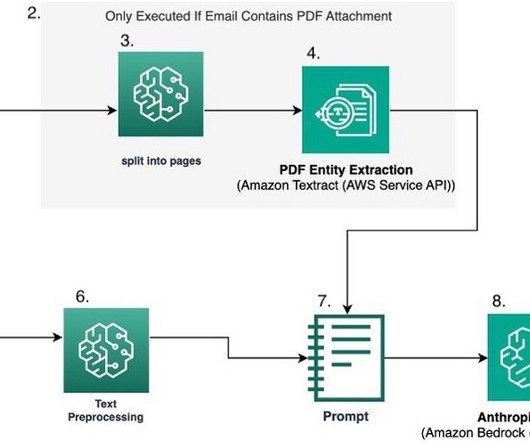
Extraction – A document schema definition is used to formulate the prompt and documents are embedded into the prompt and sent to Amazon Bedrock for extraction. To find the URL, open the AWS Management Console for SageMaker and choose Ground Truth and then Labeling workforces in the navigation pane. edit cdk.json Deploy the application.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
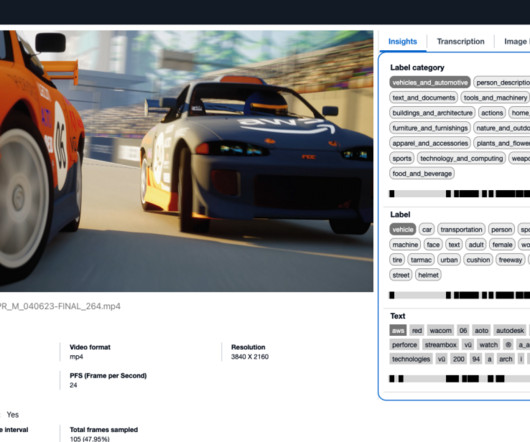
In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes. This solution, powered by AWS AI and generative AI services, meets these needs.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
What Zeta has accomplished in AI/ML In the fast-evolving landscape of digital marketing, Zeta Global stands out with its groundbreaking advancements in artificial intelligence. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Running machine learning (ML) workloads with containers is becoming a common practice. What you get is an ML development environment that is consistent and portable. In this post, we show you how to run your ML training jobs in a container using Amazon ECS to deploy, manage, and scale your ML workload.
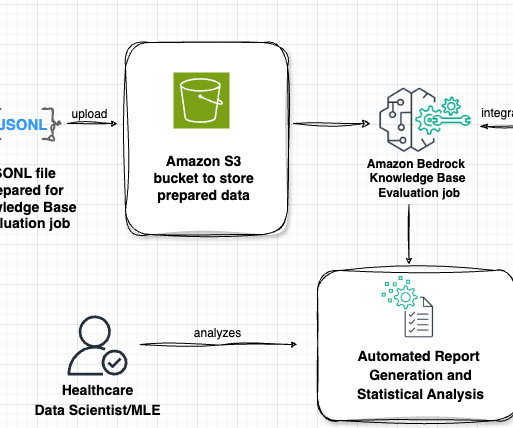
At AWS, we are committed to developing AI responsibly , taking a people-centric approach that prioritizes education, science, and our customers, integrating responsible AI across the end-to-end AI lifecycle. For human-in-the-loop evaluation, which can be done by either AWS managed or customer managed teams, you must bring your own dataset.
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
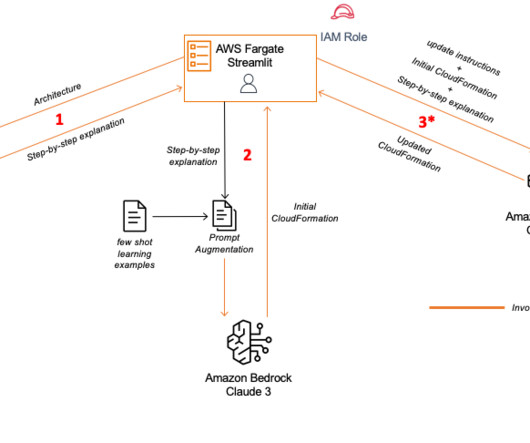
Architecting specific AWS Cloud solutions involves creating diagrams that show relationships and interactions between different services. Instead of building the code manually, you can use Anthropic’s Claude 3’s image analysis capabilities to generate AWS CloudFormation templates by passing an architecture diagram as input.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. This type of data is often used in ML and artificial intelligence applications. As always, AWS welcomes feedback.
At AWS, we are transforming our seller and customer journeys by using generative artificial intelligence (AI) across the sales lifecycle. It will be able to answer questions, generate content, and facilitate bidirectional interactions, all while continuously using internal AWS and external data to deliver timely, personalized insights.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
This is where AWS and generative AI can revolutionize the way we plan and prepare for our next adventure. This innovative service goes beyond traditional trip planning methods, offering real-time interaction through a chat-based interface and maintaining scalability, reliability, and data security through AWS native services.
