This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
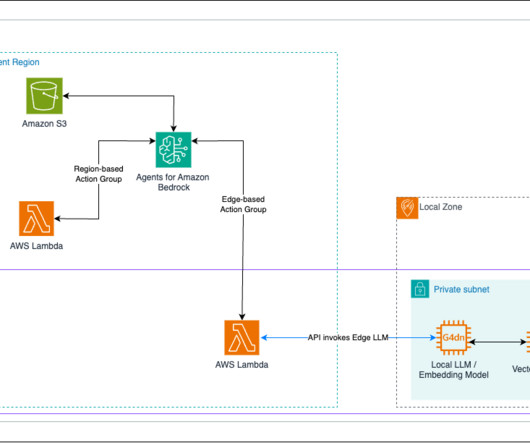
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
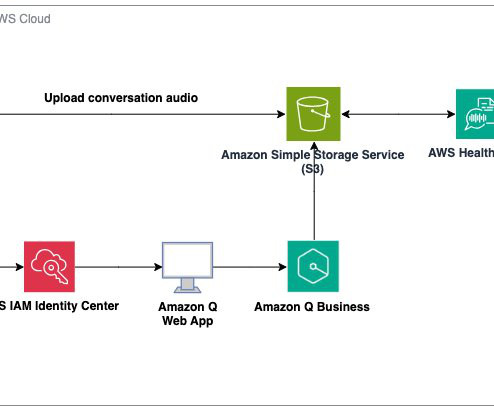
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation.
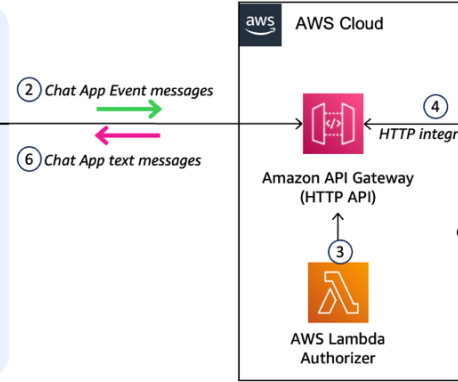
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Amazon Nova Lite demonstrated strong performance across benchmarks, including accuracy for text tasks and video, chart, and document understanding, excelling in VATEX, ChartQA, and DocVQA tests. With an industry-leading output speed of 210 tokens per second, it is ideal for applications requiring rapid responses.
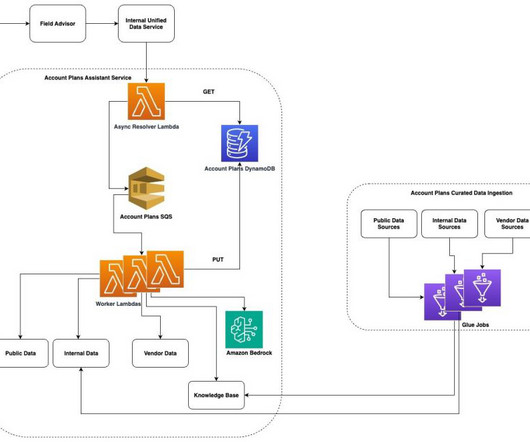
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
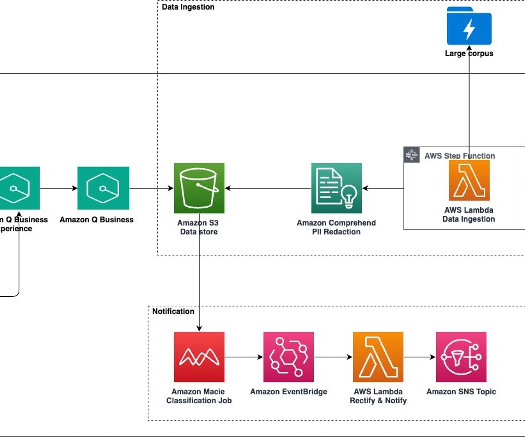
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. Then we introduce the solution deployment using three AWS CloudFormation templates.
The solution offers two TM retrieval modes for users to choose from: vector and document search. When using the Amazon OpenSearch Service adapter (document search), translation unit groupings are parsed and stored into an index dedicated to the uploaded file. This is covered in detail later in the post.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
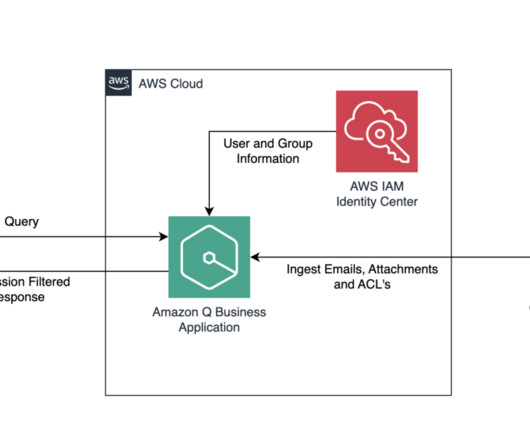
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
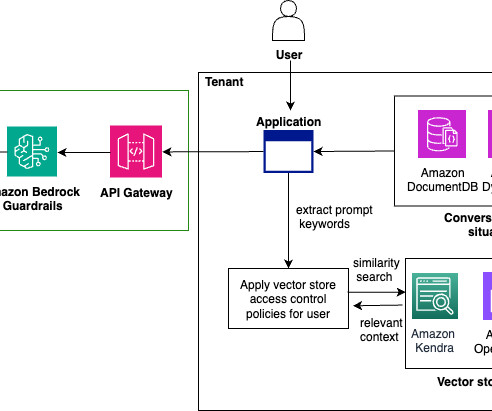
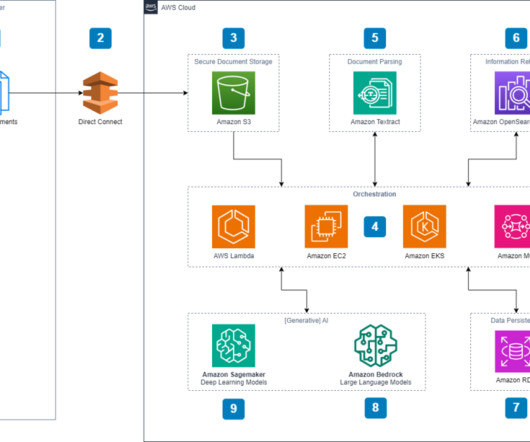
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. On AWS, you can use the fully managed Amazon Bedrock Agents or tools of your choice such as LangChain agents or LlamaIndex agents.
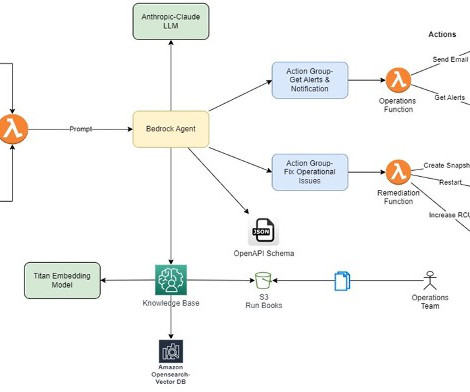
This post presents a comprehensive AIOps solution that combines various AWS services such as Amazon Bedrock , AWS Lambda , and Amazon CloudWatch to create an AI assistant for effective incident management. They are commonly used to document repetitive tasks, troubleshooting steps, and routine maintenance.
A large portion of that information is found in text narratives stored in various document formats such as PDFs, Word files, and HTML pages. Some information is also stored in tables (such as price or product specification tables) embedded in those same document types, CSVs, or spreadsheets.
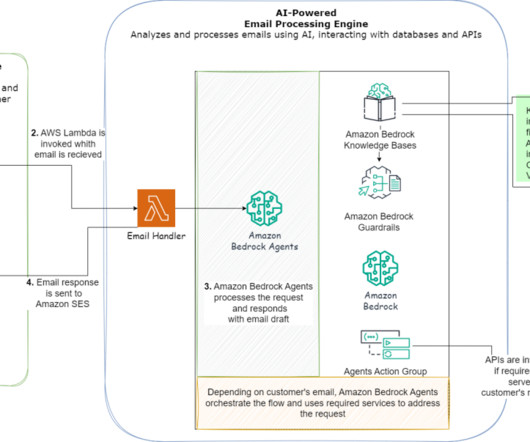
Amazon Bedrock offers a serverless experience so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage infrastructure. The following diagram provides a detailed view of the architecture to enhance email support using generative AI.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. Along the way, it also simplified operations as Octus is an AWS shop more generally.