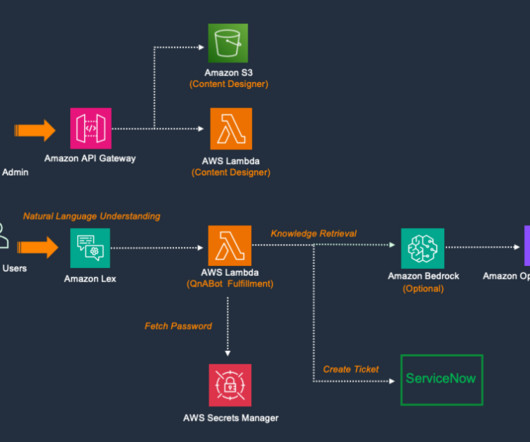
QnABot on AWS is an open source solution built using AWS native services like Amazon Lex , Amazon OpenSearch Service , AWS Lambda , Amazon Transcribe , and Amazon Polly. In this post, we demonstrate how to integrate the QnABot on AWS chatbot solution with ServiceNow. QnABot version 5.4+ Provide a name for the bot.
Increasingly, FMs are completing tasks that were previously solved by supervised learning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. With a serverless solution, AWS provides a managed solution, facilitating lower cost of ownership and reduced complexity of maintenance.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
Prerequisites To build the solution yourself, there are the following prerequisites: You need an AWS account with an AWS Identity and Access Management (IAM) role that has permissions to manage resources created as part of the solution (for example AmazonSageMakerFullAccess and AmazonS3FullAccess ).
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
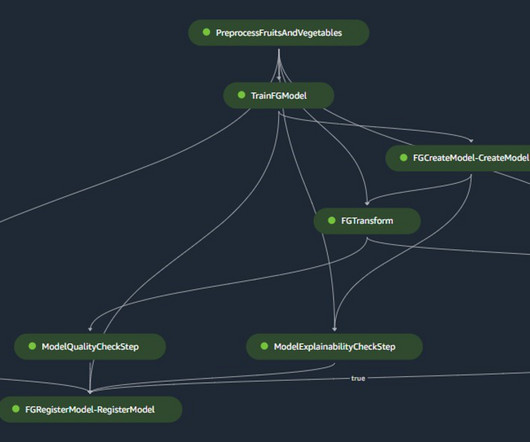
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. This provides a major flexibility advantage over the majority of ML frameworks, which require neural networks to be defined as static objects before runtime.
At AWS, were using the power of models in Amazon Bedrock to drive automation of complex processes that have traditionally been challenging to streamline. The APIs standardized approach to tool definition and function calling provides consistent interaction patterns across different processing stages. Access to the Anthropics Claude 3.5
Since then, TR has achieved many more milestones as its AI products and services are continuously growing in number and variety, supporting legal, tax, accounting, compliance, and news service professionals worldwide, with billions of machine learning (ML) insights generated every year. The challenges. Solution overview.
In this post, we introduce LLM agents and demonstrate how to build and deploy an e-commerce LLM agent using Amazon SageMaker JumpStart and AWS Lambda. To power the LLM agent, we use a Flan-UL2 model deployed as a SageMaker endpoint and use data retrieval tools built with AWS Lambda. helper function definitions.
We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation. One of the most critical aspects of fine-tuning is selecting the right hyperparameters, particularly learning rate multiplier and batch size (see the appendix in this post for definitions).
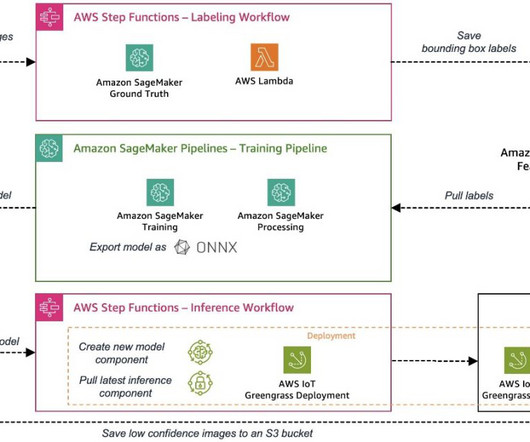
We show you how to use AWS IoT Greengrass to manage model inference at the edge and how to automate the process using AWS Step Functions and other AWS services. AWS IoT Greengrass is an Internet of Things (IoT) open-source edge runtime and cloud service that helps you build, deploy, and manage edge device software.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. What does a modern technology stack for streamlined ML processes look like?
Prerequisites Before you start, make sure you have the following prerequisites in place: Create an AWS account , or sign in to your existing account. Make sure that you have the correct AWS Identity and Access Management (IAM) permissions to use Amazon Bedrock. Configure your AWS credentials. Install Python 3.8 Install pip.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
As machine learning (ML) becomes increasingly prevalent in a wide range of industries, organizations are finding the need to train and serve large numbers of ML models to meet the diverse needs of their customers. Here, the checkpoints need to be saved in a pre-specified location, with the default being /opt/ml/checkpoints.
With Amazon SageMaker , you can manage the whole end-to-end machine learning (ML) lifecycle. It offers many native capabilities to help manage ML workflows aspects, such as experiment tracking, and model governance via the model registry. To automate the infrastructure deployment, we use the AWS Cloud Development Kit (AWS CDK).
The most common techniques used for extractive summarization are term frequency-inverse document frequency (TF-IDF), sentence scoring, text rank algorithm, and supervised machine learning (ML). To learn more about FMEval in AWS and how to use it effectively, refer to Use SageMaker Clarify to evaluate large language models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content