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI. Some of these tools included AWS Cloud based solutions, such as AWS Lambda and AWS Step Functions.
The market size for multilingual content extraction and the gathering of relevant insights from unstructured documents (such as images, forms, and receipts) for information processing is rapidly increasing. These languages might not be supported out of the box by existing document extraction software.
Introduction S3 is Amazon Web Services cloud-based object storage service (AWS). It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner.
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
dbt helps manage data transformation by enabling teams to deploy analytics code following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. Choose the us-east-1 AWS Region in which to create the stack. Create dbt models in dbt Cloud.
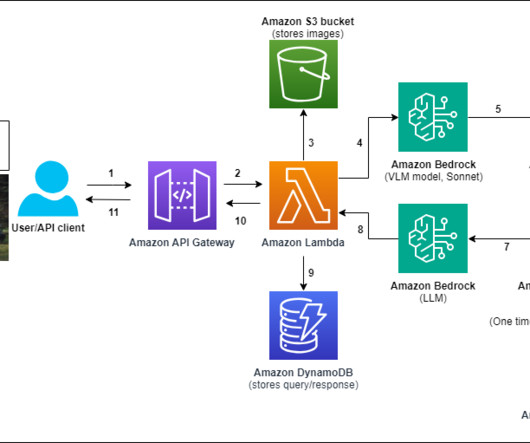
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
At AWS, were using the power of models in Amazon Bedrock to drive automation of complex processes that have traditionally been challenging to streamline. In this post, we focus on one such complex workflow: document processing. The solution uses the FMs tool use capabilities, accessed through the Amazon Bedrock Converse API.
Precise), an Amazon Web Services (AWS) Partner , participated in the AWS Think Big for Small Business Program (TBSB) to expand their AWS capabilities and to grow their business in the public sector. The platform helped the agency digitize and process forms, pictures, and other documents. Precise Software Solutions, Inc.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. sync) pattern, which automatically waits for the completion of asynchronous jobs.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. The Anthropic Claude 3 Haiku model then processes the documents and returns the desired information, streamlining the entire workflow.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
Seamless integration of latest foundation models (FMs), Prompts, Agents, Knowledge Bases, Guardrails, and other AWS services. Prerequisites Before implementing the new capabilities, make sure that you have the following: An AWS account In Amazon Bedrock: Create and test your base prompts for customer service interactions in Prompt Management.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated.
Solution overview This solution uses the Amazon Bedrock Knowledge Bases chat with document feature to analyze and extract key details from your invoices, without needing a knowledge base. Importantly, your document and data are not stored after processing. Make sure your AWS credentials are configured correctly.
We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads. After the model is fine-tuned, you can compile and host the fine-tuned SDXL on Inf2 instances using the AWS Neuron SDK. An Amazon Web Services (AWS) account.
Google Drive supports storing documents such as Emails contain a wealth of information found in different places, such as within the subject of an email, the message content, or even attachments. Types of documents Gmail messages can be sorted and stored inside your email inbox using folders and labels.
By narrowing down the search space to the most relevant documents or chunks, metadata filtering reduces noise and irrelevant information, enabling the LLM to focus on the most relevant content. This approach narrows down the search space to the most relevant documents or passages, reducing noise and irrelevant information.
With this launch, you can now deploy NVIDIAs optimized reranking and embedding models to build, experiment, and responsibly scale your generative AI ideas on AWS. As part of NVIDIA AI Enterprise available in AWS Marketplace , NIM is a set of user-friendly microservices designed to streamline and accelerate the deployment of generative AI.
Click here to open the AWS console and follow along. To use one of these models, AWS offers the fully managed service Amazon Bedrock. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. Let’s understand how these AWS services are integrated in detail.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content